 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangDA: Building Context-Awareness via Language for Domain Adaptive Semantic Segmentation
Mar 17, 2025Unsupervised domain adaptation for semantic segmentation (DASS) aims to transfer knowledge from a label-rich source domain to a target domain with no labels. Two key approaches in DASS are (1) vision-only approaches using masking or multi-resolution crops, and (2) language-based approaches that use generic class-wise prompts informed by target domain (e.g. "a {snowy} photo of a {class}"). However, the former is susceptible to noisy pseudo-labels that are biased to the source domain. The latter does not fully capture the intricate spatial relationships of objects -- key for dense prediction tasks. To this end, we propose LangDA. LangDA addresses these challenges by, first, learning contextual relationships between objects via VLM-generated scene descriptions (e.g. "a pedestrian is on the sidewalk, and the street is lined with buildings."). Second, LangDA aligns the entire image features with text representation of this context-aware scene caption and learns generalized representations via text. With this, LangDA sets the new state-of-the-art across three DASS benchmarks, outperforming existing methods by 2.6%, 1.4% and 3.9%.
Understanding Different Design Choices in Training Large Time Series Models
Jun 20, 2024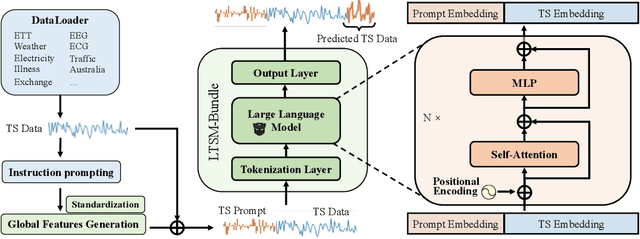
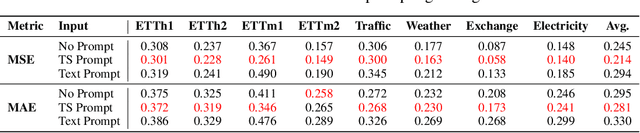

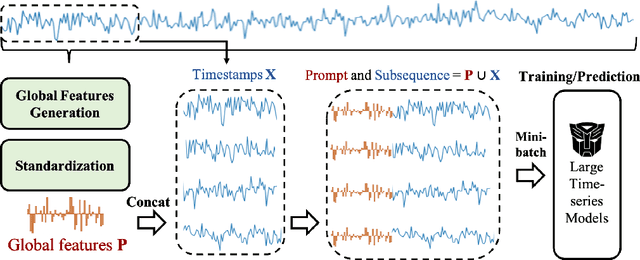
Inspired by Large Language Models (LLMs), Time Series Forecasting (TSF), a long-standing task in time series analysis, is undergoing a transition towards Large Time Series Models (LTSMs), aiming to train universal transformer-based models for TSF. However, training LTSMs on heterogeneous time series data poses unique challenges, including diverse frequencies, dimensions, and patterns across datasets. Recent endeavors have studied and evaluated various design choices aimed at enhancing LTSM training and generalization capabilities, spanning pre-processing techniques, model configurations, and dataset configurations. In this work, we comprehensively analyze these design choices and aim to identify the best practices for training LTSM. Moreover, we propose \emph{time series prompt}, a novel statistical prompting strategy tailored to time series data. Furthermore, based on the observations in our analysis, we introduce \texttt{LTSM-bundle}, which bundles the best design choices we have identified. Empirical results demonstrate that \texttt{LTSM-bundle} achieves superior zero-shot and few-shot performances compared to state-of-the-art LSTMs and traditional TSF methods on benchmark datasets.
CODA: Temporal Domain Generalization via Concept Drift Simulator
Oct 02, 2023In real-world applications, machine learning models often become obsolete due to shifts in the joint distribution arising from underlying temporal trends, a phenomenon known as the "concept drift". Existing works propose model-specific strategies to achieve temporal generalization in the near-future domain. However, the diverse characteristics of real-world datasets necessitate customized prediction model architectures. To this end, there is an urgent demand for a model-agnostic temporal domain generalization approach that maintains generality across diverse data modalities and architectures. In this work, we aim to address the concept drift problem from a data-centric perspective to bypass considering the interaction between data and model. Developing such a framework presents non-trivial challenges: (i) existing generative models struggle to generate out-of-distribution future data, and (ii) precisely capturing the temporal trends of joint distribution along chronological source domains is computationally infeasible. To tackle the challenges, we propose the COncept Drift simulAtor (CODA) framework incorporating a predicted feature correlation matrix to simulate future data for model training. Specifically, CODA leverages feature correlations to represent data characteristics at specific time points, thereby circumventing the daunting computational costs. Experimental results demonstrate that using CODA-generated data as training input effectively achieves temporal domain generalization across different model architectures.
DiscoverPath: A Knowledge Refinement and Retrieval System for Interdisciplinarity on Biomedical Research
Sep 04, 2023



