 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA foundation model enpowered by a multi-modal prompt engine for universal seismic geobody interpretation across surveys
Sep 08, 2024



Seismic geobody interpretation is crucial for structural geology studies and various engineering applications. Existing deep learning methods show promise but lack support for multi-modal inputs and struggle to generalize to different geobody types or surveys. We introduce a promptable foundation model for interpreting any geobodies across seismic surveys. This model integrates a pre-trained vision foundation model (VFM) with a sophisticated multi-modal prompt engine. The VFM, pre-trained on massive natural images and fine-tuned on seismic data, provides robust feature extraction for cross-survey generalization. The prompt engine incorporates multi-modal prior information to iteratively refine geobody delineation. Extensive experiments demonstrate the model's superior accuracy, scalability from 2D to 3D, and generalizability to various geobody types, including those unseen during training. To our knowledge, this is the first highly scalable and versatile multi-modal foundation model capable of interpreting any geobodies across surveys while supporting real-time interactions. Our approach establishes a new paradigm for geoscientific data interpretation, with broad potential for transfer to other tasks.
Neuro-Inspired Information-Theoretic Hierarchical Perception for Multimodal Learning
Apr 15, 2024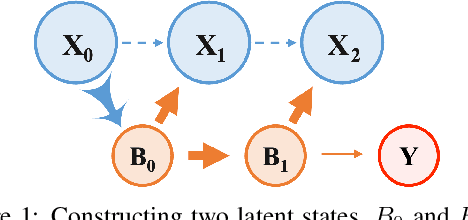
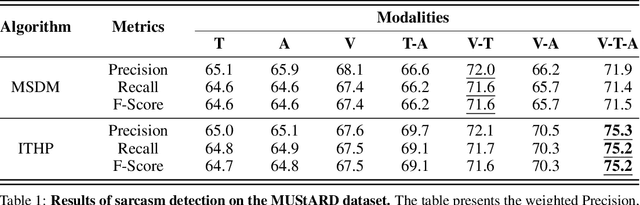
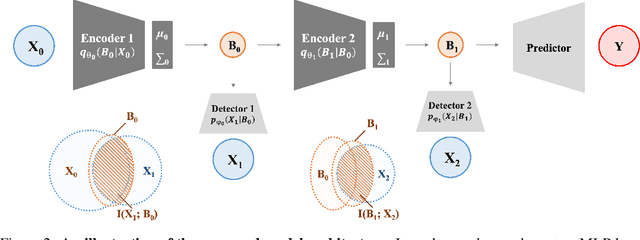

Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world in autonomous systems and cyber-physical systems. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Different from most traditional fusion models that incorporate all modalities identically in neural networks, our model designates a prime modality and regards the remaining modalities as detectors in the information pathway, serving to distill the flow of information. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of multimodal representation learning. Experimental evaluations on the MUStARD, CMU-MOSI, and CMU-MOSEI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks. Remarkably, on the CMU-MOSI dataset, ITHP surpasses human-level performance in the multimodal sentiment binary classification task across all evaluation metrics (i.e., Binary Accuracy, F1 Score, Mean Absolute Error, and Pearson Correlation).
Exploring Neuron Interactions and Emergence in LLMs: From the Multifractal Analysis Perspective
Feb 14, 2024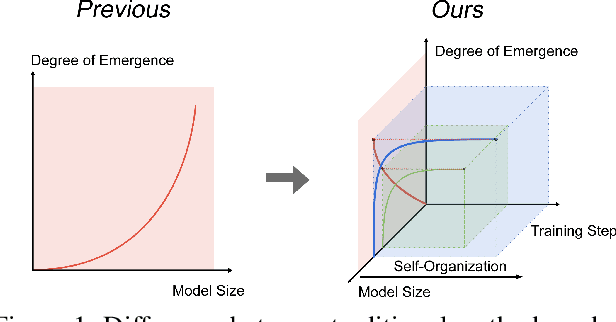
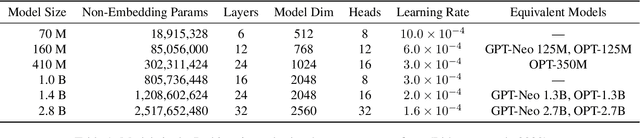

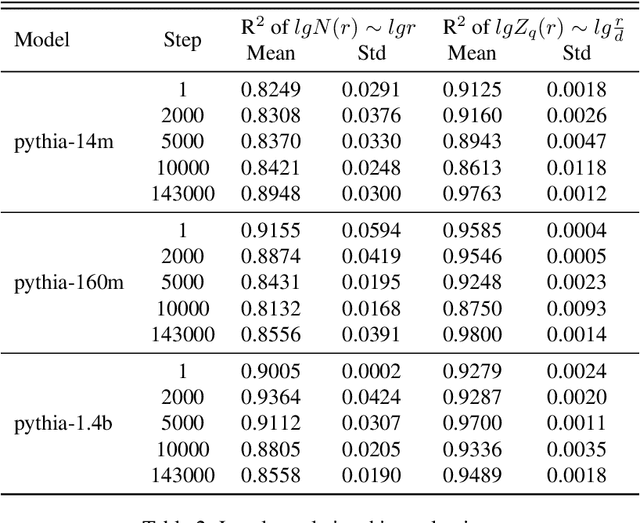
Prior studies on the emergence in large models have primarily focused on how the functional capabilities of large language models (LLMs) scale with model size. Our research, however, transcends this traditional paradigm, aiming to deepen our understanding of the emergence within LLMs by placing a special emphasis not just on the model size but more significantly on the complex behavior of neuron interactions during the training process. By introducing the concepts of "self-organization" and "multifractal analysis," we explore how neuron interactions dynamically evolve during training, leading to "emergence," mirroring the phenomenon in natural systems where simple micro-level interactions give rise to complex macro-level behaviors. To quantitatively analyze the continuously evolving interactions among neurons in large models during training, we propose the Neuron-based Multifractal Analysis (NeuroMFA). Utilizing NeuroMFA, we conduct a comprehensive examination of the emergent behavior in LLMs through the lens of both model size and training process, paving new avenues for research into the emergence in large models.
Neuro-Inspired Hierarchical Multimodal Learning
Sep 27, 2023Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Distinct from most traditional fusion models that aim to incorporate all modalities as input, our model designates the prime modality as input, while the remaining modalities act as detectors in the information pathway. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of downstream tasks. Experimental evaluations on both the MUStARD and CMU-MOSI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks.