 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepwise Penalization for Length-Efficient Chain-of-Thought Reasoning
Feb 27, 2026Large reasoning models improve with more test-time computation, but often overthink, producing unnecessarily long chains-of-thought that raise cost without improving accuracy. Prior reinforcement learning approaches typically rely on a single outcome reward with trajectory-level length penalties, which cannot distinguish essential from redundant reasoning steps and therefore yield blunt compression. Although recent work incorporates step-level signals, such as offline pruning, supervised data construction, or verifier-based intermediate rewards, reasoning length is rarely treated as an explicit step-level optimization objective during RL. We propose Step-wise Adaptive Penalization (SWAP), a fine-grained framework that allocates length reduction across steps based on intrinsic contribution. We estimate step importance from the model's on-policy log-probability improvement toward the correct answer, then treat excess length as a penalty mass redistributed to penalize low-importance steps more heavily while preserving high-importance reasoning. We optimize with a unified outcome-process advantage within group-relative policy optimization. Extensive experiments demonstrate that SWAP reduces reasoning length by 64.3% on average while improving accuracy by 5.7% relative to the base model.
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Aug 07, 2024



Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.
Structure Guided Prompt: Instructing Large Language Model in Multi-Step Reasoning by Exploring Graph Structure of the Text
Feb 20, 2024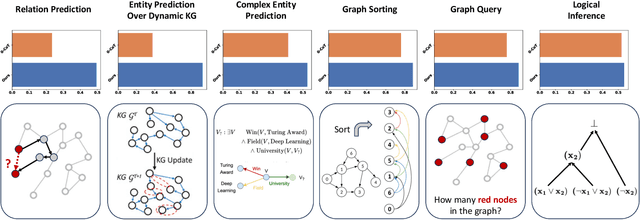

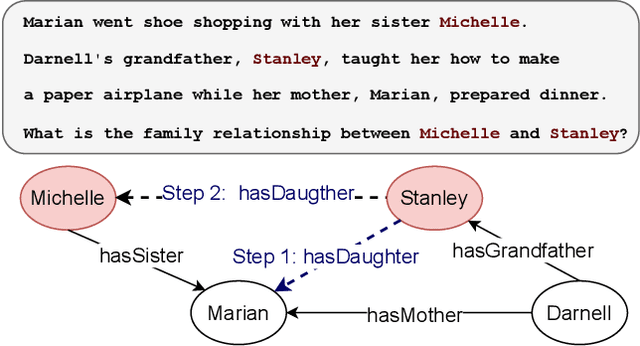
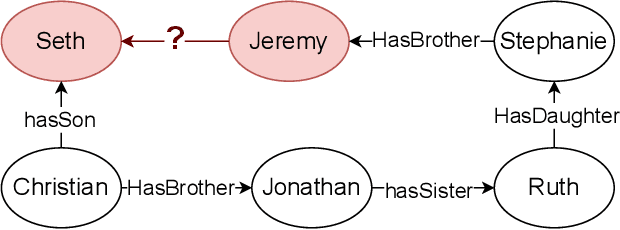
Although Large Language Models (LLMs) excel at addressing straightforward reasoning tasks, they frequently struggle with difficulties when confronted by more complex multi-step reasoning due to a range of factors. Firstly, natural language often encompasses complex relationships among entities, making it challenging to maintain a clear reasoning chain over longer spans. Secondly, the abundance of linguistic diversity means that the same entities and relationships can be expressed using different terminologies and structures, complicating the task of identifying and establishing connections between multiple pieces of information. Graphs provide an effective solution to represent data rich in relational information and capture long-term dependencies among entities. To harness the potential of graphs, our paper introduces Structure Guided Prompt, an innovative three-stage task-agnostic prompting framework designed to improve the multi-step reasoning capabilities of LLMs in a zero-shot setting. This framework explicitly converts unstructured text into a graph via LLMs and instructs them to navigate this graph using task-specific strategies to formulate responses. By effectively organizing information and guiding navigation, it enables LLMs to provide more accurate and context-aware responses. Our experiments show that this framework significantly enhances the reasoning capabilities of LLMs, enabling them to excel in a broader spectrum of natural language scenarios.
