 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
Jan 30, 2026RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. In practice, prompt pools are often static or only loosely tied to the model's learning progress, so uniform sampling can't keep up with the shifting capability frontier and ends up wasting rollouts on prompts that are already solved or still out of reach. Existing approaches improve efficiency through filtering, curricula, adaptive rollout allocation, or teacher guidance, but they typically assume a fixed pool-which makes it hard to support stable on-policy pool growth-or they add extra teacher cost and latency. We introduce HeaPA (Heap Sampling and On-Policy Query Augmentation), which maintains a bounded, evolving pool, tracks the frontier using heap-based boundary sampling, expands the pool via on-policy augmentation with lightweight asynchronous validation, and stabilizes correlated queries through topology-aware re-estimation of pool statistics and controlled reinsertion. Across two training corpora, two training recipes, and seven benchmarks, HeaPA consistently improves accuracy and reaches target performance with fewer computations while keeping wall-clock time comparable. Our analyses suggest these gains come from frontier-focused sampling and on-policy pool growth, with the benefits becoming larger as model scale increases. Our code is available at https://github.com/horizon-rl/HeaPA.
Teach Diffusion Language Models to Learn from Their Own Mistakes
Jan 10, 2026Masked Diffusion Language Models (DLMs) achieve significant speed by generating multiple tokens in parallel. However, this parallel sampling approach, especially when using fewer inference steps, will introduce strong dependency errors and cause quality to deteriorate rapidly as the generation step size grows. As a result, reliable self-correction becomes essential for maintaining high-quality multi-token generation. To address this, we propose Decoupled Self-Correction (DSC), a novel two-stage methodology. DSC first fully optimizes the DLM's generative ability before freezing the model and training a specialized correction head. This decoupling preserves the model's peak SFT performance and ensures the generated errors used for correction head training are of higher quality. Additionally, we introduce Future-Context Augmentation (FCA) to maximize the correction head's accuracy. FCA generalizes the error training distribution by augmenting samples with ground-truth tokens, effectively training the head to utilize a richer, future-looking context. This mechanism is used for reliably detecting the subtle errors of the high-fidelity base model. Our DSC framework enables the model, at inference time, to jointly generate and revise tokens, thereby correcting errors introduced by multi-token generation and mitigating error accumulation across steps. Experiments on mathematical reasoning and code generation benchmarks demonstrate that our approach substantially reduces the quality degradation associated with larger generation steps, allowing DLMs to achieve both high generation speed and strong output fidelity.
END: Early Noise Dropping for Efficient and Effective Context Denoising
Feb 26, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, they are often distracted by irrelevant or noisy context in input sequences that degrades output quality. This problem affects both long- and short-context scenarios, such as retrieval-augmented generation, table question-answering, and in-context learning. We reveal that LLMs can implicitly identify whether input sequences contain useful information at early layers, prior to token generation. Leveraging this insight, we introduce Early Noise Dropping (\textsc{END}), a novel approach to mitigate this issue without requiring fine-tuning the LLMs. \textsc{END} segments input sequences into chunks and employs a linear prober on the early layers of LLMs to differentiate between informative and noisy chunks. By discarding noisy chunks early in the process, \textsc{END} preserves critical information, reduces distraction, and lowers computational overhead. Extensive experiments demonstrate that \textsc{END} significantly improves both performance and efficiency across different LLMs on multiple evaluation datasets. Furthermore, by investigating LLMs' implicit understanding to the input with the prober, this work also deepens understanding of how LLMs do reasoning with contexts internally.
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.
