 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Illuminating LLM Coding Agents: Visual Analytics for Deeper Understanding and Enhancement
Aug 18, 2025Coding agents powered by large language models (LLMs) have gained traction for automating code generation through iterative problem-solving with minimal human involvement. Despite the emergence of various frameworks, e.g., LangChain, AutoML, and AIDE, ML scientists still struggle to effectively review and adjust the agents' coding process. The current approach of manually inspecting individual outputs is inefficient, making it difficult to track code evolution, compare coding iterations, and identify improvement opportunities. To address this challenge, we introduce a visual analytics system designed to enhance the examination of coding agent behaviors. Focusing on the AIDE framework, our system supports comparative analysis across three levels: (1) Code-Level Analysis, which reveals how the agent debugs and refines its code over iterations; (2) Process-Level Analysis, which contrasts different solution-seeking processes explored by the agent; and (3) LLM-Level Analysis, which highlights variations in coding behavior across different LLMs. By integrating these perspectives, our system enables ML scientists to gain a structured understanding of agent behaviors, facilitating more effective debugging and prompt engineering. Through case studies using coding agents to tackle popular Kaggle competitions, we demonstrate how our system provides valuable insights into the iterative coding process.
Visual Attention Exploration in Vision-Based Mamba Models
Feb 28, 2025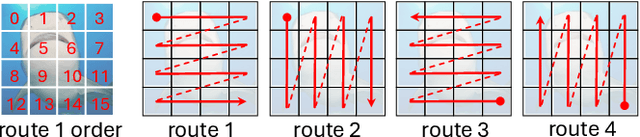
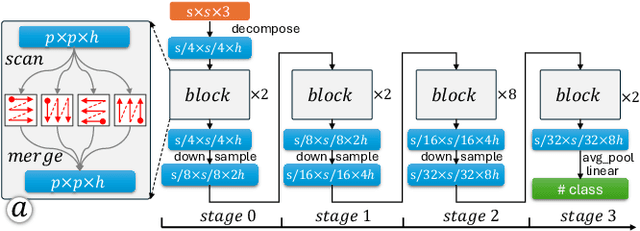
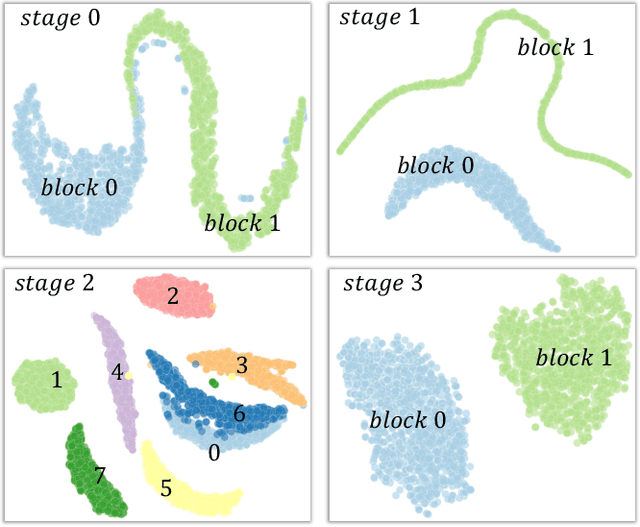
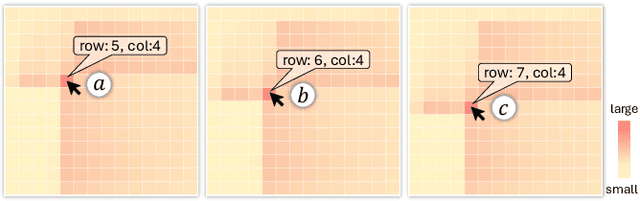
State space models (SSMs) have emerged as an efficient alternative to transformer-based models, offering linear complexity that scales better than transformers. One of the latest advances in SSMs, Mamba, introduces a selective scan mechanism that assigns trainable weights to input tokens, effectively mimicking the attention mechanism. Mamba has also been successfully extended to the vision domain by decomposing 2D images into smaller patches and arranging them as 1D sequences. However, it remains unclear how these patches interact with (or attend to) each other in relation to their original 2D spatial location. Additionally, the order used to arrange the patches into a sequence also significantly impacts their attention distribution. To better understand the attention between patches and explore the attention patterns, we introduce a visual analytics tool specifically designed for vision-based Mamba models. This tool enables a deeper understanding of how attention is distributed across patches in different Mamba blocks and how it evolves throughout a Mamba model. Using the tool, we also investigate the impact of different patch-ordering strategies on the learned attention, offering further insights into the model's behavior.