Inductive Meta-path Learning for Schema-complex Heterogeneous Information Networks
Jul 08, 2023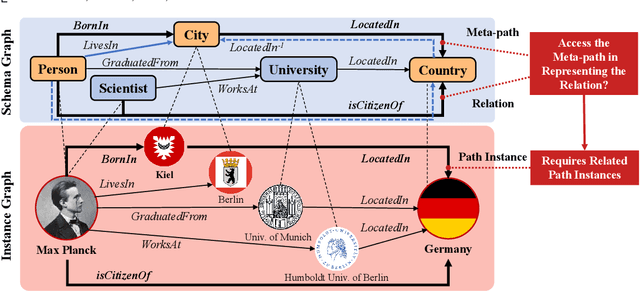
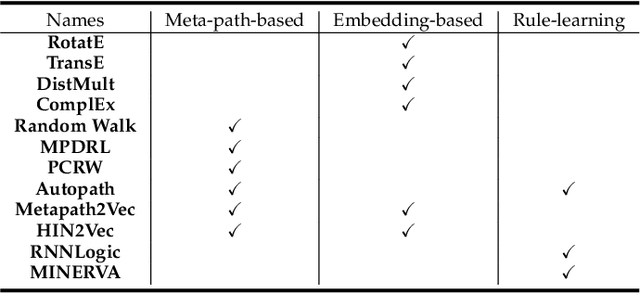
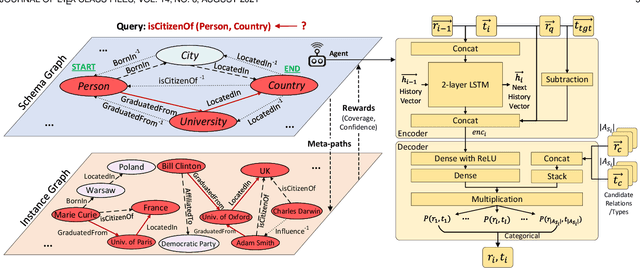
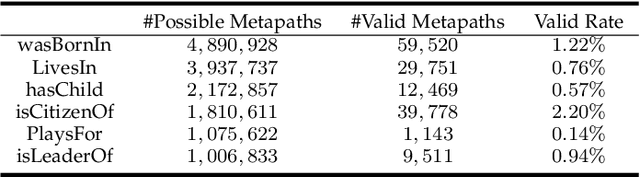
Heterogeneous Information Networks (HINs) are information networks with multiple types of nodes and edges. The concept of meta-path, i.e., a sequence of entity types and relation types connecting two entities, is proposed to provide the meta-level explainable semantics for various HIN tasks. Traditionally, meta-paths are primarily used for schema-simple HINs, e.g., bibliographic networks with only a few entity types, where meta-paths are often enumerated with domain knowledge. However, the adoption of meta-paths for schema-complex HINs, such as knowledge bases (KBs) with hundreds of entity and relation types, has been limited due to the computational complexity associated with meta-path enumeration. Additionally, effectively assessing meta-paths requires enumerating relevant path instances, which adds further complexity to the meta-path learning process. To address these challenges, we propose SchemaWalk, an inductive meta-path learning framework for schema-complex HINs. We represent meta-paths with schema-level representations to support the learning of the scores of meta-paths for varying relations, mitigating the need of exhaustive path instance enumeration for each relation. Further, we design a reinforcement-learning based path-finding agent, which directly navigates the network schema (i.e., schema graph) to learn policies for establishing meta-paths with high coverage and confidence for multiple relations. Extensive experiments on real data sets demonstrate the effectiveness of our proposed paradigm.
