 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.
Leveraging Reinforcement Learning and Large Language Models for Code Optimization
Dec 09, 2023



Code optimization is a daunting task that requires a significant level of expertise from experienced programmers. This level of expertise is not sufficient when compared to the rapid development of new hardware architectures. Towards advancing the whole code optimization process, recent approaches rely on machine learning and artificial intelligence techniques. This paper introduces a new framework to decrease the complexity of code optimization. The proposed framework builds on large language models (LLMs) and reinforcement learning (RL) and enables LLMs to receive feedback from their environment (i.e., unit tests) during the fine-tuning process. We compare our framework with existing state-of-the-art models and show that it is more efficient with respect to speed and computational usage, as a result of the decrement in training steps and its applicability to models with fewer parameters. Additionally, our framework reduces the possibility of logical and syntactical errors. Toward evaluating our approach, we run several experiments on the PIE dataset using a CodeT5 language model and RRHF, a new reinforcement learning algorithm. We adopt a variety of evaluation metrics with regards to optimization quality, and speedup. The evaluation results demonstrate that the proposed framework has similar results in comparison with existing models using shorter training times and smaller pre-trained models. In particular, we accomplish an increase of 5.6% and 2.2 over the baseline models concerning the %OP T and SP metrics.
Robust Ranking Explanations
Jul 08, 2023



Robust explanations of machine learning models are critical to establish human trust in the models. Due to limited cognition capability, most humans can only interpret the top few salient features. It is critical to make top salient features robust to adversarial attacks, especially those against the more vulnerable gradient-based explanations. Existing defense measures robustness using $\ell_p$-norms, which have weaker protection power. We define explanation thickness for measuring salient features ranking stability, and derive tractable surrogate bounds of the thickness to design the \textit{R2ET} algorithm to efficiently maximize the thickness and anchor top salient features. Theoretically, we prove a connection between R2ET and adversarial training. Experiments with a wide spectrum of network architectures and data modalities, including brain networks, demonstrate that R2ET attains higher explanation robustness under stealthy attacks while retaining accuracy.
Line Graph Contrastive Learning for Link Prediction
Oct 25, 2022



Link prediction task aims to predict the connection of two nodes in the network. Existing works mainly predict links by node pairs similarity measurements. However, if the local structure doesn't meet such measurement assumption, the algorithms' performance will deteriorate rapidly. To overcome these limitations, we propose a Line Graph Contrastive Learning (LGCL) method to obtain multiview information. Our framework obtains a subgraph view by h-hop subgraph sampling with target node pairs as the center. After transforming the sampled subgraph into a line graph, the edge embedding information is directly accessible, and the link prediction task is converted into a node classification task. Then, different graph convolution operators learn representations from double perspectives. Finally, contrastive learning is adopted to balance the subgraph representations of these perspectives via maximizing mutual information. With experiments on six public datasets, LGCL outperforms current benchmarks on link prediction tasks and shows better generalization performance and robustness.
