 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDLCoRe: A Training-Free Framework for Mitigating Hallucinations in LLM-Generated HDL
Mar 18, 2025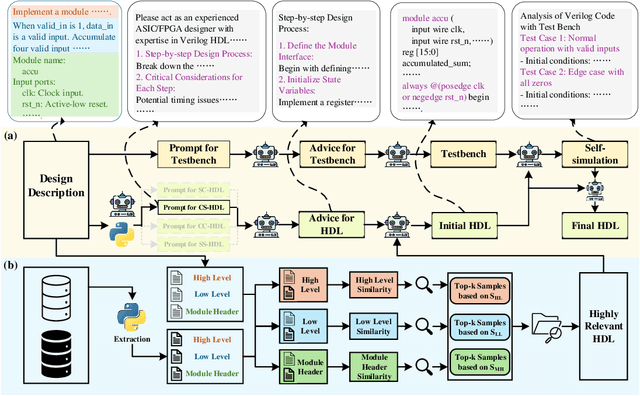



Recent advances in large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, when applied to hardware description languages (HDL), these models exhibit significant limitations due to data scarcity, resulting in hallucinations and incorrect code generation. To address these challenges, we propose HDLCoRe, a training-free framework that enhances LLMs' HDL generation capabilities through prompt engineering techniques and retrieval-augmented generation (RAG). Our approach consists of two main components: (1) an HDL-aware Chain-of-Thought (CoT) prompting technique with self-verification that classifies tasks by complexity and type, incorporates domain-specific knowledge, and guides LLMs through step-by-step self-simulation for error correction; and (2) a two-stage heterogeneous RAG system that addresses formatting inconsistencies through key component extraction and efficiently retrieves relevant HDL examples through sequential filtering and re-ranking. HDLCoRe eliminates the need for model fine-tuning while substantially improving LLMs' HDL generation capabilities. Experimental results demonstrate that our framework achieves superior performance on the RTLLM2.0 benchmark, significantly reducing hallucinations and improving both syntactic and functional correctness.
End-to-End Learning Framework for Solving Non-Markovian Optimal Control
Feb 07, 2025Integer-order calculus often falls short in capturing the long-range dependencies and memory effects found in many real-world processes. Fractional calculus addresses these gaps via fractional-order integrals and derivatives, but fractional-order dynamical systems pose substantial challenges in system identification and optimal control due to the lack of standard control methodologies. In this paper, we theoretically derive the optimal control via \textit{linear quadratic regulator} (LQR) for \textit{fractional-order linear time-invariant }(FOLTI) systems and develop an end-to-end deep learning framework based on this theoretical foundation. Our approach establishes a rigorous mathematical model, derives analytical solutions, and incorporates deep learning to achieve data-driven optimal control of FOLTI systems. Our key contributions include: (i) proposing an innovative system identification method control strategy for FOLTI systems, (ii) developing the first end-to-end data-driven learning framework, \textbf{F}ractional-\textbf{O}rder \textbf{L}earning for \textbf{O}ptimal \textbf{C}ontrol (FOLOC), that learns control policies from observed trajectories, and (iii) deriving a theoretical analysis of sample complexity to quantify the number of samples required for accurate optimal control in complex real-world problems. Experimental results indicate that our method accurately approximates fractional-order system behaviors without relying on Gaussian noise assumptions, pointing to promising avenues for advanced optimal control.
Network-informed Prompt Engineering against Organized Astroturf Campaigns under Extreme Class Imbalance
Jan 21, 2025Detecting organized political campaigns is of paramount importance in fighting against disinformation on social media. Existing approaches for the identification of such organized actions employ techniques mostly from network science, graph machine learning and natural language processing. Their ultimate goal is to analyze the relationships and interactions (e.g. re-posting) among users and the textual similarities of their posts. Despite their effectiveness in recognizing astroturf campaigns, these methods face significant challenges, notably the class imbalance in available training datasets. To mitigate this issue, recent methods usually resort to data augmentation or increasing the number of positive samples, which may not always be feasible or sufficient in real-world settings. Following a different path, in this paper, we propose a novel framework for identifying astroturf campaigns based solely on large language models (LLMs), introducing a Balanced Retrieval-Augmented Generation (Balanced RAG) component. Our approach first gives both textual information concerning the posts (in our case tweets) and the user interactions of the social network as input to a language model. Then, through prompt engineering and the proposed Balanced RAG method, it effectively detects coordinated disinformation campaigns on X (Twitter). The proposed framework does not require any training or fine-tuning of the language model. Instead, by strategically harnessing the strengths of prompt engineering and Balanced RAG, it facilitates LLMs to overcome the effects of class imbalance and effectively identify coordinated political campaigns. The experimental results demonstrate that by incorporating the proposed prompt engineering and Balanced RAG methods, our framework outperforms the traditional graph-based baselines, achieving 2x-3x improvements in terms of precision, recall and F1 scores.
