 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOEVO: Co-Evolutionary Framework for Joint Functional Correctness and PPA Optimization in LLM-Based RTL Generation
Apr 16, 2026LLM-based RTL code generation methods increasingly target both functional correctness and PPA quality, yet existing approaches universally decouple the two objectives, optimizing PPA only after correctness is fully achieved. Whether through sequential multi-agent pipelines, evolutionary search with binary correctness gates, or hierarchical reward dependencies, partially correct but architecturally promising candidates are systematically discarded. Moreover, existing methods reduce the multi-objective PPA space to a single scalar fitness, obscuring the trade-offs among area, delay, and power. To address these limitations, we propose COEVO, a co-evolutionary framework that unifies correctness and PPA optimization within a single evolutionary loop. COEVO formulates correctness as a continuous co-optimization dimension alongside area, delay, and power, enabled by an enhanced testbench that provides fine-grained scoring and detailed diagnostic feedback. An adaptive correctness gate with annealing allows PPA-promising but partially correct candidates to guide the search toward jointly optimal solutions. To preserve the full PPA trade-off structure, COEVO employs four-dimensional Pareto-based non-dominated sorting with configurable intra-level sorting, replacing scalar fitness without manual weight tuning. Evaluated on VerilogEval 2.0 and RTLLM 2.0, COEVO achieves 97.5\% and 94.5\% Pass@1 with GPT-5.4-mini, surpassing all agentic baselines across four LLM backbones, while attaining the best PPA on 43 out of 49 synthesizable RTLLM designs.
OptiML: An End-to-End Framework for Program Synthesis and CUDA Kernel Optimization
Feb 12, 2026Generating high-performance CUDA kernels remains challenging due to the need to navigate a combinatorial space of low-level transformations under noisy and expensive hardware feedback. Although large language models can synthesize functionally correct CUDA code, achieving competitive performance requires systematic exploration and verification of optimization choices. We present OptiML, an end-to-end framework that maps either natural-language intent or input CUDA code to performance-optimized CUDA kernels by formulating kernel optimization as search under verification. OptiML consists of two decoupled stages. When the input is natural language, a Mixture-of-Thoughts generator (OptiML-G) acts as a proposal policy over kernel implementation strategies, producing an initial executable program. A search-based optimizer (OptiML-X) then refines either synthesized or user-provided kernels using Monte Carlo Tree Search over LLM-driven edits, guided by a hardware-aware reward derived from profiler feedback. Each candidate transformation is compiled, verified, and profiled with Nsight Compute, and evaluated by a composite objective that combines runtime with hardware bottleneck proxies and guardrails against regressions. We evaluate OptiML in both synthesis-and-optimize and optimization-only settings on a diverse suite of CUDA kernels. Results show that OptiML consistently discovers verified performance improvements over strong LLM baselines and produces interpretable optimization trajectories grounded in profiler evidence.
Auditing Multi-Agent LLM Reasoning Trees Outperforms Majority Vote and LLM-as-Judge
Feb 10, 2026Multi-agent systems (MAS) can substantially extend the reasoning capacity of large language models (LLMs), yet most frameworks still aggregate agent outputs with majority voting. This heuristic discards the evidential structure of reasoning traces and is brittle under the confabulation consensus, where agents share correlated biases and converge on the same incorrect rationale. We introduce AgentAuditor, which replaces voting with a path search over a Reasoning Tree that explicitly represents agreements and divergences among agent traces. AgentAuditor resolves conflicts by comparing reasoning branches at critical divergence points, turning global adjudication into efficient, localized verification. We further propose Anti-Consensus Preference Optimization (ACPO), which trains the adjudicator on majority-failure cases and rewards evidence-based minority selections over popular errors. AgentAuditor is agnostic to MAS setting, and we find across 5 popular settings that it yields up to 5% absolute accuracy improvement over a majority vote, and up to 3% over using LLM-as-Judge.
FITMM: Adaptive Frequency-Aware Multimodal Recommendation via Information-Theoretic Representation Learning
Jan 30, 2026Multimodal recommendation aims to enhance user preference modeling by leveraging rich item content such as images and text. Yet dominant systems fuse modalities in the spatial domain, obscuring the frequency structure of signals and amplifying misalignment and redundancy. We adopt a spectral information-theoretic view and show that, under an orthogonal transform that approximately block-diagonalizes bandwise covariances, the Gaussian Information Bottleneck objective decouples across frequency bands, providing a principled basis for separate-then-fuse paradigm. Building on this foundation, we propose FITMM, a Frequency-aware Information-Theoretic framework for multimodal recommendation. FITMM constructs graph-enhanced item representations, performs modality-wise spectral decomposition to obtain orthogonal bands, and forms lightweight within-band multimodal components. A residual, task-adaptive gate aggregates bands into the final representation. To control redundancy and improve generalization, we regularize training with a frequency-domain IB term that allocates capacity across bands (Wiener-like shrinkage with shut-off of weak bands). We further introduce a cross-modal spectral consistency loss that aligns modalities within each band. The model is jointly optimized with the standard recommendation loss. Extensive experiments on three real-world datasets demonstrate that FITMM consistently and significantly outperforms advanced baselines.