Memory-Augmented Graph Neural Networks: A Neuroscience Perspective
Sep 22, 2022

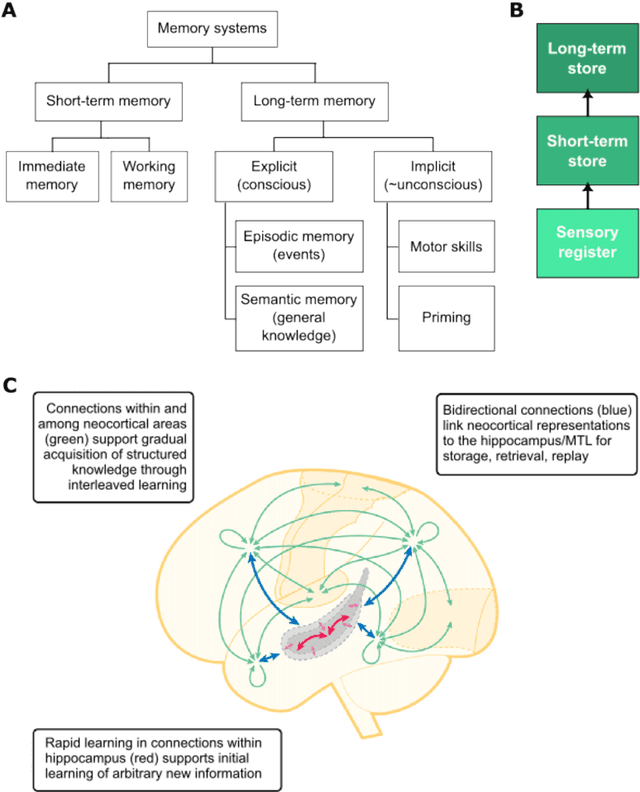
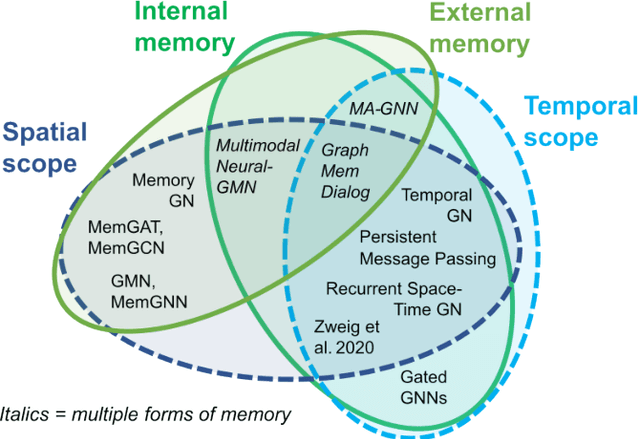
Graph neural networks (GNNs) have been extensively used for many domains where data are represented as graphs, including social networks, recommender systems, biology, chemistry, etc. Recently, the expressive power of GNNs has drawn much interest. It has been shown that, despite the promising empirical results achieved by GNNs for many applications, there are some limitations in GNNs that hinder their performance for some tasks. For example, since GNNs update node features mainly based on local information, they have limited expressive power in capturing long-range dependencies among nodes in graphs. To address some of the limitations of GNNs, several recent works started to explore augmenting GNNs with memory for improving their expressive power in the relevant tasks. In this paper, we provide a comprehensive review of the existing literature of memory-augmented GNNs. We review these works through the lens of psychology and neuroscience, which has established multiple memory systems and mechanisms in biological brains. We propose a taxonomy of the memory GNN works, as well as a set of criteria for comparing the memory mechanisms. We also provide critical discussions on the limitations of these works. Finally, we discuss the challenges and future directions for this area.
Contrastive Brain Network Learning via Hierarchical Signed Graph Pooling Model
Jul 14, 2022



Recently brain networks have been widely adopted to study brain dynamics, brain development and brain diseases. Graph representation learning techniques on brain functional networks can facilitate the discovery of novel biomarkers for clinical phenotypes and neurodegenerative diseases. However, current graph learning techniques have several issues on brain network mining. Firstly, most current graph learning models are designed for unsigned graph, which hinders the analysis of many signed network data (e.g., brain functional networks). Meanwhile, the insufficiency of brain network data limits the model performance on clinical phenotypes predictions. Moreover, few of current graph learning model is interpretable, which may not be capable to provide biological insights for model outcomes. Here, we propose an interpretable hierarchical signed graph representation learning model to extract graph-level representations from brain functional networks, which can be used for different prediction tasks. In order to further improve the model performance, we also propose a new strategy to augment functional brain network data for contrastive learning. We evaluate this framework on different classification and regression tasks using the data from HCP and OASIS. Our results from extensive experiments demonstrate the superiority of the proposed model compared to several state-of-the-art techniques. Additionally, we use graph saliency maps, derived from these prediction tasks, to demonstrate detection and interpretation of phenotypic biomarkers.