Multi-scale Generative Modeling for Fast Sampling
Nov 14, 2024

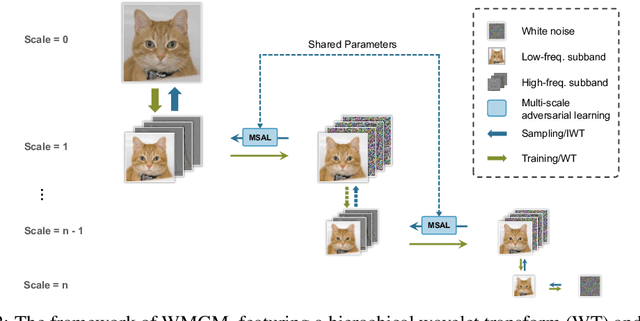
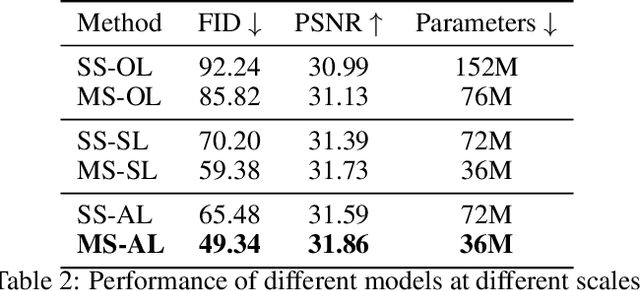
While working within the spatial domain can pose problems associated with ill-conditioned scores caused by power-law decay, recent advances in diffusion-based generative models have shown that transitioning to the wavelet domain offers a promising alternative. However, within the wavelet domain, we encounter unique challenges, especially the sparse representation of high-frequency coefficients, which deviates significantly from the Gaussian assumptions in the diffusion process. To this end, we propose a multi-scale generative modeling in the wavelet domain that employs distinct strategies for handling low and high-frequency bands. In the wavelet domain, we apply score-based generative modeling with well-conditioned scores for low-frequency bands, while utilizing a multi-scale generative adversarial learning for high-frequency bands. As supported by the theoretical analysis and experimental results, our model significantly improve performance and reduce the number of trainable parameters, sampling steps, and time.
Multi-scale Conditional Generative Modeling for Microscopic Image Restoration
Jul 07, 2024



The advance of diffusion-based generative models in recent years has revolutionized state-of-the-art (SOTA) techniques in a wide variety of image analysis and synthesis tasks, whereas their adaptation on image restoration, particularly within computational microscopy remains theoretically and empirically underexplored. In this research, we introduce a multi-scale generative model that enhances conditional image restoration through a novel exploitation of the Brownian Bridge process within wavelet domain. By initiating the Brownian Bridge diffusion process specifically at the lowest-frequency subband and applying generative adversarial networks at subsequent multi-scale high-frequency subbands in the wavelet domain, our method provides significant acceleration during training and sampling while sustaining a high image generation quality and diversity on par with SOTA diffusion models. Experimental results on various computational microscopy and imaging tasks confirm our method's robust performance and its considerable reduction in its sampling steps and time. This pioneering technique offers an efficient image restoration framework that harmonizes efficiency with quality, signifying a major stride in incorporating cutting-edge generative models into computational microscopy workflows.
A structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.
Neuro-Inspired Information-Theoretic Hierarchical Perception for Multimodal Learning
Apr 15, 2024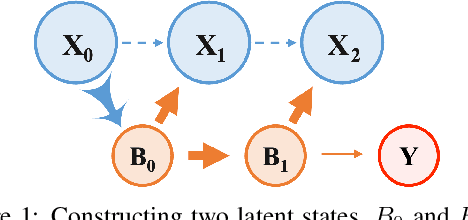
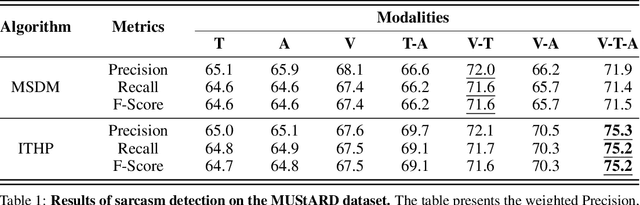
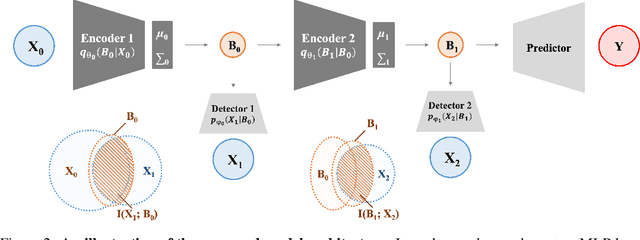

Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world in autonomous systems and cyber-physical systems. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Different from most traditional fusion models that incorporate all modalities identically in neural networks, our model designates a prime modality and regards the remaining modalities as detectors in the information pathway, serving to distill the flow of information. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of multimodal representation learning. Experimental evaluations on the MUStARD, CMU-MOSI, and CMU-MOSEI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks. Remarkably, on the CMU-MOSI dataset, ITHP surpasses human-level performance in the multimodal sentiment binary classification task across all evaluation metrics (i.e., Binary Accuracy, F1 Score, Mean Absolute Error, and Pearson Correlation).