The exponential growth in scholarly publications necessitates advanced tools for efficient article retrieval, especially in interdisciplinary fields where diverse terminologies are used to describe similar research. Traditional keyword-based search engines often fall short in assisting users who may not be familiar with specific terminologies. To address this, we present a knowledge graph-based paper search engine for biomedical research to enhance the user experience in discovering relevant queries and articles. The system, dubbed DiscoverPath, employs Named Entity Recognition (NER) and part-of-speech (POS) tagging to extract terminologies and relationships from article abstracts to create a KG. To reduce information overload, DiscoverPath presents users with a focused subgraph containing the queried entity and its neighboring nodes and incorporates a query recommendation system, enabling users to iteratively refine their queries. The system is equipped with an accessible Graphical User Interface that provides an intuitive visualization of the KG, query recommendations, and detailed article information, enabling efficient article retrieval, thus fostering interdisciplinary knowledge exploration. DiscoverPath is open-sourced at https://github.com/ynchuang/DiscoverPath.
Hessian-aware Quantized Node Embeddings for Recommendation
Sep 02, 2023


Graph Neural Networks (GNNs) have achieved state-of-the-art performance in recommender systems. Nevertheless, the process of searching and ranking from a large item corpus usually requires high latency, which limits the widespread deployment of GNNs in industry-scale applications. To address this issue, many methods compress user/item representations into the binary embedding space to reduce space requirements and accelerate inference. Also, they use the Straight-through Estimator (STE) to prevent vanishing gradients during back-propagation. However, the STE often causes the gradient mismatch problem, leading to sub-optimal results. In this work, we present the Hessian-aware Quantized GNN (HQ-GNN) as an effective solution for discrete representations of users/items that enable fast retrieval. HQ-GNN is composed of two components: a GNN encoder for learning continuous node embeddings and a quantized module for compressing full-precision embeddings into low-bit ones. Consequently, HQ-GNN benefits from both lower memory requirements and faster inference speeds compared to vanilla GNNs. To address the gradient mismatch problem in STE, we further consider the quantized errors and its second-order derivatives for better stability. The experimental results on several large-scale datasets show that HQ-GNN achieves a good balance between latency and performance.
Tackling Diverse Minorities in Imbalanced Classification
Aug 28, 2023



Imbalanced datasets are commonly observed in various real-world applications, presenting significant challenges in training classifiers. When working with large datasets, the imbalanced issue can be further exacerbated, making it exceptionally difficult to train classifiers effectively. To address the problem, over-sampling techniques have been developed to linearly interpolating data instances between minorities and their neighbors. However, in many real-world scenarios such as anomaly detection, minority instances are often dispersed diversely in the feature space rather than clustered together. Inspired by domain-agnostic data mix-up, we propose generating synthetic samples iteratively by mixing data samples from both minority and majority classes. It is non-trivial to develop such a framework, the challenges include source sample selection, mix-up strategy selection, and the coordination between the underlying model and mix-up strategies. To tackle these challenges, we formulate the problem of iterative data mix-up as a Markov decision process (MDP) that maps data attributes onto an augmentation strategy. To solve the MDP, we employ an actor-critic framework to adapt the discrete-continuous decision space. This framework is utilized to train a data augmentation policy and design a reward signal that explores classifier uncertainty and encourages performance improvement, irrespective of the classifier's convergence. We demonstrate the effectiveness of our proposed framework through extensive experiments conducted on seven publicly available benchmark datasets using three different types of classifiers. The results of these experiments showcase the potential and promise of our framework in addressing imbalanced datasets with diverse minorities.
Towards Assumption-free Bias Mitigation
Jul 09, 2023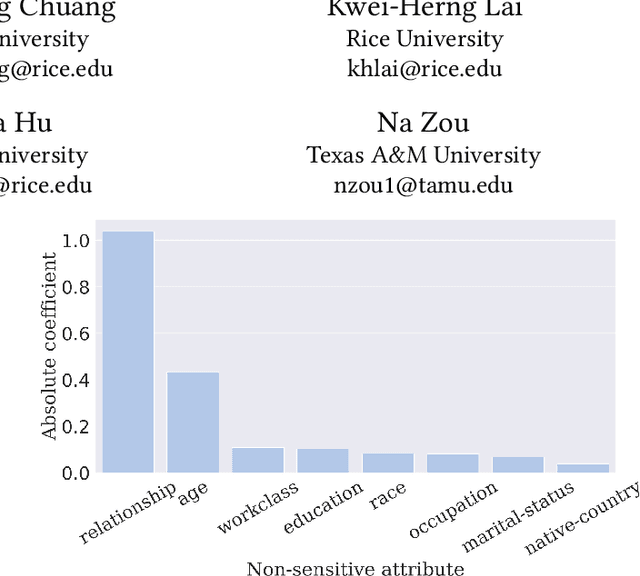
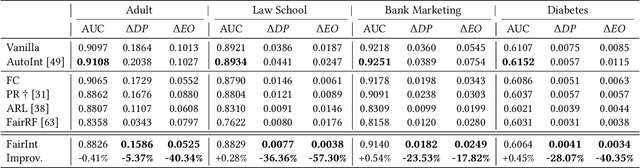
Despite the impressive prediction ability, machine learning models show discrimination towards certain demographics and suffer from unfair prediction behaviors. To alleviate the discrimination, extensive studies focus on eliminating the unequal distribution of sensitive attributes via multiple approaches. However, due to privacy concerns, sensitive attributes are often either unavailable or missing in real-world scenarios. Therefore, several existing works alleviate the bias without sensitive attributes. Those studies face challenges, either in inaccurate predictions of sensitive attributes or the need to mitigate unequal distribution of manually defined non-sensitive attributes related to bias. The latter requires strong assumptions about the correlation between sensitive and non-sensitive attributes. As data distribution and task goals vary, the strong assumption on non-sensitive attributes may not be valid and require domain expertise. In this work, we propose an assumption-free framework to detect the related attributes automatically by modeling feature interaction for bias mitigation. The proposed framework aims to mitigate the unfair impact of identified biased feature interactions. Experimental results on four real-world datasets demonstrate that our proposed framework can significantly alleviate unfair prediction behaviors by considering biased feature interactions.
Context-aware Domain Adaptation for Time Series Anomaly Detection
Apr 15, 2023
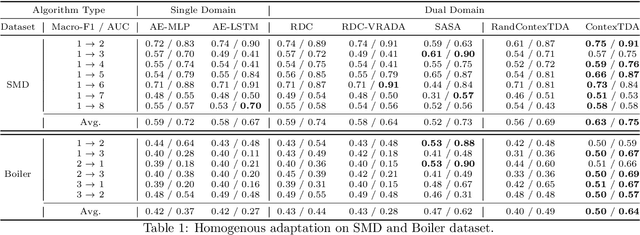
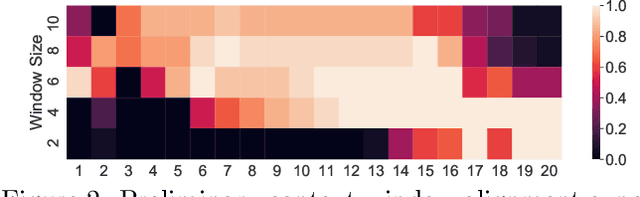