End-to-end Mapping in Heterogeneous Systems Using Graph Representation Learning
Apr 25, 2022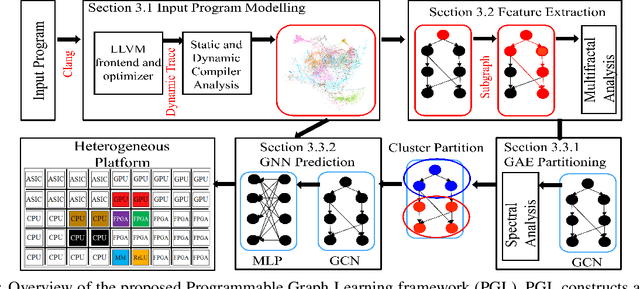
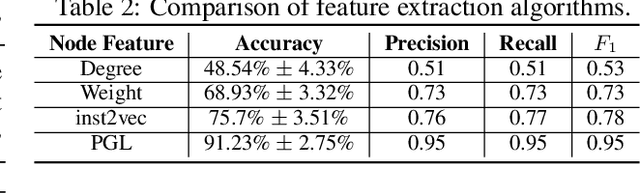
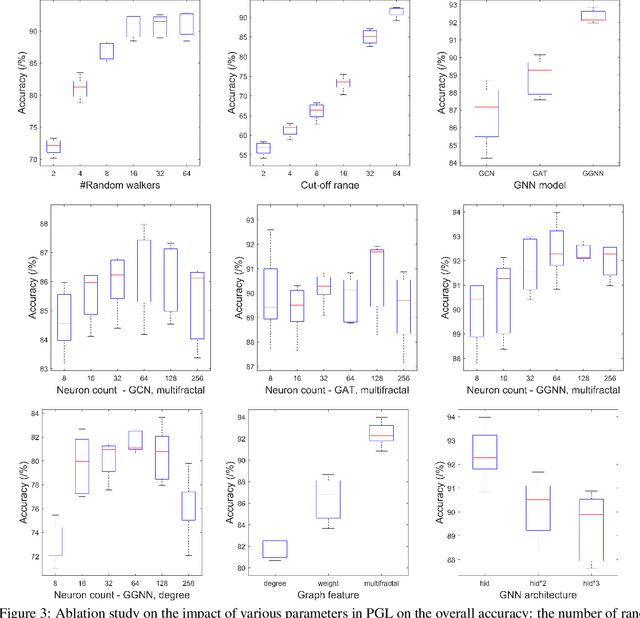
To enable heterogeneous computing systems with autonomous programming and optimization capabilities, we propose a unified, end-to-end, programmable graph representation learning (PGL) framework that is capable of mining the complexity of high-level programs down to the universal intermediate representation, extracting the specific computational patterns and predicting which code segments would run best on a specific core in heterogeneous hardware platforms. The proposed framework extracts multi-fractal topological features from code graphs, utilizes graph autoencoders to learn how to partition the graph into computational kernels, and exploits graph neural networks (GNN) to predict the correct assignment to a processor type. In the evaluation, we validate the PGL framework and demonstrate a maximum speedup of 6.42x compared to the thread-based execution, and 2.02x compared to the state-of-the-art technique.
Self-learn to Explain Siamese Networks Robustly
Sep 15, 2021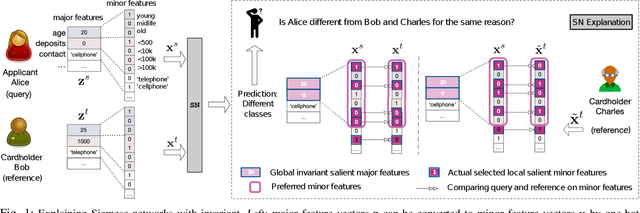
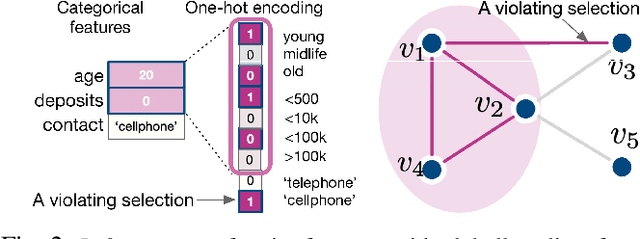
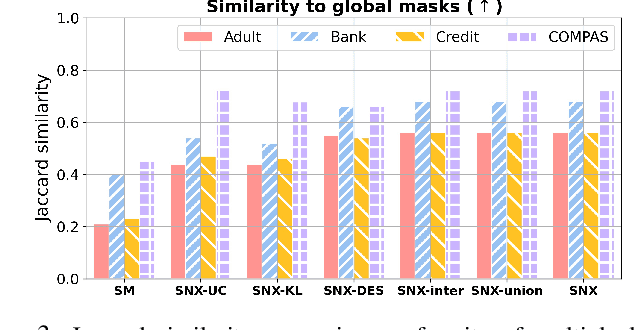
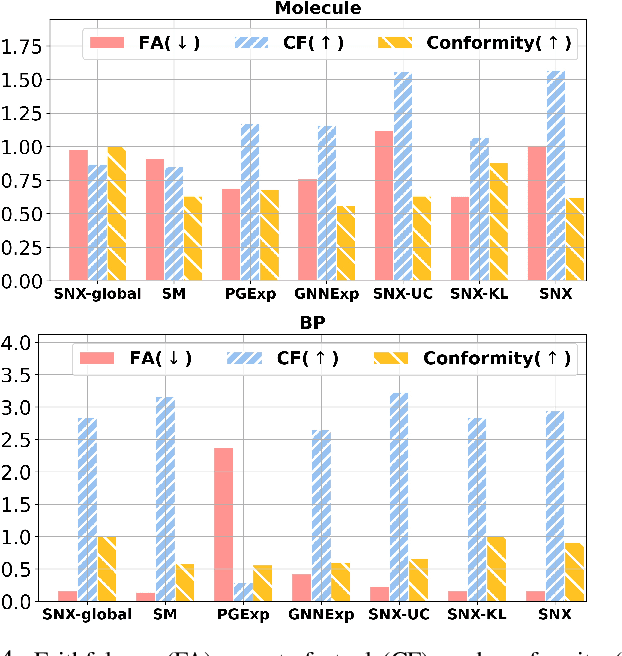
Learning to compare two objects are essential in applications, such as digital forensics, face recognition, and brain network analysis, especially when labeled data is scarce and imbalanced. As these applications make high-stake decisions and involve societal values like fairness and transparency, it is critical to explain the learned models. We aim to study post-hoc explanations of Siamese networks (SN) widely used in learning to compare. We characterize the instability of gradient-based explanations due to the additional compared object in SN, in contrast to architectures with a single input instance. We propose an optimization framework that derives global invariance from unlabeled data using self-learning to promote the stability of local explanations tailored for specific query-reference pairs. The optimization problems can be solved using gradient descent-ascent (GDA) for constrained optimization, or SGD for KL-divergence regularized