ERMoE: Eigen-Reparameterized Mixture-of-Experts for Stable Routing and Interpretable Specialization
Nov 14, 2025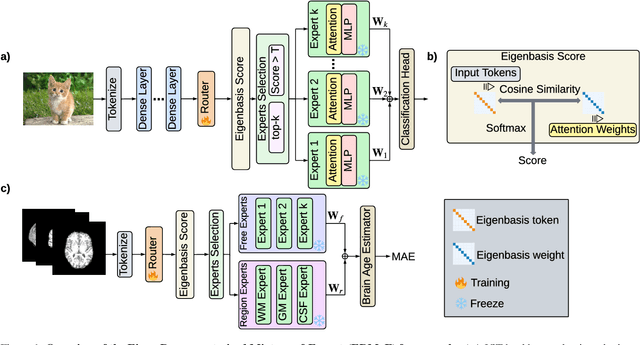
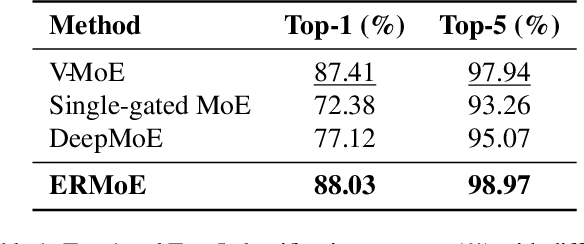
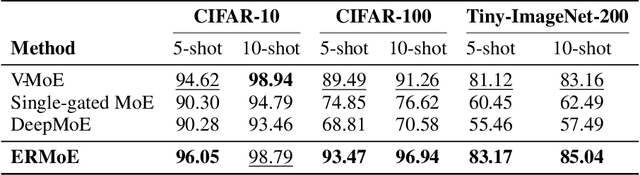
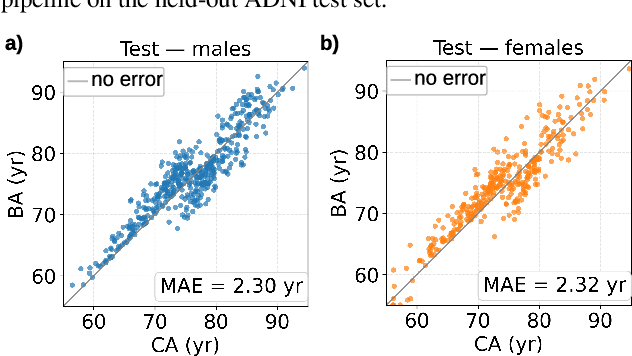
Mixture-of-Experts (MoE) architectures expand model capacity by sparsely activating experts but face two core challenges: misalignment between router logits and each expert's internal structure leads to unstable routing and expert underutilization, and load imbalances create straggler bottlenecks. Standard solutions, such as auxiliary load-balancing losses, can reduce load disparities but often weaken expert specialization and hurt downstream performance. To address these issues, we propose ERMoE, a sparse MoE transformer that reparameterizes each expert in a learned orthonormal eigenbasis and replaces learned gating logits with an "Eigenbasis Score", defined as the cosine similarity between input features and an expert's basis. This content-aware routing ties token assignments directly to experts' representation spaces, stabilizing utilization and promoting interpretable specialization without sacrificing sparsity. Crucially, ERMoE removes the need for explicit balancing losses and avoids the interfering gradients they introduce. We show that ERMoE achieves state-of-the-art accuracy on ImageNet classification and cross-modal image-text retrieval benchmarks (e.g., COCO, Flickr30K), while naturally producing flatter expert load distributions. Moreover, a 3D MRI variant (ERMoE-ba) improves brain age prediction accuracy by more than 7\% and yields anatomically interpretable expert specializations. ERMoE thus introduces a new architectural principle for sparse expert models that directly addresses routing instabilities and enables improved performance with scalable, interpretable specialization.
VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation
Oct 31, 2025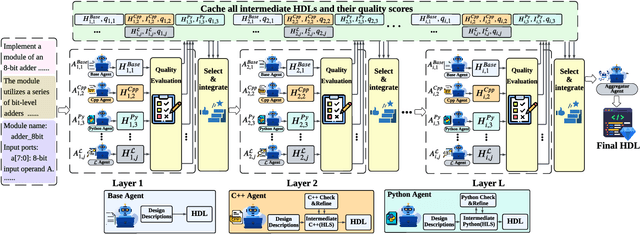
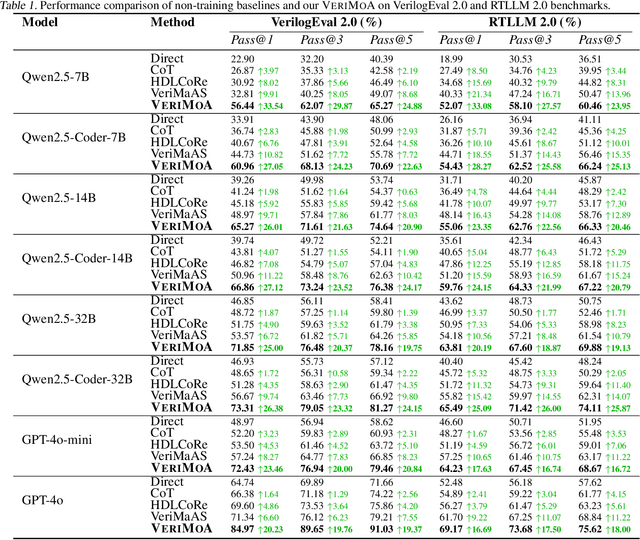
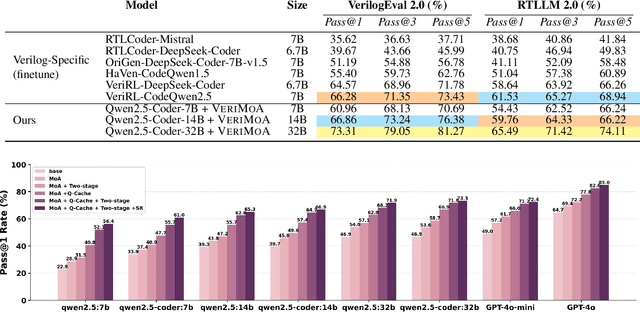
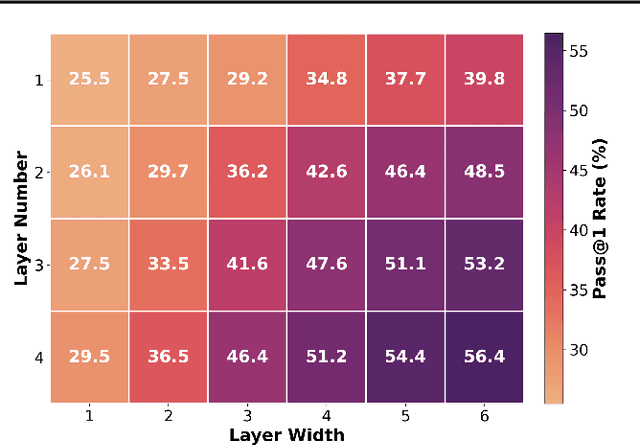
Automation of Register Transfer Level (RTL) design can help developers meet increasing computational demands. Large Language Models (LLMs) show promise for Hardware Description Language (HDL) generation, but face challenges due to limited parametric knowledge and domain-specific constraints. While prompt engineering and fine-tuning have limitations in knowledge coverage and training costs, multi-agent architectures offer a training-free paradigm to enhance reasoning through collaborative generation. However, current multi-agent approaches suffer from two critical deficiencies: susceptibility to noise propagation and constrained reasoning space exploration. We propose VeriMoA, a training-free mixture-of-agents (MoA) framework with two synergistic innovations. First, a quality-guided caching mechanism to maintain all intermediate HDL outputs and enables quality-based ranking and selection across the entire generation process, encouraging knowledge accumulation over layers of reasoning. Second, a multi-path generation strategy that leverages C++ and Python as intermediate representations, decomposing specification-to-HDL translation into two-stage processes that exploit LLM fluency in high-resource languages while promoting solution diversity. Comprehensive experiments on VerilogEval 2.0 and RTLLM 2.0 benchmarks demonstrate that VeriMoA achieves 15--30% improvements in Pass@1 across diverse LLM backbones, especially enabling smaller models to match larger models and fine-tuned alternatives without requiring costly training.
