 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident or Seek Stronger: Exploring Uncertainty-Based On-device LLM Routing From Benchmarking to Generalization
Feb 06, 2025Large language models (LLMs) are increasingly deployed and democratized on edge devices. To improve the efficiency of on-device deployment, small language models (SLMs) are often adopted due to their efficient decoding latency and reduced energy consumption. However, these SLMs often generate inaccurate responses when handling complex queries. One promising solution is uncertainty-based SLM routing, offloading high-stakes queries to stronger LLMs when resulting in low-confidence responses on SLM. This follows the principle of "If you lack confidence, seek stronger support" to enhance reliability. Relying on more powerful LLMs is yet effective but increases invocation costs. Therefore, striking a routing balance between efficiency and efficacy remains a critical challenge. Additionally, efficiently generalizing the routing strategy to new datasets remains under-explored. In this paper, we conduct a comprehensive investigation into benchmarking and generalization of uncertainty-driven routing strategies from SLMs to LLMs over 1500+ settings. Our findings highlight: First, uncertainty-correctness alignment in different uncertainty quantification (UQ) methods significantly impacts routing performance. Second, uncertainty distributions depend more on both the specific SLM and the chosen UQ method, rather than downstream data. Building on the insight, we propose a calibration data construction instruction pipeline and open-source a constructed hold-out set to enhance routing generalization on new downstream scenarios. The experimental results indicate calibration data effectively bootstraps routing performance without any new data.
Understanding Different Design Choices in Training Large Time Series Models
Jun 20, 2024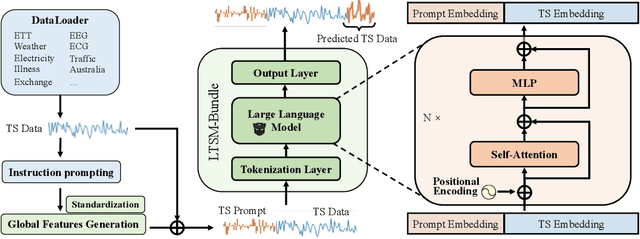
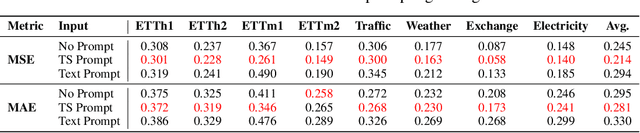

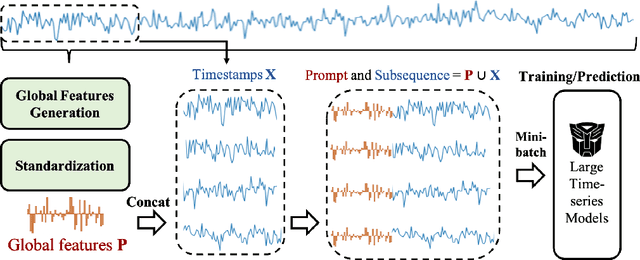
Inspired by Large Language Models (LLMs), Time Series Forecasting (TSF), a long-standing task in time series analysis, is undergoing a transition towards Large Time Series Models (LTSMs), aiming to train universal transformer-based models for TSF. However, training LTSMs on heterogeneous time series data poses unique challenges, including diverse frequencies, dimensions, and patterns across datasets. Recent endeavors have studied and evaluated various design choices aimed at enhancing LTSM training and generalization capabilities, spanning pre-processing techniques, model configurations, and dataset configurations. In this work, we comprehensively analyze these design choices and aim to identify the best practices for training LTSM. Moreover, we propose \emph{time series prompt}, a novel statistical prompting strategy tailored to time series data. Furthermore, based on the observations in our analysis, we introduce \texttt{LTSM-bundle}, which bundles the best design choices we have identified. Empirical results demonstrate that \texttt{LTSM-bundle} achieves superior zero-shot and few-shot performances compared to state-of-the-art LSTMs and traditional TSF methods on benchmark datasets.