Scaling Laws for Predicting Downstream Performance in LLMs
Oct 11, 2024



Precise estimation of downstream performance in large language models (LLMs) prior to training is essential for guiding their development process. Scaling laws analysis utilizes the statistics of a series of significantly smaller sampling language models (LMs) to predict the performance of the target LLM. For downstream performance prediction, the critical challenge lies in the emergent abilities in LLMs that occur beyond task-specific computational thresholds. In this work, we focus on the pre-training loss as a more computation-efficient metric for performance estimation. Our two-stage approach consists of first estimating a function that maps computational resources (e.g., FLOPs) to the pre-training Loss using a series of sampling models, followed by mapping the pre-training loss to downstream task Performance after the critical "emergent phase". In preliminary experiments, this FLP solution accurately predicts the performance of LLMs with 7B and 13B parameters using a series of sampling LMs up to 3B, achieving error margins of 5% and 10%, respectively, and significantly outperforming the FLOPs-to-Performance approach. This motivates FLP-M, a fundamental approach for performance prediction that addresses the practical need to integrate datasets from multiple sources during pre-training, specifically blending general corpora with code data to accurately represent the common necessity. FLP-M extends the power law analytical function to predict domain-specific pre-training loss based on FLOPs across data sources, and employs a two-layer neural network to model the non-linear relationship between multiple domain-specific loss and downstream performance. By utilizing a 3B LLM trained on a specific ratio and a series of smaller sampling LMs, FLP-M can effectively forecast the performance of 3B and 7B LLMs across various data mixtures for most benchmarks within 10% error margins.
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Aug 07, 2024



Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.
Concept2Box: Joint Geometric Embeddings for Learning Two-View Knowledge Graphs
Jul 04, 2023



Knowledge graph embeddings (KGE) have been extensively studied to embed large-scale relational data for many real-world applications. Existing methods have long ignored the fact many KGs contain two fundamentally different views: high-level ontology-view concepts and fine-grained instance-view entities. They usually embed all nodes as vectors in one latent space. However, a single geometric representation fails to capture the structural differences between two views and lacks probabilistic semantics towards concepts' granularity. We propose Concept2Box, a novel approach that jointly embeds the two views of a KG using dual geometric representations. We model concepts with box embeddings, which learn the hierarchy structure and complex relations such as overlap and disjoint among them. Box volumes can be interpreted as concepts' granularity. Different from concepts, we model entities as vectors. To bridge the gap between concept box embeddings and entity vector embeddings, we propose a novel vector-to-box distance metric and learn both embeddings jointly. Experiments on both the public DBpedia KG and a newly-created industrial KG showed the effectiveness of Concept2Box.
Label-Efficient Self-Training for Attribute Extraction from Semi-Structured Web Documents
Aug 27, 2022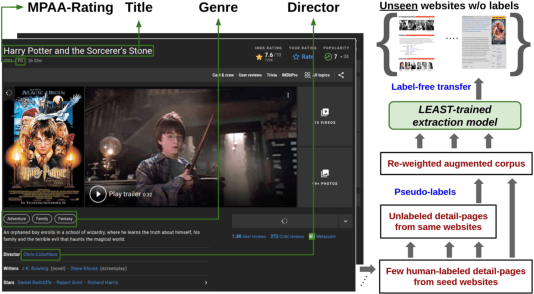

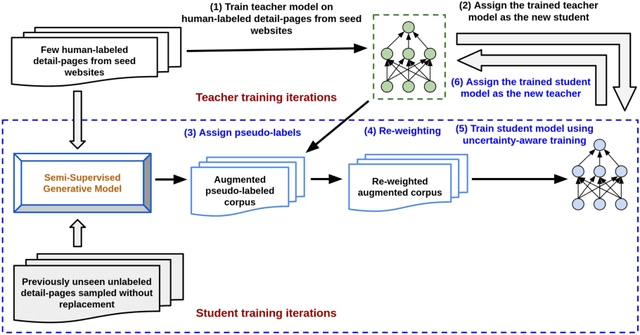
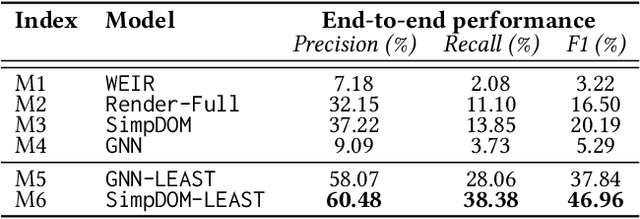
Extracting structured information from HTML documents is a long-studied problem with a broad range of applications, including knowledge base construction, faceted search, and personalized recommendation. Prior works rely on a few human-labeled web pages from each target website or thousands of human-labeled web pages from some seed websites to train a transferable extraction model that generalizes on unseen target websites. Noisy content, low site-level consistency, and lack of inter-annotator agreement make labeling web pages a time-consuming and expensive ordeal. We develop LEAST -- a Label-Efficient Self-Training method for Semi-Structured Web Documents to overcome these limitations. LEAST utilizes a few human-labeled pages to pseudo-annotate a large number of unlabeled web pages from the target vertical. It trains a transferable web-extraction model on both human-labeled and pseudo-labeled samples using self-training. To mitigate error propagation due to noisy training samples, LEAST re-weights each training sample based on its estimated label accuracy and incorporates it in training. To the best of our knowledge, this is the first work to propose end-to-end training for transferable web extraction models utilizing only a few human-labeled pages. Experiments on a large-scale public dataset show that using less than ten human-labeled pages from each seed website for training, a LEAST-trained model outperforms previous state-of-the-art by more than 26 average F1 points on unseen websites, reducing the number of human-labeled pages to achieve similar performance by more than 10x.