Personalized Layer Selection for Graph Neural Networks
Jan 24, 2025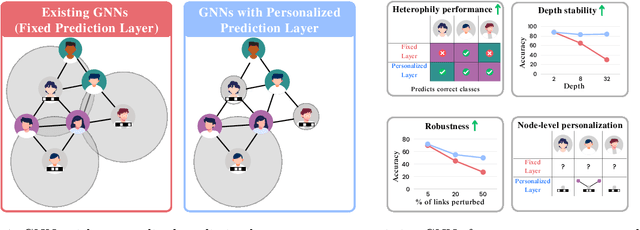
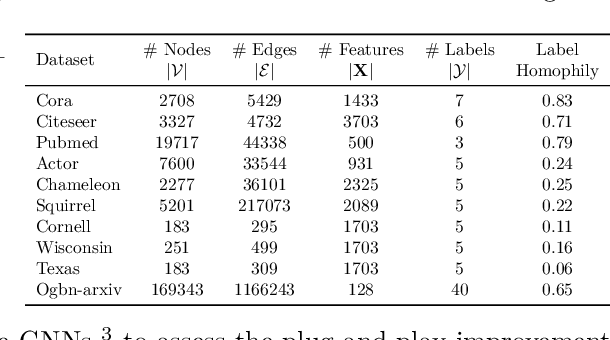
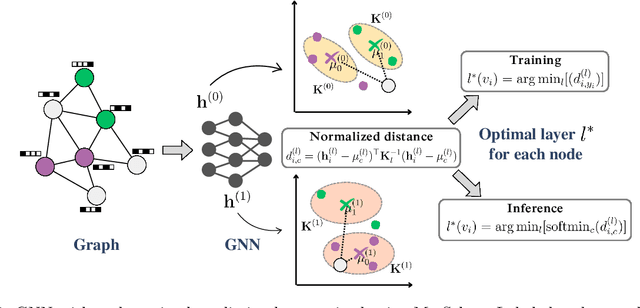
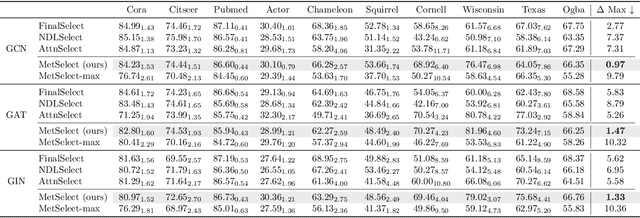
Graph Neural Networks (GNNs) combine node attributes over a fixed granularity of the local graph structure around a node to predict its label. However, different nodes may relate to a node-level property with a different granularity of its local neighborhood, and using the same level of smoothing for all nodes can be detrimental to their classification. In this work, we challenge the common fact that a single GNN layer can classify all nodes of a graph by training GNNs with a distinct personalized layer for each node. Inspired by metric learning, we propose a novel algorithm, MetSelect1, to select the optimal representation layer to classify each node. In particular, we identify a prototype representation of each class in a transformed GNN layer and then, classify using the layer where the distance is smallest to a class prototype after normalizing with that layer's variance. Results on 10 datasets and 3 different GNNs show that we significantly improve the node classification accuracy of GNNs in a plug-and-play manner. We also find that using variable layers for prediction enables GNNs to be deeper and more robust to poisoning attacks. We hope this work can inspire future works to learn more adaptive and personalized graph representations.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Dec 31, 2024



Large Language Models (LLMs) are becoming essential tools for various natural language processing tasks but often suffer from generating outdated or incorrect information. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating external, real-time information retrieval to ground LLM responses. However, the existing RAG systems frequently struggle with the quality of retrieval documents, as irrelevant or noisy documents degrade performance, increase computational overhead, and undermine response reliability. To tackle this problem, we propose Multi-Agent Filtering Retrieval-Augmented Generation (MAIN-RAG), a training-free RAG framework that leverages multiple LLM agents to collaboratively filter and score retrieved documents. Specifically, MAIN-RAG introduces an adaptive filtering mechanism that dynamically adjusts the relevance filtering threshold based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents. The proposed approach leverages inter-agent consensus to ensure robust document selection without requiring additional training data or fine-tuning. Experimental results across four QA benchmarks demonstrate that MAIN-RAG consistently outperforms traditional RAG approaches, achieving a 2-11% improvement in answer accuracy while reducing the number of irrelevant retrieved documents. Quantitative analysis further reveals that our approach achieves superior response consistency and answer accuracy over baseline methods, offering a competitive and practical alternative to training-based solutions.