Time series anomaly detection is a challenging task with a wide range of real-world applications. Due to label sparsity, training a deep anomaly detector often relies on unsupervised approaches. Recent efforts have been devoted to time series domain adaptation to leverage knowledge from similar domains. However, existing solutions may suffer from negative knowledge transfer on anomalies due to their diversity and sparsity. Motivated by the empirical study of context alignment between two domains, we aim to transfer knowledge between two domains via adaptively sampling context information for two domains. This is challenging because it requires simultaneously modeling the complex in-domain temporal dependencies and cross-domain correlations while exploiting label information from the source domain. To this end, we propose a framework that combines context sampling and anomaly detection into a joint learning procedure. We formulate context sampling into the Markov decision process and exploit deep reinforcement learning to optimize the time series domain adaptation process via context sampling and design a tailored reward function to generate domain-invariant features that better align two domains for anomaly detection. Experiments on three public datasets show promise for knowledge transfer between two similar domains and two entirely different domains.
Data-centric Artificial Intelligence: A Survey
Apr 02, 2023Artificial Intelligence (AI) is making a profound impact in almost every domain. A vital enabler of its great success is the availability of abundant and high-quality data for building machine learning models. Recently, the role of data in AI has been significantly magnified, giving rise to the emerging concept of data-centric AI. The attention of researchers and practitioners has gradually shifted from advancing model design to enhancing the quality and quantity of the data. In this survey, we discuss the necessity of data-centric AI, followed by a holistic view of three general data-centric goals (training data development, inference data development, and data maintenance) and the representative methods. We also organize the existing literature from automation and collaboration perspectives, discuss the challenges, and tabulate the benchmarks for various tasks. We believe this is the first comprehensive survey that provides a global view of a spectrum of tasks across various stages of the data lifecycle. We hope it can help the readers efficiently grasp a broad picture of this field, and equip them with the techniques and further research ideas to systematically engineer data for building AI systems. A companion list of data-centric AI resources will be regularly updated on https://github.com/daochenzha/data-centric-AI
Data-centric AI: Perspectives and Challenges
Jan 12, 2023The role of data in building AI systems has recently been significantly magnified by the emerging concept of data-centric AI (DCAI), which advocates a fundamental shift from model advancements to ensuring data quality and reliability. Although our community has continuously invested efforts into enhancing data in different aspects, they are often isolated initiatives on specific tasks. To facilitate the collective initiative in our community and push forward DCAI, we draw a big picture and bring together three general missions: training data development, evaluation data development, and data maintenance. We provide a top-level discussion on representative DCAI tasks and share perspectives. Finally, we list open challenges to motivate future exploration.