DOM-LM: Learning Generalizable Representations for HTML Documents
Jan 25, 2022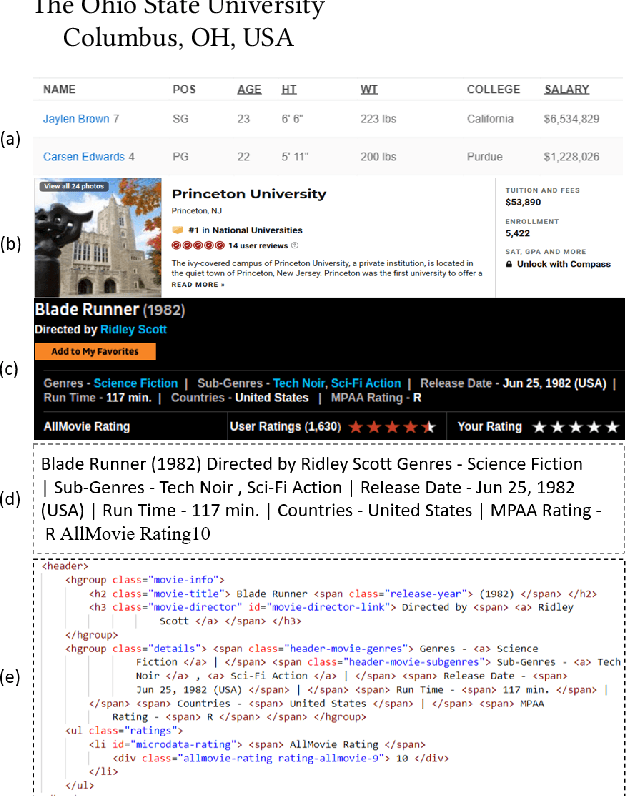

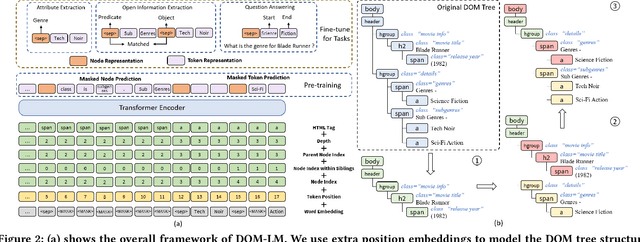
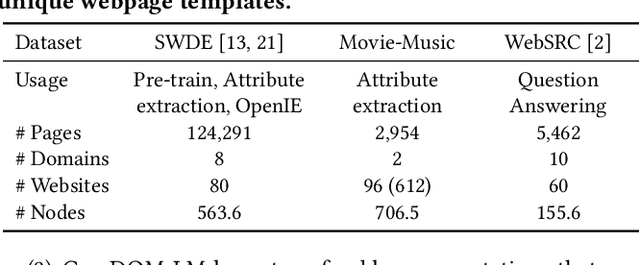
HTML documents are an important medium for disseminating information on the Web for human consumption. An HTML document presents information in multiple text formats including unstructured text, structured key-value pairs, and tables. Effective representation of these documents is essential for machine understanding to enable a wide range of applications, such as Question Answering, Web Search, and Personalization. Existing work has either represented these documents using visual features extracted by rendering them in a browser, which is typically computationally expensive, or has simply treated them as plain text documents, thereby failing to capture useful information presented in their HTML structure. We argue that the text and HTML structure together convey important semantics of the content and therefore warrant a special treatment for their representation learning. In this paper, we introduce a novel representation learning approach for web pages, dubbed DOM-LM, which addresses the limitations of existing approaches by encoding both text and DOM tree structure with a transformer-based encoder and learning generalizable representations for HTML documents via self-supervised pre-training. We evaluate DOM-LM on a variety of webpage understanding tasks, including Attribute Extraction, Open Information Extraction, and Question Answering. Our extensive experiments show that DOM-LM consistently outperforms all baselines designed for these tasks. In particular, DOM-LM demonstrates better generalization performance both in few-shot and zero-shot settings, making it attractive for making it suitable for real-world application settings with limited labeled data.
