 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLM Data Auditor: A Metric-oriented Survey on Quality and Trustworthiness in Evaluating Synthetic Data
Jan 27, 2026Large Language Models (LLMs) have emerged as powerful tools for generating data across various modalities. By transforming data from a scarce resource into a controllable asset, LLMs mitigate the bottlenecks imposed by the acquisition costs of real-world data for model training, evaluation, and system iteration. However, ensuring the high quality of LLM-generated synthetic data remains a critical challenge. Existing research primarily focuses on generation methodologies, with limited direct attention to the quality of the resulting data. Furthermore, most studies are restricted to single modalities, lacking a unified perspective across different data types. To bridge this gap, we propose the \textbf{LLM Data Auditor framework}. In this framework, we first describe how LLMs are utilized to generate data across six distinct modalities. More importantly, we systematically categorize intrinsic metrics for evaluating synthetic data from two dimensions: quality and trustworthiness. This approach shifts the focus from extrinsic evaluation, which relies on downstream task performance, to the inherent properties of the data itself. Using this evaluation system, we analyze the experimental evaluations of representative generation methods for each modality and identify substantial deficiencies in current evaluation practices. Based on these findings, we offer concrete recommendations for the community to improve the evaluation of data generation. Finally, the framework outlines methodologies for the practical application of synthetic data across different modalities.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Dec 31, 2024



Large Language Models (LLMs) are becoming essential tools for various natural language processing tasks but often suffer from generating outdated or incorrect information. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating external, real-time information retrieval to ground LLM responses. However, the existing RAG systems frequently struggle with the quality of retrieval documents, as irrelevant or noisy documents degrade performance, increase computational overhead, and undermine response reliability. To tackle this problem, we propose Multi-Agent Filtering Retrieval-Augmented Generation (MAIN-RAG), a training-free RAG framework that leverages multiple LLM agents to collaboratively filter and score retrieved documents. Specifically, MAIN-RAG introduces an adaptive filtering mechanism that dynamically adjusts the relevance filtering threshold based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents. The proposed approach leverages inter-agent consensus to ensure robust document selection without requiring additional training data or fine-tuning. Experimental results across four QA benchmarks demonstrate that MAIN-RAG consistently outperforms traditional RAG approaches, achieving a 2-11% improvement in answer accuracy while reducing the number of irrelevant retrieved documents. Quantitative analysis further reveals that our approach achieves superior response consistency and answer accuracy over baseline methods, offering a competitive and practical alternative to training-based solutions.
