 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepwise Penalization for Length-Efficient Chain-of-Thought Reasoning
Feb 27, 2026Large reasoning models improve with more test-time computation, but often overthink, producing unnecessarily long chains-of-thought that raise cost without improving accuracy. Prior reinforcement learning approaches typically rely on a single outcome reward with trajectory-level length penalties, which cannot distinguish essential from redundant reasoning steps and therefore yield blunt compression. Although recent work incorporates step-level signals, such as offline pruning, supervised data construction, or verifier-based intermediate rewards, reasoning length is rarely treated as an explicit step-level optimization objective during RL. We propose Step-wise Adaptive Penalization (SWAP), a fine-grained framework that allocates length reduction across steps based on intrinsic contribution. We estimate step importance from the model's on-policy log-probability improvement toward the correct answer, then treat excess length as a penalty mass redistributed to penalize low-importance steps more heavily while preserving high-importance reasoning. We optimize with a unified outcome-process advantage within group-relative policy optimization. Extensive experiments demonstrate that SWAP reduces reasoning length by 64.3% on average while improving accuracy by 5.7% relative to the base model.
100-LongBench: Are de facto Long-Context Benchmarks Literally Evaluating Long-Context Ability?
May 25, 2025



Long-context capability is considered one of the most important abilities of LLMs, as a truly long context-capable LLM enables users to effortlessly process many originally exhausting tasks -- e.g., digesting a long-form document to find answers vs. directly asking an LLM about it. However, existing real-task-based long-context evaluation benchmarks have two major shortcomings. First, benchmarks like LongBench often do not provide proper metrics to separate long-context performance from the model's baseline ability, making cross-model comparison unclear. Second, such benchmarks are usually constructed with fixed input lengths, which limits their applicability across different models and fails to reveal when a model begins to break down. To address these issues, we introduce a length-controllable long-context benchmark and a novel metric that disentangles baseline knowledge from true long-context capabilities. Experiments demonstrate the superiority of our approach in effectively evaluating LLMs.
Longer Context, Deeper Thinking: Uncovering the Role of Long-Context Ability in Reasoning
May 22, 2025Recent language models exhibit strong reasoning capabilities, yet the influence of long-context capacity on reasoning remains underexplored. In this work, we hypothesize that current limitations in reasoning stem, in part, from insufficient long-context capacity, motivated by empirical observations such as (1) higher context window length often leads to stronger reasoning performance, and (2) failed reasoning cases resemble failed long-context cases. To test this hypothesis, we examine whether enhancing a model's long-context ability before Supervised Fine-Tuning (SFT) leads to improved reasoning performance. Specifically, we compared models with identical architectures and fine-tuning data but varying levels of long-context capacity. Our results reveal a consistent trend: models with stronger long-context capacity achieve significantly higher accuracy on reasoning benchmarks after SFT. Notably, these gains persist even on tasks with short input lengths, indicating that long-context training offers generalizable benefits for reasoning performance. These findings suggest that long-context modeling is not just essential for processing lengthy inputs, but also serves as a critical foundation for reasoning. We advocate for treating long-context capacity as a first-class objective in the design of future language models.
END: Early Noise Dropping for Efficient and Effective Context Denoising
Feb 26, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, they are often distracted by irrelevant or noisy context in input sequences that degrades output quality. This problem affects both long- and short-context scenarios, such as retrieval-augmented generation, table question-answering, and in-context learning. We reveal that LLMs can implicitly identify whether input sequences contain useful information at early layers, prior to token generation. Leveraging this insight, we introduce Early Noise Dropping (\textsc{END}), a novel approach to mitigate this issue without requiring fine-tuning the LLMs. \textsc{END} segments input sequences into chunks and employs a linear prober on the early layers of LLMs to differentiate between informative and noisy chunks. By discarding noisy chunks early in the process, \textsc{END} preserves critical information, reduces distraction, and lowers computational overhead. Extensive experiments demonstrate that \textsc{END} significantly improves both performance and efficiency across different LLMs on multiple evaluation datasets. Furthermore, by investigating LLMs' implicit understanding to the input with the prober, this work also deepens understanding of how LLMs do reasoning with contexts internally.