Exploring Neuron Interactions and Emergence in LLMs: From the Multifractal Analysis Perspective
Feb 14, 2024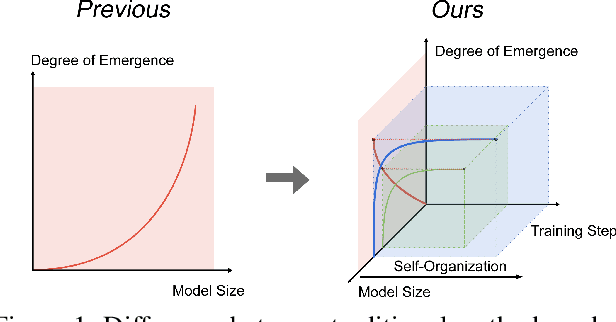

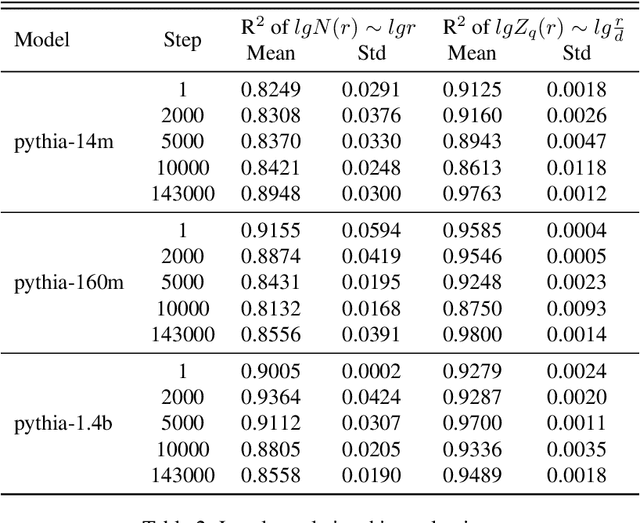
Prior studies on the emergence in large models have primarily focused on how the functional capabilities of large language models (LLMs) scale with model size. Our research, however, transcends this traditional paradigm, aiming to deepen our understanding of the emergence within LLMs by placing a special emphasis not just on the model size but more significantly on the complex behavior of neuron interactions during the training process. By introducing the concepts of "self-organization" and "multifractal analysis," we explore how neuron interactions dynamically evolve during training, leading to "emergence," mirroring the phenomenon in natural systems where simple micro-level interactions give rise to complex macro-level behaviors. To quantitatively analyze the continuously evolving interactions among neurons in large models during training, we propose the Neuron-based Multifractal Analysis (NeuroMFA). Utilizing NeuroMFA, we conduct a comprehensive examination of the emergent behavior in LLMs through the lens of both model size and training process, paving new avenues for research into the emergence in large models.
Unlocking Deep Learning: A BP-Free Approach for Parallel Block-Wise Training of Neural Networks
Dec 20, 2023



Backpropagation (BP) has been a successful optimization technique for deep learning models. However, its limitations, such as backward- and update-locking, and its biological implausibility, hinder the concurrent updating of layers and do not mimic the local learning processes observed in the human brain. To address these issues, recent research has suggested using local error signals to asynchronously train network blocks. However, this approach often involves extensive trial-and-error iterations to determine the best configuration for local training. This includes decisions on how to decouple network blocks and which auxiliary networks to use for each block. In our work, we introduce a novel BP-free approach: a block-wise BP-free (BWBPF) neural network that leverages local error signals to optimize distinct sub-neural networks separately, where the global loss is only responsible for updating the output layer. The local error signals used in the BP-free model can be computed in parallel, enabling a potential speed-up in the weight update process through parallel implementation. Our experimental results consistently show that this approach can identify transferable decoupled architectures for VGG and ResNet variations, outperforming models trained with end-to-end backpropagation and other state-of-the-art block-wise learning techniques on datasets such as CIFAR-10 and Tiny-ImageNet. The code is released at https://github.com/Belis0811/BWBPF.