Discrete-state Continuous-time Diffusion for Graph Generation
May 19, 2024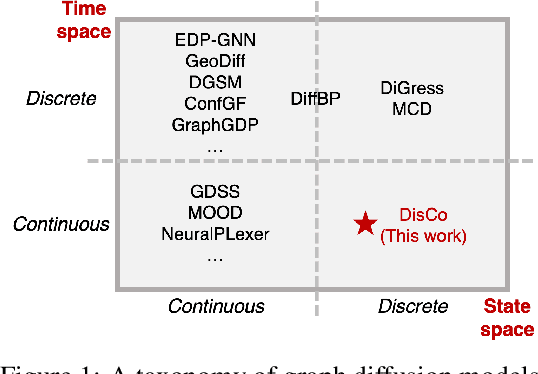
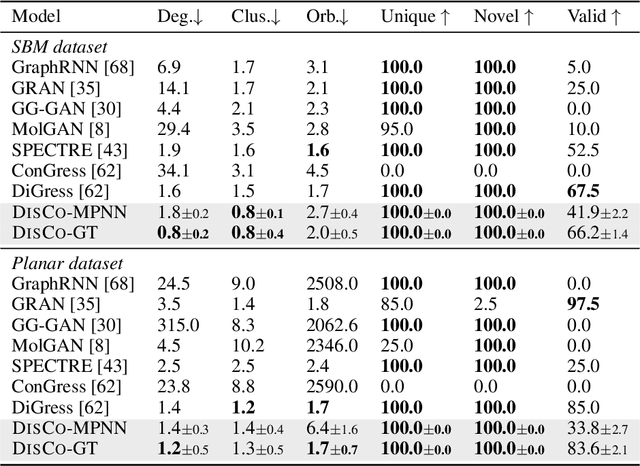

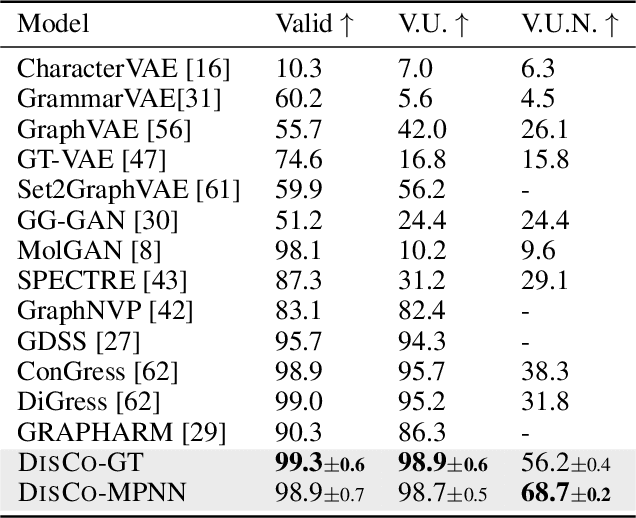
Graph is a prevalent discrete data structure, whose generation has wide applications such as drug discovery and circuit design. Diffusion generative models, as an emerging research focus, have been applied to graph generation tasks. Overall, according to the space of states and time steps, diffusion generative models can be categorized into discrete-/continuous-state discrete-/continuous-time fashions. In this paper, we formulate the graph diffusion generation in a discrete-state continuous-time setting, which has never been studied in previous graph diffusion models. The rationale of such a formulation is to preserve the discrete nature of graph-structured data and meanwhile provide flexible sampling trade-offs between sample quality and efficiency. Analysis shows that our training objective is closely related to generation quality, and our proposed generation framework enjoys ideal invariant/equivariant properties concerning the permutation of node ordering. Our proposed model shows competitive empirical performance against state-of-the-art graph generation solutions on various benchmarks and, at the same time, can flexibly trade off the generation quality and efficiency in the sampling phase.