RATE: Overcoming Noise and Sparsity of Textual Features in Real-Time Location Estimation
Nov 12, 2021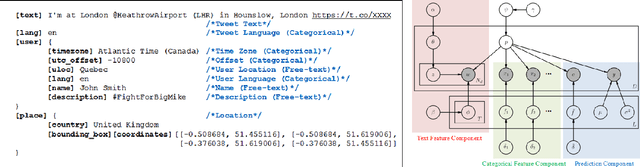
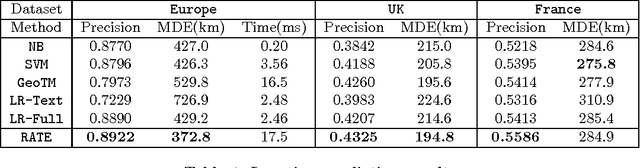
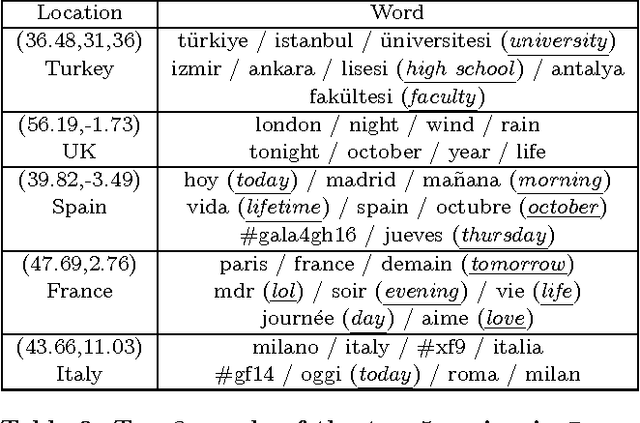
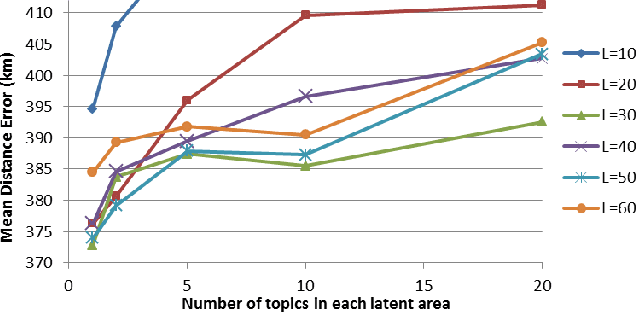
Real-time location inference of social media users is the fundamental of some spatial applications such as localized search and event detection. While tweet text is the most commonly used feature in location estimation, most of the prior works suffer from either the noise or the sparsity of textual features. In this paper, we aim to tackle these two problems. We use topic modeling as a building block to characterize the geographic topic variation and lexical variation so that "one-hot" encoding vectors will no longer be directly used. We also incorporate other features which can be extracted through the Twitter streaming API to overcome the noise problem. Experimental results show that our RATE algorithm outperforms several benchmark methods, both in the precision of region classification and the mean distance error of latitude and longitude regression.