unconstrained optimization, with convergence proofs, especially when the objective functions are nonconvex due to the Siamese architecture. Quantitative results and case studies on tabular and graph data from neuroscience and chemical engineering show that the framework respects the self-learned invariance while robustly optimizing the faithfulness and simplicity of the explanation. We further demonstrate the convergence of GDA experimentally.
PSGR: Pixel-wise Sparse Graph Reasoning for COVID-19 Pneumonia Segmentation in CT Images
Aug 09, 2021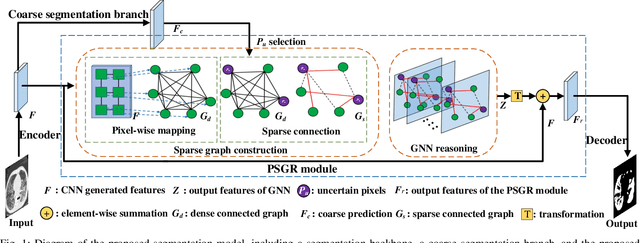
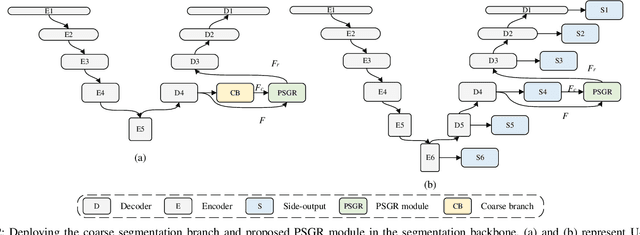

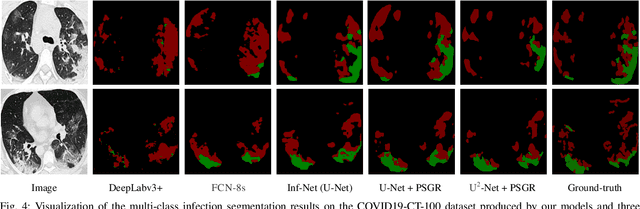
Automated and accurate segmentation of the infected regions in computed tomography (CT) images is critical for the prediction of the pathological stage and treatment response of COVID-19. Several deep convolutional neural networks (DCNNs) have been designed for this task, whose performance, however, tends to be suppressed by their limited local receptive fields and insufficient global reasoning ability. In this paper, we propose a pixel-wise sparse graph reasoning (PSGR) module and insert it into a segmentation network to enhance the modeling of long-range dependencies for COVID-19 infected region segmentation in CT images. In the PSGR module, a graph is first constructed by projecting each pixel on a node based on the features produced by the segmentation backbone, and then converted into a sparsely-connected graph by keeping only K strongest connections to each uncertain pixel. The long-range information reasoning is performed on the sparsely-connected graph to generate enhanced features. The advantages of this module are two-fold: (1) the pixel-wise mapping strategy not only avoids imprecise pixel-to-node projections but also preserves the inherent information of each pixel for global reasoning; and (2) the sparsely-connected graph construction results in effective information retrieval and reduction of the noise propagation. The proposed solution has been evaluated against four widely-used segmentation models on three public datasets. The results show that the segmentation model equipped with our PSGR module can effectively segment COVID-19 infected regions in CT images, outperforming all other competing models.