Rethinking Personalized Federated Learning with Clustering-based Dynamic Graph Propagation
Jan 29, 2024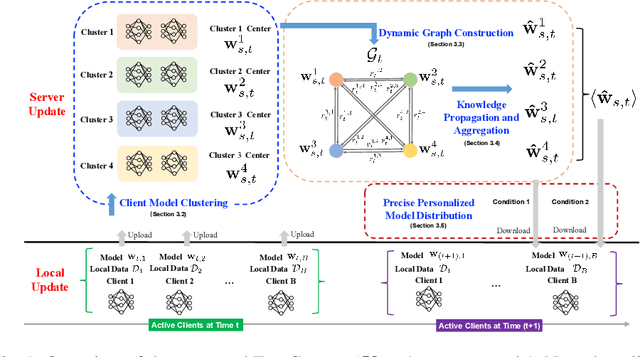
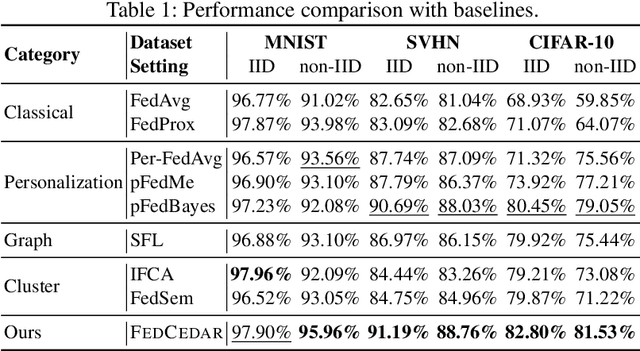

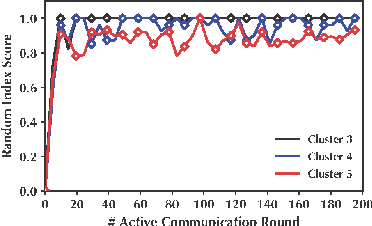
Most existing personalized federated learning approaches are based on intricate designs, which often require complex implementation and tuning. In order to address this limitation, we propose a simple yet effective personalized federated learning framework. Specifically, during each communication round, we group clients into multiple clusters based on their model training status and data distribution on the server side. We then consider each cluster center as a node equipped with model parameters and construct a graph that connects these nodes using weighted edges. Additionally, we update the model parameters at each node by propagating information across the entire graph. Subsequently, we design a precise personalized model distribution strategy to allow clients to obtain the most suitable model from the server side. We conduct experiments on three image benchmark datasets and create synthetic structured datasets with three types of typologies. Experimental results demonstrate the effectiveness of the proposed work.
Towards Mitigating Dimensional Collapse of Representations in Collaborative Filtering
Dec 29, 2023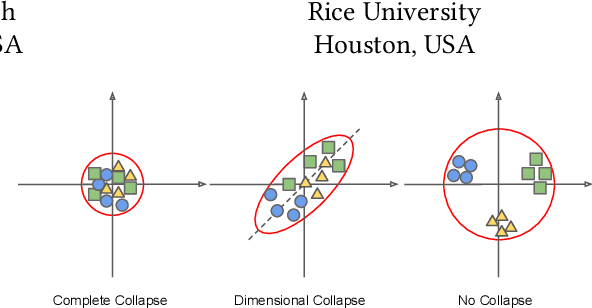
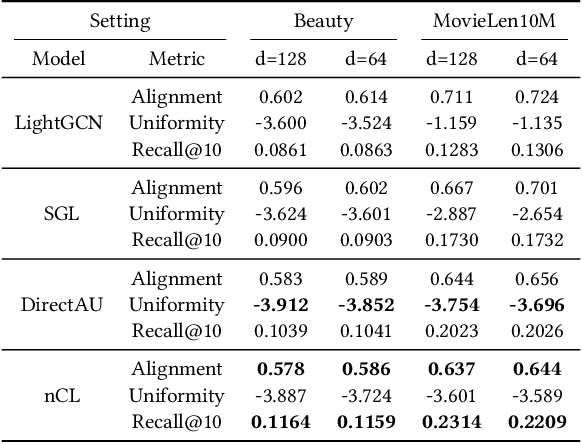
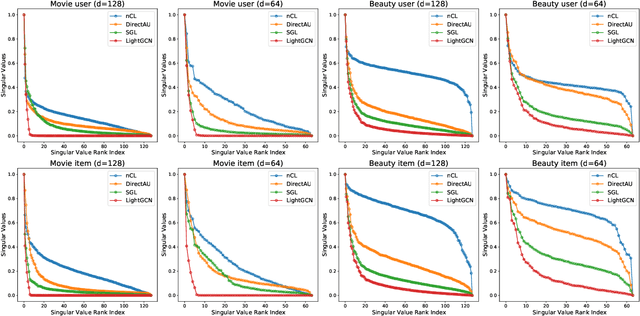
Contrastive Learning (CL) has shown promising performance in collaborative filtering. The key idea is to generate augmentation-invariant embeddings by maximizing the Mutual Information between different augmented views of the same instance. However, we empirically observe that existing CL models suffer from the \textsl{dimensional collapse} issue, where user/item embeddings only span a low-dimension subspace of the entire feature space. This suppresses other dimensional information and weakens the distinguishability of embeddings. Here we propose a non-contrastive learning objective, named nCL, which explicitly mitigates dimensional collapse of representations in collaborative filtering. Our nCL aims to achieve geometric properties of \textsl{Alignment} and \textsl{Compactness} on the embedding space. In particular, the alignment tries to push together representations of positive-related user-item pairs, while compactness tends to find the optimal coding length of user/item embeddings, subject to a given distortion. More importantly, our nCL does not require data augmentation nor negative sampling during training, making it scalable to large datasets. Experimental results demonstrate the superiority of our nCL.
Invariant Graph Transformer
