 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Guided Prompt: Instructing Large Language Model in Multi-Step Reasoning by Exploring Graph Structure of the Text
Feb 20, 2024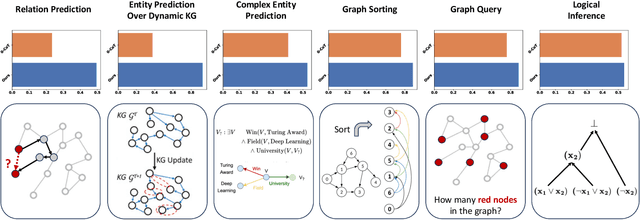

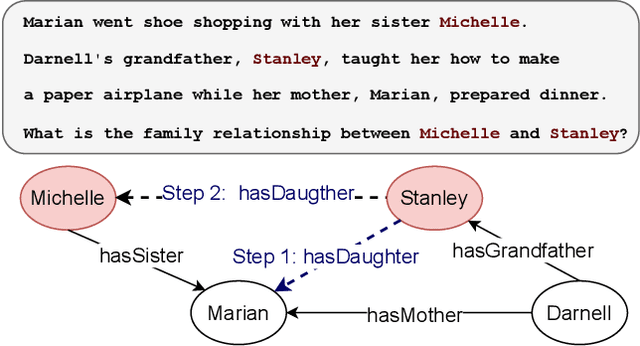
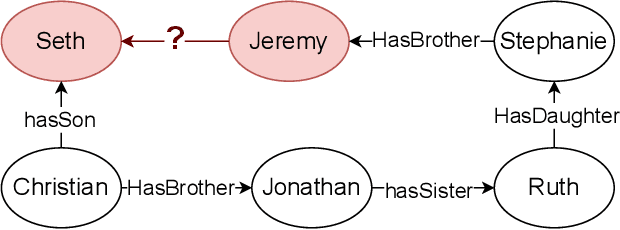
Although Large Language Models (LLMs) excel at addressing straightforward reasoning tasks, they frequently struggle with difficulties when confronted by more complex multi-step reasoning due to a range of factors. Firstly, natural language often encompasses complex relationships among entities, making it challenging to maintain a clear reasoning chain over longer spans. Secondly, the abundance of linguistic diversity means that the same entities and relationships can be expressed using different terminologies and structures, complicating the task of identifying and establishing connections between multiple pieces of information. Graphs provide an effective solution to represent data rich in relational information and capture long-term dependencies among entities. To harness the potential of graphs, our paper introduces Structure Guided Prompt, an innovative three-stage task-agnostic prompting framework designed to improve the multi-step reasoning capabilities of LLMs in a zero-shot setting. This framework explicitly converts unstructured text into a graph via LLMs and instructs them to navigate this graph using task-specific strategies to formulate responses. By effectively organizing information and guiding navigation, it enables LLMs to provide more accurate and context-aware responses. Our experiments show that this framework significantly enhances the reasoning capabilities of LLMs, enabling them to excel in a broader spectrum of natural language scenarios.
Locally-Adaptive Quantization for Streaming Vector Search
Feb 03, 2024



Retrieving the most similar vector embeddings to a given query among a massive collection of vectors has long been a key component of countless real-world applications. The recently introduced Retrieval-Augmented Generation is one of the most prominent examples. For many of these applications, the database evolves over time by inserting new data and removing outdated data. In these cases, the retrieval problem is known as streaming similarity search. While Locally-Adaptive Vector Quantization (LVQ), a highly efficient vector compression method, yields state-of-the-art search performance for non-evolving databases, its usefulness in the streaming setting has not been yet established. In this work, we study LVQ in streaming similarity search. In support of our evaluation, we introduce two improvements of LVQ: Turbo LVQ and multi-means LVQ that boost its search performance by up to 28% and 27%, respectively. Our studies show that LVQ and its new variants enable blazing fast vector search, outperforming its closest competitor by up to 9.4x for identically distributed data and by up to 8.8x under the challenging scenario of data distribution shifts (i.e., where the statistical distribution of the data changes over time). We release our contributions as part of Scalable Vector Search, an open-source library for high-performance similarity search.
Memory-Augmented Graph Neural Networks: A Neuroscience Perspective
Sep 22, 2022