Neural Compositional Rule Learning for Knowledge Graph Reasoning
Mar 07, 2023



Learning logical rules is critical to improving reasoning in KGs. This is due to their ability to provide logical and interpretable explanations when used for predictions, as well as their ability to generalize to other tasks, domains, and data. While recent methods have been proposed to learn logical rules, the majority of these methods are either restricted by their computational complexity and can not handle the large search space of large-scale KGs, or show poor generalization when exposed to data outside the training set. In this paper, we propose an end-to-end neural model for learning compositional logical rules called NCRL. NCRL detects the best compositional structure of a rule body, and breaks it into small compositions in order to infer the rule head. By recurrently merging compositions in the rule body with a recurrent attention unit, NCRL finally predicts a single rule head. Experimental results show that NCRL learns high-quality rules, as well as being generalizable. Specifically, we show that NCRL is scalable, efficient, and yields state-of-the-art results for knowledge graph completion on large-scale KGs. Moreover, we test NCRL for systematic generalization by learning to reason on small-scale observed graphs and evaluating on larger unseen ones.
SecureBoost: A Lossless Federated Learning Framework
Jan 25, 2019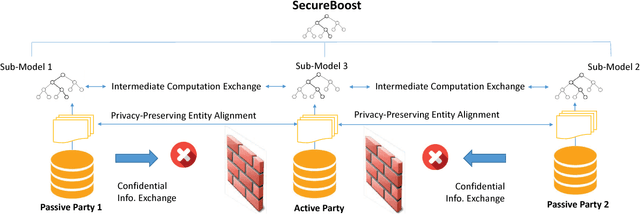
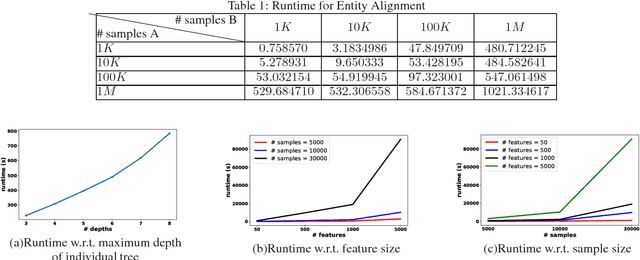
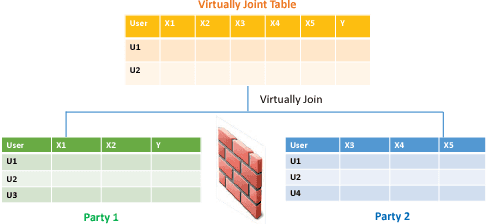
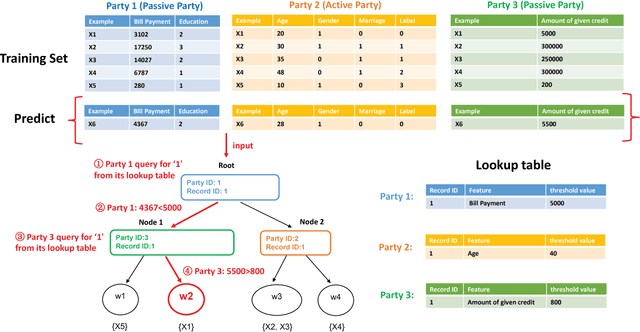
The protection of user privacy is an important concern in machine learning, as evidenced by the rolling out of the General Data Protection Regulation (GDPR) in the European Union (EU) in May 2018. The GDPR is designed to give users more control over their personal data, which motivates us to explore machine learning frameworks with data sharing without violating user privacy. To meet this goal, in this paper, we propose a novel lossless privacy-preserving tree-boosting system known as SecureBoost in the setting of federated learning. This federated-learning system allows a learning process to be jointly conducted over multiple parties with partially common user samples but different feature sets, which corresponds to a vertically partitioned virtual data set. An advantage of SecureBoost is that it provides the same level of accuracy as the non-privacy-preserving approach while at the same time, reveal no information of each private data provider. We theoretically prove that the SecureBoost framework is as accurate as other non-federated gradient tree-boosting algorithms that bring the data into one place. In addition, along with a proof of security, we discuss what would be required to make the protocols completely secure.