Dec 15, 2023Rationale discovery is defined as finding a subset of the input data that maximally supports the prediction of downstream tasks. In graph machine learning context, graph rationale is defined to locate the critical subgraph in the given graph topology, which fundamentally determines the prediction results. In contrast to the rationale subgraph, the remaining subgraph is named the environment subgraph. Graph rationalization can enhance the model performance as the mapping between the graph rationale and prediction label is viewed as invariant, by assumption. To ensure the discriminative power of the extracted rationale subgraphs, a key technique named "intervention" is applied. The core idea of intervention is that given any changing environment subgraphs, the semantics from the rationale subgraph is invariant, which guarantees the correct prediction result. However, most, if not all, of the existing rationalization works on graph data develop their intervention strategies on the graph level, which is coarse-grained. In this paper, we propose well-tailored intervention strategies on graph data. Our idea is driven by the development of Transformer models, whose self-attention module provides rich interactions between input nodes. Based on the self-attention module, our proposed invariant graph Transformer (IGT) can achieve fine-grained, more specifically, node-level and virtual node-level intervention. Our comprehensive experiments involve 7 real-world datasets, and the proposed IGT shows significant performance advantages compared to 13 baseline methods.
Tackling Diverse Minorities in Imbalanced Classification
Aug 28, 2023



Imbalanced datasets are commonly observed in various real-world applications, presenting significant challenges in training classifiers. When working with large datasets, the imbalanced issue can be further exacerbated, making it exceptionally difficult to train classifiers effectively. To address the problem, over-sampling techniques have been developed to linearly interpolating data instances between minorities and their neighbors. However, in many real-world scenarios such as anomaly detection, minority instances are often dispersed diversely in the feature space rather than clustered together. Inspired by domain-agnostic data mix-up, we propose generating synthetic samples iteratively by mixing data samples from both minority and majority classes. It is non-trivial to develop such a framework, the challenges include source sample selection, mix-up strategy selection, and the coordination between the underlying model and mix-up strategies. To tackle these challenges, we formulate the problem of iterative data mix-up as a Markov decision process (MDP) that maps data attributes onto an augmentation strategy. To solve the MDP, we employ an actor-critic framework to adapt the discrete-continuous decision space. This framework is utilized to train a data augmentation policy and design a reward signal that explores classifier uncertainty and encourages performance improvement, irrespective of the classifier's convergence. We demonstrate the effectiveness of our proposed framework through extensive experiments conducted on seven publicly available benchmark datasets using three different types of classifiers. The results of these experiments showcase the potential and promise of our framework in addressing imbalanced datasets with diverse minorities.