H$^2$GFM: Towards unifying Homogeneity and Heterogeneity on Text-Attributed Graphs
Jun 10, 2025The growing interests and applications of graph learning in diverse domains have propelled the development of a unified model generalizing well across different graphs and tasks, known as the Graph Foundation Model (GFM). Existing research has leveraged text-attributed graphs (TAGs) to tackle the heterogeneity in node features among graphs. However, they primarily focus on homogeneous TAGs (HoTAGs), leaving heterogeneous TAGs (HeTAGs), where multiple types of nodes/edges reside, underexplored. To enhance the capabilities and applications of GFM, we introduce H$^2$GFM, a novel framework designed to generalize across both HoTAGs and HeTAGs. Our model projects diverse meta-relations among graphs under a unified textual space, and employs a context encoding to capture spatial and higher-order semantic relationships. To achieve robust node representations, we propose a novel context-adaptive graph transformer (CGT), effectively capturing information from both context neighbors and their relationships. Furthermore, we employ a mixture of CGT experts to capture the heterogeneity in structural patterns among graph types. Comprehensive experiments on a wide range of HoTAGs and HeTAGs as well as learning scenarios demonstrate the effectiveness of our model.
HDLCoRe: A Training-Free Framework for Mitigating Hallucinations in LLM-Generated HDL
Mar 18, 2025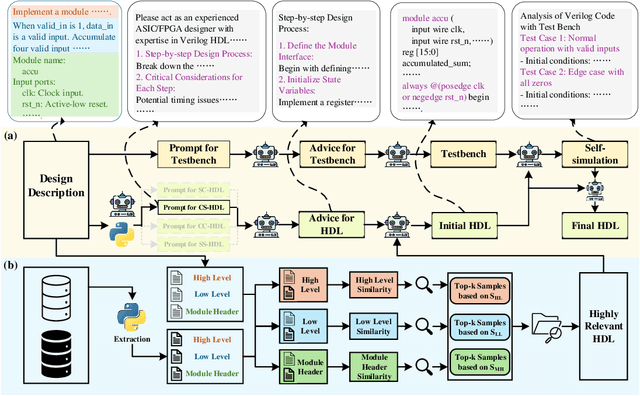



Recent advances in large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, when applied to hardware description languages (HDL), these models exhibit significant limitations due to data scarcity, resulting in hallucinations and incorrect code generation. To address these challenges, we propose HDLCoRe, a training-free framework that enhances LLMs' HDL generation capabilities through prompt engineering techniques and retrieval-augmented generation (RAG). Our approach consists of two main components: (1) an HDL-aware Chain-of-Thought (CoT) prompting technique with self-verification that classifies tasks by complexity and type, incorporates domain-specific knowledge, and guides LLMs through step-by-step self-simulation for error correction; and (2) a two-stage heterogeneous RAG system that addresses formatting inconsistencies through key component extraction and efficiently retrieves relevant HDL examples through sequential filtering and re-ranking. HDLCoRe eliminates the need for model fine-tuning while substantially improving LLMs' HDL generation capabilities. Experimental results demonstrate that our framework achieves superior performance on the RTLLM2.0 benchmark, significantly reducing hallucinations and improving both syntactic and functional correctness.
Network-informed Prompt Engineering against Organized Astroturf Campaigns under Extreme Class Imbalance
Jan 21, 2025Detecting organized political campaigns is of paramount importance in fighting against disinformation on social media. Existing approaches for the identification of such organized actions employ techniques mostly from network science, graph machine learning and natural language processing. Their ultimate goal is to analyze the relationships and interactions (e.g. re-posting) among users and the textual similarities of their posts. Despite their effectiveness in recognizing astroturf campaigns, these methods face significant challenges, notably the class imbalance in available training datasets. To mitigate this issue, recent methods usually resort to data augmentation or increasing the number of positive samples, which may not always be feasible or sufficient in real-world settings. Following a different path, in this paper, we propose a novel framework for identifying astroturf campaigns based solely on large language models (LLMs), introducing a Balanced Retrieval-Augmented Generation (Balanced RAG) component. Our approach first gives both textual information concerning the posts (in our case tweets) and the user interactions of the social network as input to a language model. Then, through prompt engineering and the proposed Balanced RAG method, it effectively detects coordinated disinformation campaigns on X (Twitter). The proposed framework does not require any training or fine-tuning of the language model. Instead, by strategically harnessing the strengths of prompt engineering and Balanced RAG, it facilitates LLMs to overcome the effects of class imbalance and effectively identify coordinated political campaigns. The experimental results demonstrate that by incorporating the proposed prompt engineering and Balanced RAG methods, our framework outperforms the traditional graph-based baselines, achieving 2x-3x improvements in terms of precision, recall and F1 scores.
A structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.