Thinking Preference Optimization
Feb 17, 2025Supervised Fine-Tuning (SFT) has been a go-to and effective method for enhancing long chain-of-thought (CoT) reasoning in relatively small LLMs by fine-tuning them with long CoT responses from larger LLMs. To continually improve reasoning abilities, we can either collect new high-quality long CoT reasoning SFT data or repeatedly train on existing SFT datasets. However, acquiring new long CoT SFT data is costly and limited, while repeated training often results in a performance plateau or decline. To further boost the performance with the SFT data, we propose Thinking Preference Optimization (ThinkPO), a simple yet effective post-SFT method that enhances long CoT reasoning without requiring new long CoT responses. Instead, ThinkPO utilizes readily available or easily obtainable short CoT reasoning responses as rejected answers and long CoT responses as chosen answers for the same question. It then applies direct preference optimization to encourage the model to favor longer reasoning outputs. Experiments show that ThinkPO further improves the reasoning performance of SFT-ed models, e.g. it increases math reasoning accuracy of SFT-ed models by 8.6% and output length by 25.9%. Notably, ThinkPO is capable of continually boosting the performance of the publicly distilled SFT model, e.g., increasing the official DeepSeek-R1-Distill-Qwen-7B's performance on MATH500 from 87.4% to 91.2%.
Gradient Rewiring for Editable Graph Neural Network Training
Oct 21, 2024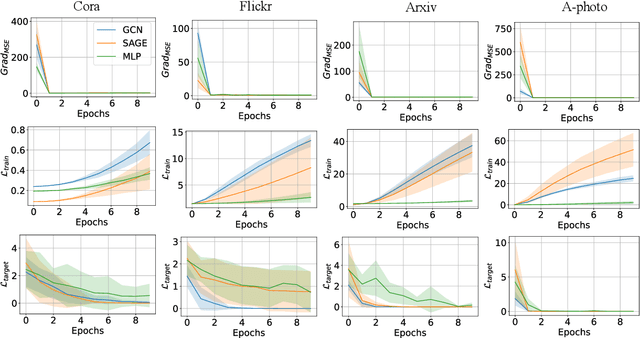
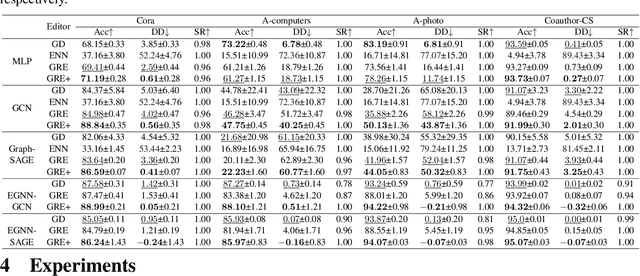
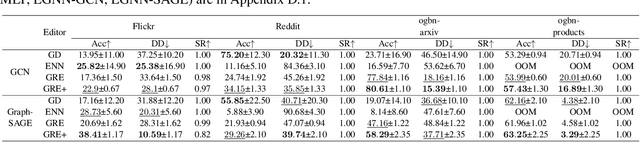
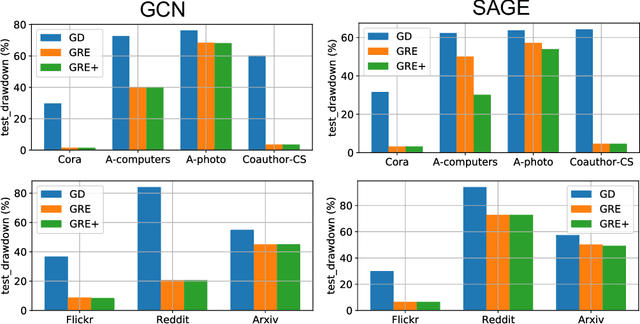
Deep neural networks are ubiquitously adopted in many applications, such as computer vision, natural language processing, and graph analytics. However, well-trained neural networks can make prediction errors after deployment as the world changes. \textit{Model editing} involves updating the base model to correct prediction errors with less accessible training data and computational resources. Despite recent advances in model editors in computer vision and natural language processing, editable training in graph neural networks (GNNs) is rarely explored. The challenge with editable GNN training lies in the inherent information aggregation across neighbors, which can lead model editors to affect the predictions of other nodes