Feature Selection: A Data Perspective
Aug 26, 2018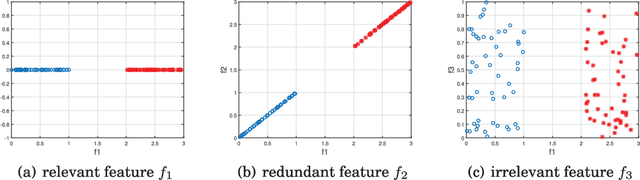
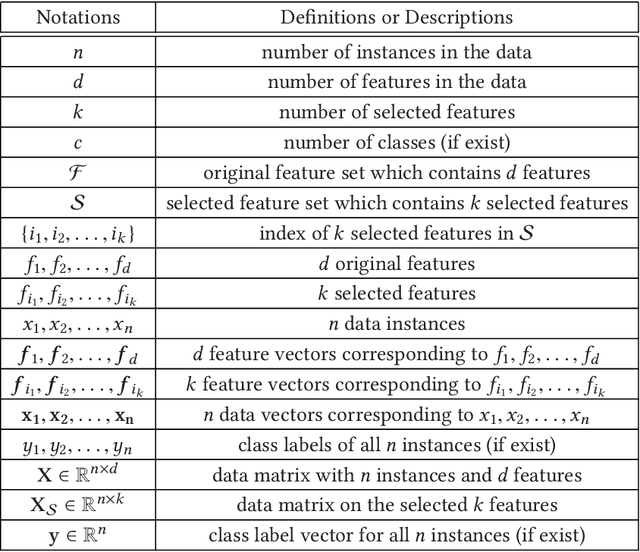
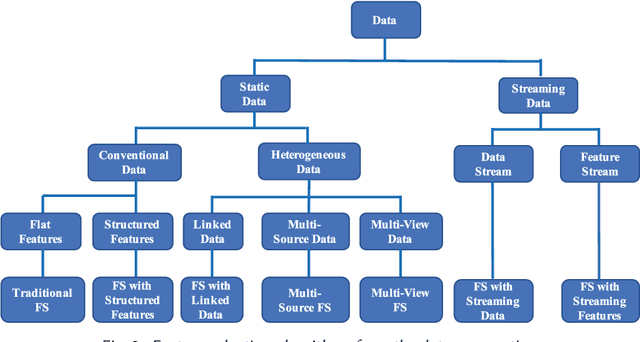
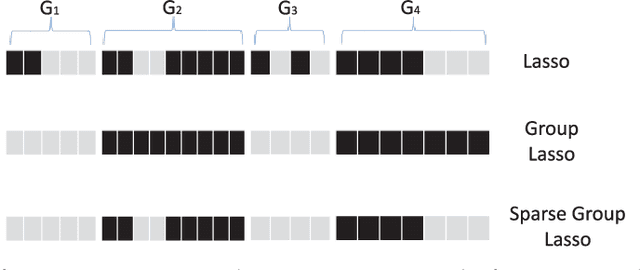
Feature selection, as a data preprocessing strategy, has been proven to be effective and efficient in preparing data (especially high-dimensional data) for various data mining and machine learning problems. The objectives of feature selection include: building simpler and more comprehensible models, improving data mining performance, and preparing clean, understandable data. The recent proliferation of big data has presented some substantial challenges and opportunities to feature selection. In this survey, we provide a comprehensive and structured overview of recent advances in feature selection research. Motivated by current challenges and opportunities in the era of big data, we revisit feature selection research from a data perspective and review representative feature selection algorithms for conventional data, structured data, heterogeneous data and streaming data. Methodologically, to emphasize the differences and similarities of most existing feature selection algorithms for conventional data, we categorize them into four main groups: similarity based, information theoretical based, sparse learning based and statistical based methods. To facilitate and promote the research in this community, we also present an open-source feature selection repository that consists of most of the popular feature selection algorithms (\url{http://featureselection.asu.edu/}). Also, we use it as an example to show how to evaluate feature selection algorithms. At the end of the survey, we present a discussion about some open problems and challenges that require more attention in future research.