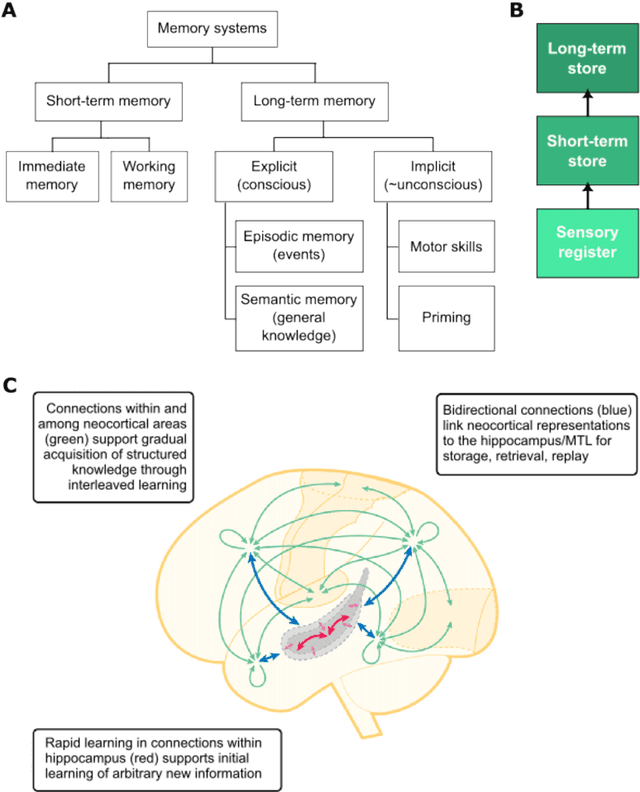
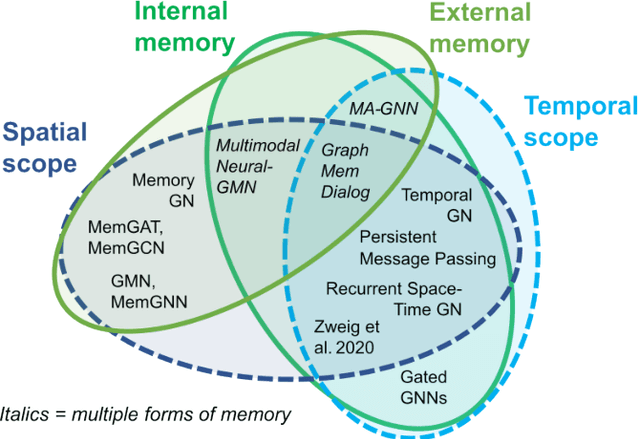
Graph neural networks (GNNs) have been extensively used for many domains where data are represented as graphs, including social networks, recommender systems, biology, chemistry, etc. Recently, the expressive power of GNNs has drawn much interest. It has been shown that, despite the promising empirical results achieved by GNNs for many applications, there are some limitations in GNNs that hinder their performance for some tasks. For example, since GNNs update node features mainly based on local information, they have limited expressive power in capturing long-range dependencies among nodes in graphs. To address some of the limitations of GNNs, several recent works started to explore augmenting GNNs with memory for improving their expressive power in the relevant tasks. In this paper, we provide a comprehensive review of the existing literature of memory-augmented GNNs. We review these works through the lens of psychology and neuroscience, which has established multiple memory systems and mechanisms in biological brains. We propose a taxonomy of the memory GNN works, as well as a set of criteria for comparing the memory mechanisms. We also provide critical discussions on the limitations of these works. Finally, we discuss the challenges and future directions for this area.
End-to-end Mapping in Heterogeneous Systems Using Graph Representation Learning
Apr 25, 2022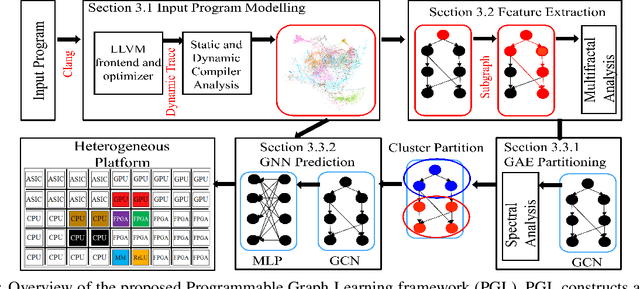
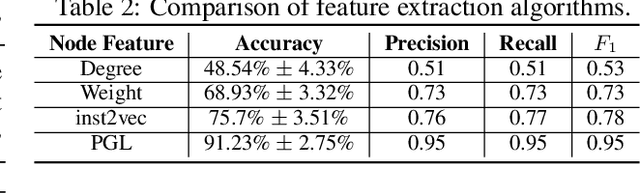
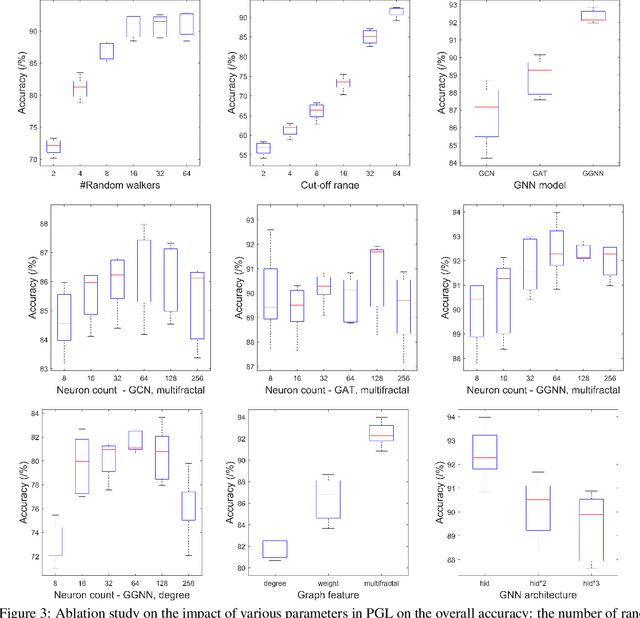
To enable heterogeneous computing systems with autonomous programming and optimization capabilities, we propose a unified, end-to-end, programmable graph representation learning (PGL) framework that is capable of mining the complexity of high-level programs down to the universal intermediate representation, extracting the specific computational patterns and predicting which code segments would run best on a specific core in heterogeneous hardware platforms. The proposed framework extracts multi-fractal topological features from code graphs, utilizes graph autoencoders to learn how to partition the graph into computational kernels, and exploits graph neural networks (GNN) to predict the correct assignment to a processor type. In the evaluation, we validate the PGL framework and demonstrate a maximum speedup of 6.42x compared to the thread-based execution, and 2.02x compared to the state-of-the-art technique.