unintentionally. In this paper, we first observe the gradient of cross-entropy loss for the target node and training nodes with significant inconsistency, which indicates that directly fine-tuning the base model using the loss on the target node deteriorates the performance on training nodes. Motivated by the gradient inconsistency observation, we propose a simple yet effective \underline{G}radient \underline{R}ewiring method for \underline{E}ditable graph neural network training, named \textbf{GRE}. Specifically, we first store the anchor gradient of the loss on training nodes to preserve the locality. Subsequently, we rewire the gradient of the loss on the target node to preserve performance on the training node using anchor gradient. Experiments demonstrate the effectiveness of GRE on various model architectures and graph datasets in terms of multiple editing situations. The source code is available at \url{https://github.com/zhimengj0326/Gradient_rewiring_editing}
Taylor Unswift: Secured Weight Release for Large Language Models via Taylor Expansion
Oct 06, 2024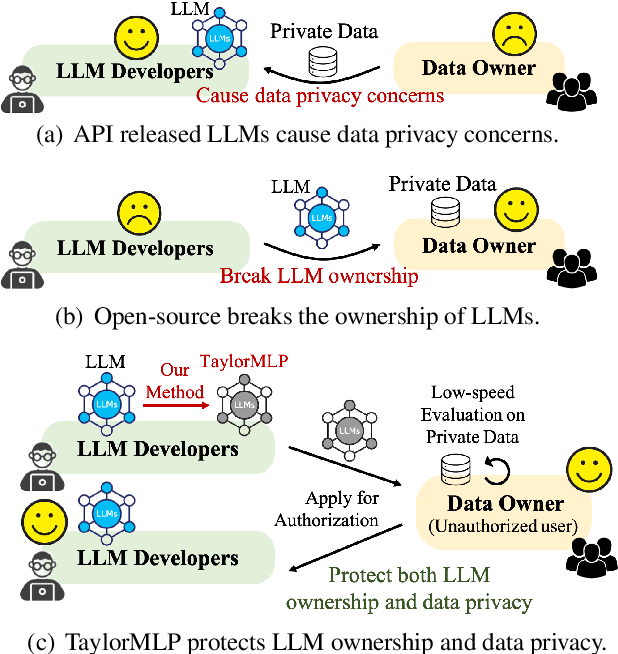
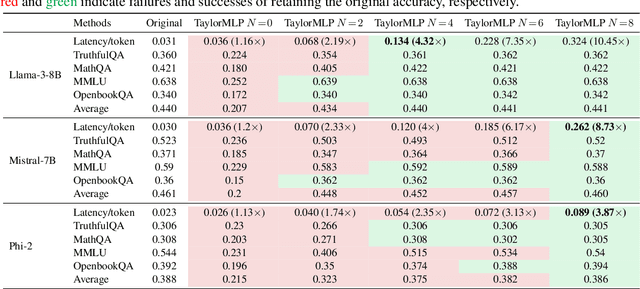
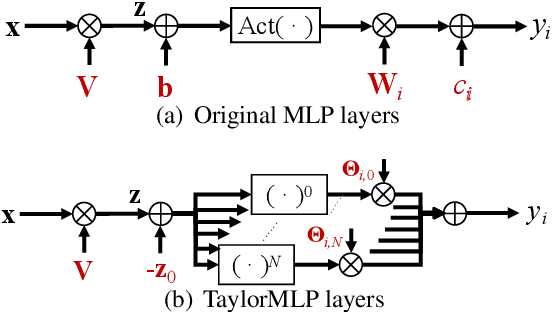

Ensuring the security of released large language models (LLMs) poses a significant dilemma, as existing mechanisms either compromise ownership rights or raise data privacy concerns. To address this dilemma, we introduce TaylorMLP to protect the ownership of released LLMs and prevent their abuse. Specifically, TaylorMLP preserves the ownership of LLMs by transforming the weights of LLMs into parameters of Taylor-series. Instead of releasing the original weights, developers can release the Taylor-series parameters with users, thereby ensuring the security of LLMs. Moreover, TaylorMLP can prevent abuse of LLMs by adjusting the generation speed. It can induce low-speed token generation for the protected LLMs by increasing the terms in the Taylor-series. This intentional delay helps LLM developers prevent potential large-scale unauthorized uses of their models. Empirical experiments across five datasets and three LLM architectures demonstrate that TaylorMLP induces over 4x increase in latency, producing the tokens precisely matched with original LLMs. Subsequent defensive experiments further confirm that TaylorMLP effectively prevents users from reconstructing the weight values based on downstream datasets.
KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches
Jul 01, 2024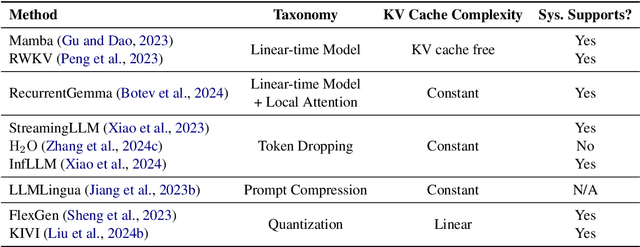
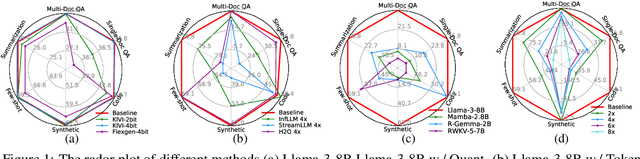
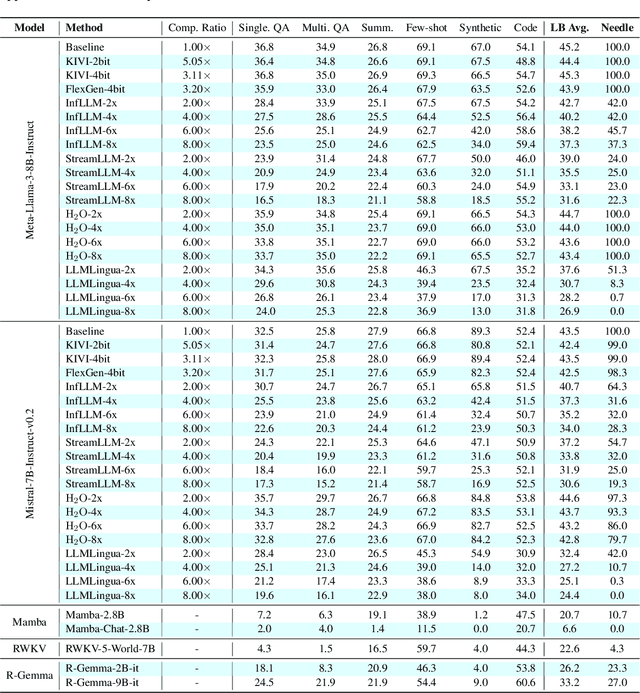
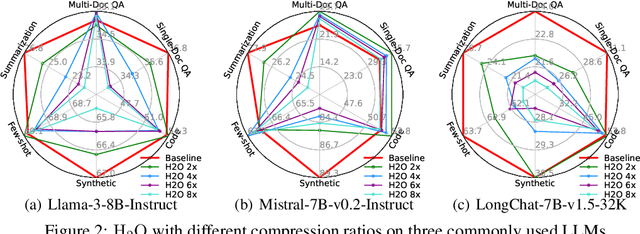
Long context capability is a crucial competency for large language models (LLMs) as it mitigates the human struggle to digest long-form texts. This capability enables complex task-solving scenarios such as book summarization, code assistance, and many more tasks that are traditionally manpower-intensive. However, transformer-based LLMs face significant challenges with long context input due to the growing size of the KV cache and the intrinsic complexity of attending to extended inputs; where multiple schools of efficiency-driven approaches -- such as KV cache quantization, token dropping, prompt compression, linear-time sequence models, and hybrid architectures -- have been proposed to produce efficient yet long context-capable models. Despite these advancements, no existing work has comprehensively benchmarked these methods in a reasonably aligned environment. In this work, we fill this gap by providing a taxonomy of current methods and evaluating 10+ state-of-the-art approaches across seven categories of long context tasks. Our work reveals numerous previously unknown phenomena and offers insights -- as well as a friendly workbench -- for the future development of long context-capable LLMs. The source code will be available at https://github.com/henryzhongsc/longctx_bench
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Feb 05, 2024



Efficiently serving large language models (LLMs) requires batching many requests together to reduce the cost per request. Yet, the key-value (KV) cache, which stores attention keys and values to avoid re-computations, significantly increases memory demands and becomes the new bottleneck in speed and memory usage. This memory demand increases with larger batch sizes and longer context lengths. Additionally, the inference speed is limited by the size of KV cache, as the GPU's SRAM must load the entire KV cache from the main GPU memory for each token generated, causing the computational core to be idle during this process. A straightforward and effective solution to reduce KV cache size is quantization, which decreases the total bytes taken by KV cache. However, there is a lack of in-depth studies that explore the element distribution of KV cache to understand the hardness and limitation of KV cache quantization. To fill the gap, we conducted a comprehensive study on the element distribution in KV cache of popular LLMs. Our findings indicate that the key cache should be quantized per-channel, i.e., group elements along the channel dimension and quantize them together. In contrast, the value cache should be quantized per-token. From this analysis, we developed a tuning-free 2bit KV cache quantization algorithm, named KIVI. With the hardware-friendly implementation, KIVI can enable Llama (Llama-2), Falcon, and Mistral models to maintain almost the same quality while using $\mathbf{2.6\times}$ less peak memory usage (including the model weight). This reduction in memory usage enables up to $\mathbf{4\times}$ larger batch size, bringing $\mathbf{2.35\times \sim 3.47\times}$ throughput on real LLM inference workload. The source code is available at https://github.com/jy-yuan/KIVI.
LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
Jan 02, 2024This work elicits LLMs' inherent ability to handle long contexts without fine-tuning. The limited length of the training sequence during training may limit the application of Large Language Models (LLMs) on long input sequences for inference. In this work, we argue that existing LLMs themselves have inherent capabilities for handling long contexts. Based on this argument, we suggest extending LLMs' context window by themselves to fully utilize the inherent ability.We propose Self-Extend to stimulate LLMs' long context handling potential. The basic idea is to construct bi-level attention information: the group level and the neighbor level. The two levels are computed by the original model's self-attention, which means the proposed does not require any training. With only four lines of code modification, the proposed method can effortlessly extend existing LLMs' context window without any fine-tuning. We conduct comprehensive experiments and the results show that the proposed method can effectively extend existing LLMs' context window's length.