Beyond Fairness: Age-Harmless Parkinson's Detection via Voice
Sep 23, 2023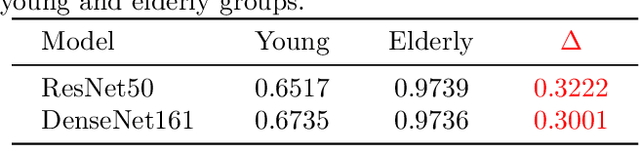
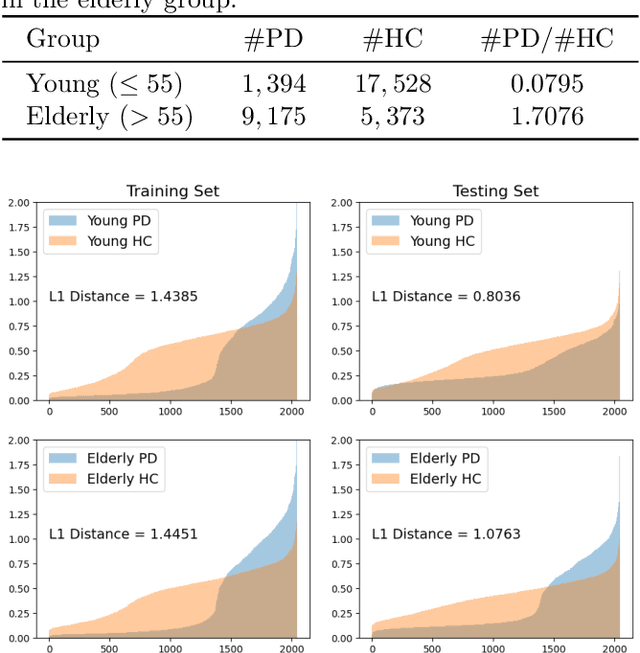
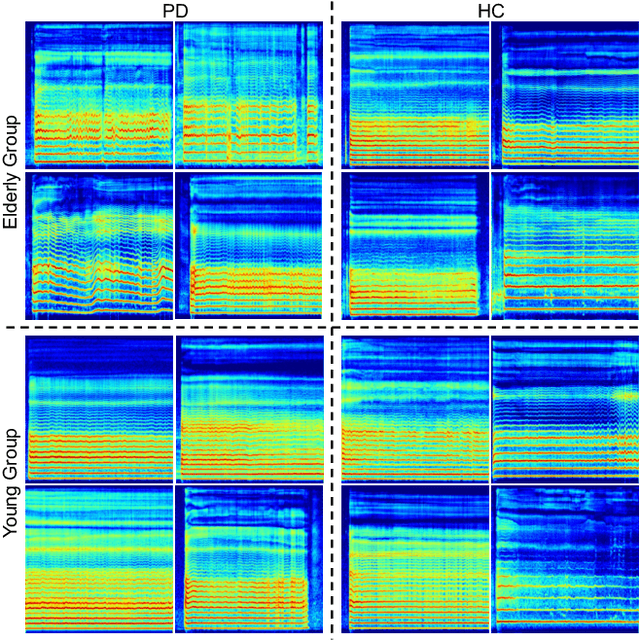
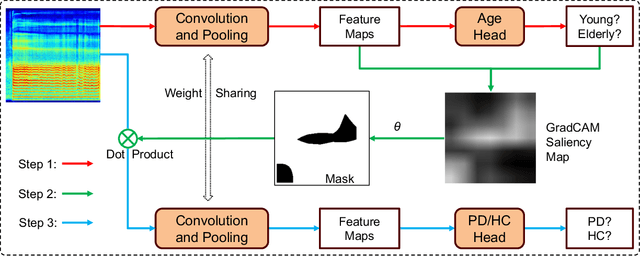
Parkinson's disease (PD), a neurodegenerative disorder, often manifests as speech and voice dysfunction. While utilizing voice data for PD detection has great potential in clinical applications, the widely used deep learning models currently have fairness issues regarding different ages of onset. These deep models perform well for the elderly group (age $>$ 55) but are less accurate for the young group (age $\leq$ 55). Through our investigation, the discrepancy between the elderly and the young arises due to 1) an imbalanced dataset and 2) the milder symptoms often seen in early-onset patients. However, traditional debiasing methods are impractical as they typically impair the prediction accuracy for the majority group while minimizing the discrepancy. To address this issue, we present a new debiasing method using GradCAM-based feature masking combined with ensemble models, ensuring that neither fairness nor accuracy is compromised. Specifically, the GradCAM-based feature masking selectively obscures age-related features in the input voice data while preserving essential information for PD detection. The ensemble models further improve the prediction accuracy for the minority (young group). Our approach effectively improves detection accuracy for early-onset patients without sacrificing performance for the elderly group. Additionally, we propose a two-step detection strategy for the young group, offering a practical risk assessment for potential early-onset PD patients.