Discovering Malicious Signatures in Software from Structural Interactions
Dec 19, 2023
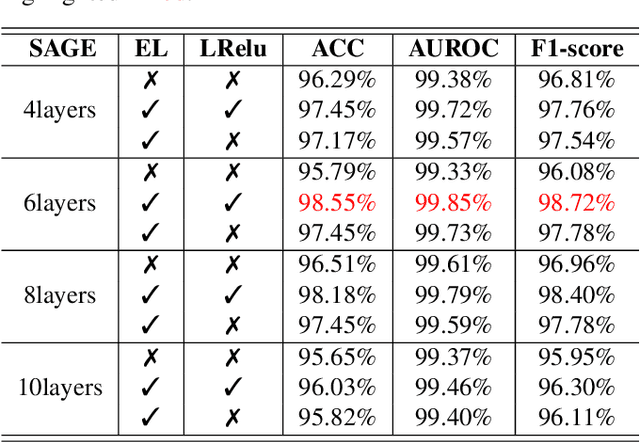
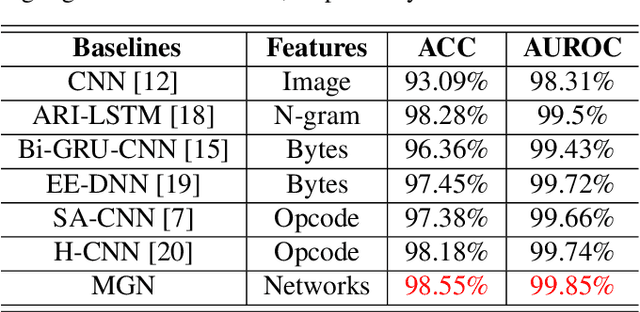
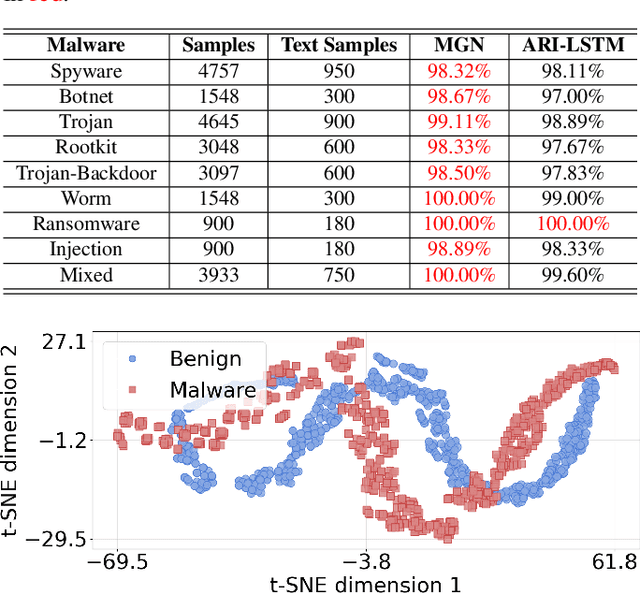
Malware represents a significant security concern in today's digital landscape, as it can destroy or disable operating systems, steal sensitive user information, and occupy valuable disk space. However, current malware detection methods, such as static-based and dynamic-based approaches, struggle to identify newly developed (``zero-day") malware and are limited by customized virtual machine (VM) environments. To overcome these limitations, we propose a novel malware detection approach that leverages deep learning, mathematical techniques, and network science. Our approach focuses on static and dynamic analysis and utilizes the Low-Level Virtual Machine (LLVM) to profile applications within a complex network. The generated network topologies are input into the GraphSAGE architecture to efficiently distinguish between benign and malicious software applications, with the operation names denoted as node features. Importantly, the GraphSAGE models analyze the network's topological geometry to make predictions, enabling them to detect state-of-the-art malware and prevent potential damage during execution in a VM. To evaluate our approach, we conduct a study on a dataset comprising source code from 24,376 applications, specifically written in C/C++, sourced directly from widely-recognized malware and various types of benign software. The results show a high detection performance with an Area Under the Receiver Operating Characteristic Curve (AUROC) of 99.85%. Our approach marks a substantial improvement in malware detection, providing a notably more accurate and efficient solution when compared to current state-of-the-art malware detection methods.