Assessing and Enhancing Large Language Models in Rare Disease Question-answering
Aug 15, 2024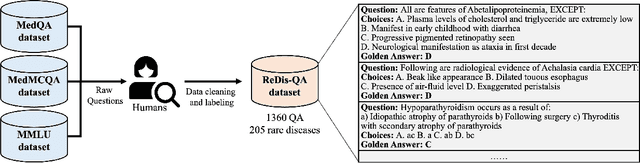

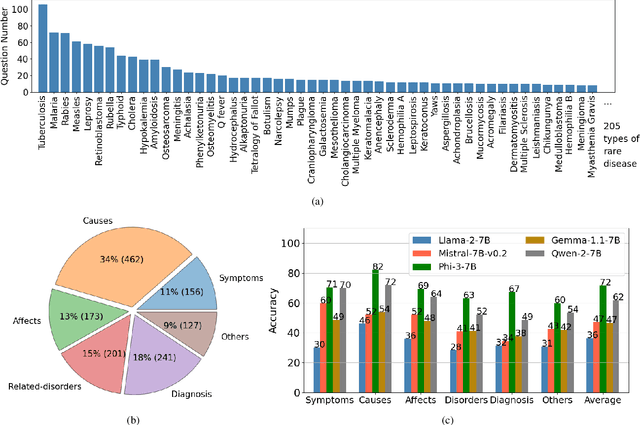
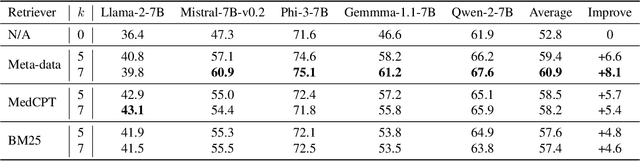
Despite the impressive capabilities of Large Language Models (LLMs) in general medical domains, questions remain about their performance in diagnosing rare diseases. To answer this question, we aim to assess the diagnostic performance of LLMs in rare diseases, and explore methods to enhance their effectiveness in this area. In this work, we introduce a rare disease question-answering (ReDis-QA) dataset to evaluate the performance of LLMs in diagnosing rare diseases. Specifically, we collected 1360 high-quality question-answer pairs within the ReDis-QA dataset, covering 205 rare diseases. Additionally, we annotated meta-data for each question, facilitating the extraction of subsets specific to any given disease and its property. Based on the ReDis-QA dataset, we benchmarked several open-source LLMs, revealing that diagnosing rare diseases remains a significant challenge for these models. To facilitate retrieval augmentation generation for rare disease diagnosis, we collect the first rare diseases corpus (ReCOP), sourced from the National Organization for Rare Disorders (NORD) database. Specifically, we split the report of each rare disease into multiple chunks, each representing a different property of the disease, including their overview, symptoms, causes, effects, related disorders, diagnosis, and standard therapies. This structure ensures that the information within each chunk aligns consistently with a question. Experiment results demonstrate that ReCOP can effectively improve the accuracy of LLMs on the ReDis-QA dataset by an average of 8%. Moreover, it significantly guides LLMs to generate trustworthy answers and explanations that can be traced back to existing literature.
Understanding Different Design Choices in Training Large Time Series Models
Jun 20, 2024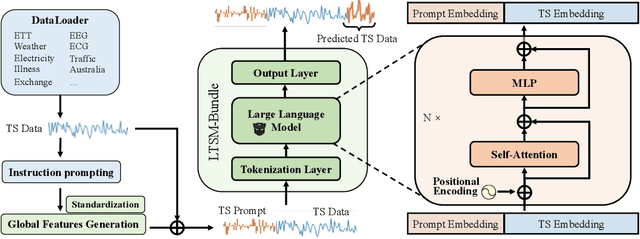
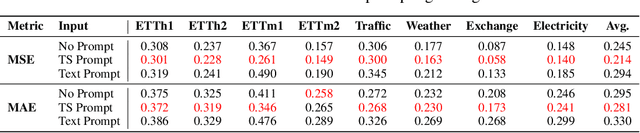

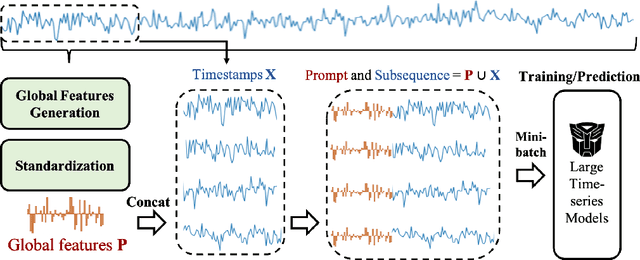
Inspired by Large Language Models (LLMs), Time Series Forecasting (TSF), a long-standing task in time series analysis, is undergoing a transition towards Large Time Series Models (LTSMs), aiming to train universal transformer-based models for TSF. However, training LTSMs on heterogeneous time series data poses unique challenges, including diverse frequencies, dimensions, and patterns across datasets. Recent endeavors have studied and evaluated various design choices aimed at enhancing LTSM training and generalization capabilities, spanning pre-processing techniques, model configurations, and dataset configurations. In this work, we comprehensively analyze these design choices and aim to identify the best practices for training LTSM. Moreover, we propose \emph{time series prompt}, a novel statistical prompting strategy tailored to time series data. Furthermore, based on the observations in our analysis, we introduce \texttt{LTSM-bundle}, which bundles the best design choices we have identified. Empirical results demonstrate that \texttt{LTSM-bundle} achieves superior zero-shot and few-shot performances compared to state-of-the-art LSTMs and traditional TSF methods on benchmark datasets.
Learning to Compress Prompt in Natural Language Formats
Feb 28, 2024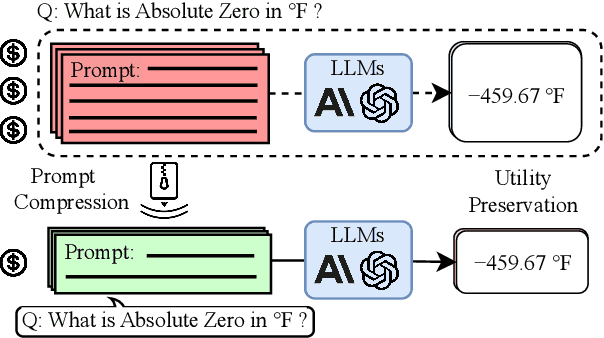

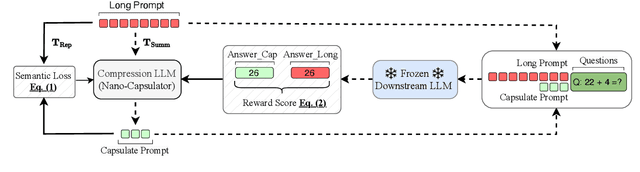
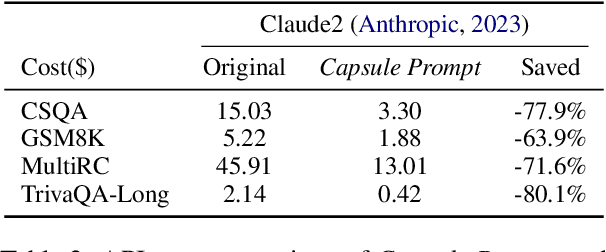
Large language models (LLMs) are great at processing multiple natural language processing tasks, but their abilities are constrained by inferior performance with long context, slow inference speed, and the high cost of computing the results. Deploying LLMs with precise and informative context helps users process large-scale datasets more effectively and cost-efficiently. Existing works rely on compressing long prompt contexts into soft prompts. However, soft prompt compression encounters limitations in transferability across different LLMs, especially API-based LLMs. To this end, this work aims to compress lengthy prompts in the form of natural language with LLM transferability. This poses two challenges: (i) Natural Language (NL) prompts are incompatible with back-propagation, and (ii) NL prompts lack flexibility in imposing length constraints. In this work, we propose a Natural Language Prompt Encapsulation (Nano-Capsulator) framework compressing original prompts into NL formatted Capsule Prompt while maintaining the prompt utility and transferability. Specifically, to tackle the first challenge, the Nano-Capsulator is optimized by a reward function that interacts with the proposed semantics preserving loss. To address the second question, the Nano-Capsulator is optimized by a reward function featuring length constraints. Experimental results demonstrate that the Capsule Prompt can reduce 81.4% of the original length, decrease inference latency up to 4.5x, and save 80.1% of budget overheads while providing transferability across diverse LLMs and different datasets.
Large Language Models As Faithful Explainers
Feb 07, 2024Large Language Models (LLMs) have recently become proficient in addressing complex tasks by utilizing their rich internal knowledge and reasoning ability. Consequently, this complexity hinders traditional input-focused explanation algorithms for explaining the complex decision-making processes of LLMs. Recent advancements have thus emerged for self-explaining their predictions through a single feed-forward inference in a natural language format. However, natural language explanations are often criticized for lack of faithfulness since these explanations may not accurately reflect the decision-making behaviors of the LLMs. In this work, we introduce a generative explanation framework, xLLM, to improve the faithfulness of the explanations provided in natural language formats for LLMs. Specifically, we propose an evaluator to quantify the faithfulness of natural language explanation and enhance the faithfulness by an iterative optimization process of xLLM, with the goal of maximizing the faithfulness scores. Experiments conducted on three NLU datasets demonstrate that xLLM can significantly improve the faithfulness of generated explanations, which are in alignment with the behaviors of LLMs.
LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning
Jan 02, 2024This work elicits LLMs' inherent ability to handle long contexts without fine-tuning. The limited length of the training sequence during training may limit the application of Large Language Models (LLMs) on long input sequences for inference. In this work, we argue that existing LLMs themselves have inherent capabilities for handling long contexts. Based on this argument, we suggest extending LLMs' context window by themselves to fully utilize the inherent ability.We propose Self-Extend to stimulate LLMs' long context handling potential. The basic idea is to construct bi-level attention information: the group level and the neighbor level. The two levels are computed by the original model's self-attention, which means the proposed does not require any training. With only four lines of code modification, the proposed method can effortlessly extend existing LLMs' context window without any fine-tuning. We conduct comprehensive experiments and the results show that the proposed method can effectively extend existing LLMs' context window's length.
LETA: Learning Transferable Attribution for Generic Vision Explainer
Dec 23, 2023Explainable machine learning significantly improves the transparency of deep neural networks~(DNN). However, existing work is constrained to explaining the behavior of individual model predictions, and lacks the ability to transfer the explanation across various models and tasks. This limitation results in explaining various tasks being time- and resource-consuming. To address this problem, we develop a pre-trained, DNN-based, generic explainer on large-scale image datasets, and leverage its transferability to explain various vision models for downstream tasks. In particular, the pre-training of generic explainer focuses on LEarning Transferable Attribution (LETA). The transferable attribution takes advantage of the versatile output of the target backbone encoders to comprehensively encode the essential attribution for explaining various downstream tasks. LETA guides the pre-training of the generic explainer towards the transferable attribution, and introduces a rule-based adaptation of the transferable attribution for explaining downstream tasks, without the need for additional training on downstream data. Theoretical analysis demonstrates that the pre-training of LETA enables minimizing the explanation error bound aligned with the conditional $\mathcal{V}$-information on downstream tasks. Empirical studies involve explaining three different architectures of vision models across three diverse downstream datasets. The experiment results indicate LETA is effective in explaining these tasks without the need for additional training on the data of downstream tasks.
CODA: Temporal Domain Generalization via Concept Drift Simulator
Oct 02, 2023In real-world applications, machine learning models often become obsolete due to shifts in the joint distribution arising from underlying temporal trends, a phenomenon known as the "concept drift". Existing works propose model-specific strategies to achieve temporal generalization in the near-future domain. However, the diverse characteristics of real-world datasets necessitate customized prediction model architectures. To this end, there is an urgent demand for a model-agnostic temporal domain generalization approach that maintains generality across diverse data modalities and architectures. In this work, we aim to address the concept drift problem from a data-centric perspective to bypass considering the interaction between data and model. Developing such a framework presents non-trivial challenges: (i) existing generative models struggle to generate out-of-distribution future data, and (ii) precisely capturing the temporal trends of joint distribution along chronological source domains is computationally infeasible. To tackle the challenges, we propose the COncept Drift simulAtor (CODA) framework incorporating a predicted feature correlation matrix to simulate future data for model training. Specifically, CODA leverages feature correlations to represent data characteristics at specific time points, thereby circumventing the daunting computational costs. Experimental results demonstrate that using CODA-generated data as training input effectively achieves temporal domain generalization across different model architectures.
GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length
Oct 01, 2023



The evolving sophistication and intricacies of Large Language Models (LLMs) yield unprecedented advancements, yet they simultaneously demand considerable computational resources and incur significant costs. To alleviate these challenges, this paper introduces a novel, simple, and effective method named ``\growlength'' to accelerate the pretraining process of LLMs. Our method progressively increases the training length throughout the pretraining phase, thereby mitigating computational costs and enhancing efficiency. For instance, it begins with a sequence length of 128 and progressively extends to 4096. This approach enables models to process a larger number of tokens within limited time frames, potentially boosting their performance. In other words, the efficiency gain is derived from training with shorter sequences optimizing the utilization of resources. Our extensive experiments with various state-of-the-art LLMs have revealed that models trained using our method not only converge more swiftly but also exhibit superior performance metrics compared to those trained with existing methods. Furthermore, our method for LLMs pretraining acceleration does not require any additional engineering efforts, making it a practical solution in the realm of LLMs.