 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset-Level Metrics Attenuate Non-Determinism: A Fine-Grained Non-Determinism Evaluation in Diffusion Language Models
Apr 15, 2026Diffusion language models (DLMs) have emerged as a promising paradigm for large language models (LLMs), yet the non-deterministic behavior of DLMs remains poorly understood. The existing non-determinism evaluations for LLMs predominantly rely on dataset-level metrics under fixed inference configurations, providing limited insight into how model behavior varies across runs and evaluation conditions. In this work, we show that dataset-level metrics systematically attenuate non-determinism in diffusion language models by aggregating sample-level prediction quality across different runs. As a result, configurations with similar aggregate performance can exhibit substantially different behaviors on individual inputs, leaving fine-grained instability and distinct error patterns uncharacterized. To address this limitation, we conduct a fine-grained evaluation of non-determinism based on sample-level prediction differences across a range of model-related factors-including guidance scale, diffusion steps, and Monte Carlo sampling-as well as system-related factors such as batch size, hardware, and numerical precision. Our analysis reveals that non-determinism in DLMs is pervasive and structured, with code generation exhibiting markedly higher sensitivity to factor-level choices than question answering. To attribute sources of non-determinism evaluation, we introduce Factor Variance Attribution (FVA), a cross-factor analysis metric that decomposes observed non-determinism into variance attributable to different evaluation factor settings. Our findings highlight the need for fine-grained, factor-aware evaluation to enable reliable non-determinism assessment of diffusion language models.
The LLM Data Auditor: A Metric-oriented Survey on Quality and Trustworthiness in Evaluating Synthetic Data
Jan 27, 2026Large Language Models (LLMs) have emerged as powerful tools for generating data across various modalities. By transforming data from a scarce resource into a controllable asset, LLMs mitigate the bottlenecks imposed by the acquisition costs of real-world data for model training, evaluation, and system iteration. However, ensuring the high quality of LLM-generated synthetic data remains a critical challenge. Existing research primarily focuses on generation methodologies, with limited direct attention to the quality of the resulting data. Furthermore, most studies are restricted to single modalities, lacking a unified perspective across different data types. To bridge this gap, we propose the \textbf{LLM Data Auditor framework}. In this framework, we first describe how LLMs are utilized to generate data across six distinct modalities. More importantly, we systematically categorize intrinsic metrics for evaluating synthetic data from two dimensions: quality and trustworthiness. This approach shifts the focus from extrinsic evaluation, which relies on downstream task performance, to the inherent properties of the data itself. Using this evaluation system, we analyze the experimental evaluations of representative generation methods for each modality and identify substantial deficiencies in current evaluation practices. Based on these findings, we offer concrete recommendations for the community to improve the evaluation of data generation. Finally, the framework outlines methodologies for the practical application of synthetic data across different modalities.
Cleansing the Artificial Mind: A Self-Reflective Detoxification Framework for Large Language Models
Jan 16, 2026Recent breakthroughs in Large Language Models (LLMs) have revealed remarkable generative capabilities and emerging self-regulatory mechanisms, including self-correction and self-rewarding. However, current detoxification techniques rarely exploit these built-in abilities; instead, they rely on external modules, labor-intensive data annotation, or human intervention --factors that hinder scalability and consistency. In this paper, we introduce a fully self-reflective detoxification framework that harnesses the inherent capacities of LLMs to detect, correct toxic content, and refine LLMs without external modules and data annotation. Specifically, we propose a Toxic Signal Detector --an internal self-identification mechanism, coupled with a systematic intervention process to transform toxic text into its non-toxic counterpart. This iterative procedure yields a contrastive detoxification dataset used to fine-tune the model, enhancing its ability for safe and coherent text generation. Experiments on benchmark datasets such as DetoxLLM and ParaDetox show that our method achieves better detoxification performance than state-of-the-art methods while preserving semantic fidelity. By obviating the need for human intervention or external components, this paper reveals the intrinsic self-detoxification ability of LLMs, offering a consistent and effective approach for mitigating harmful content generation. Ultimately, our findings underscore the potential for truly self-regulated language models, paving the way for more responsible and ethically guided text generation systems.
TransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
A Closer Look on Memorization in Tabular Diffusion Model: A Data-Centric Perspective
May 28, 2025Diffusion models have shown strong performance in generating high-quality tabular data, but they carry privacy risks by reproducing exact training samples. While prior work focuses on dataset-level augmentation to reduce memorization, little is known about which individual samples contribute most. We present the first data-centric study of memorization dynamics in tabular diffusion models. We quantify memorization for each real sample based on how many generated samples are flagged as replicas, using a relative distance ratio. Our empirical analysis reveals a heavy-tailed distribution of memorization counts: a small subset of samples contributes disproportionately to leakage, confirmed via sample-removal experiments. To understand this, we divide real samples into top- and non-top-memorized groups and analyze their training-time behaviors. We track when each sample is first memorized and monitor per-epoch memorization intensity (AUC). Memorized samples are memorized slightly earlier and show stronger signals in early training. Based on these insights, we propose DynamicCut, a two-stage, model-agnostic mitigation method: (a) rank samples by epoch-wise intensity, (b) prune a tunable top fraction, and (c) retrain on the filtered dataset. Across multiple tabular datasets and models, DynamicCut reduces memorization with minimal impact on data diversity and downstream performance. It also complements augmentation-based defenses. Furthermore, DynamicCut enables cross-model transferability: high-ranked samples identified from one model (e.g., a diffusion model) are also effective for reducing memorization when removed from others, such as GANs and VAEs.
Towards Efficient Large Scale Spatial-Temporal Time Series Forecasting via Improved Inverted Transformers
Mar 13, 2025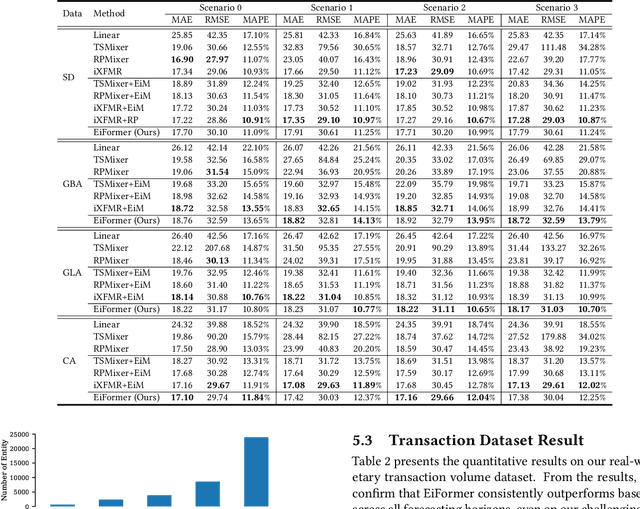
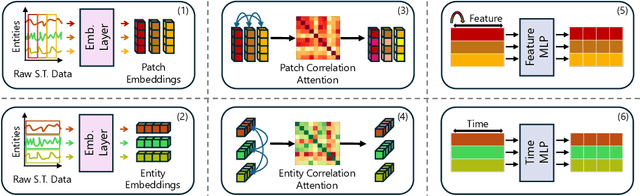
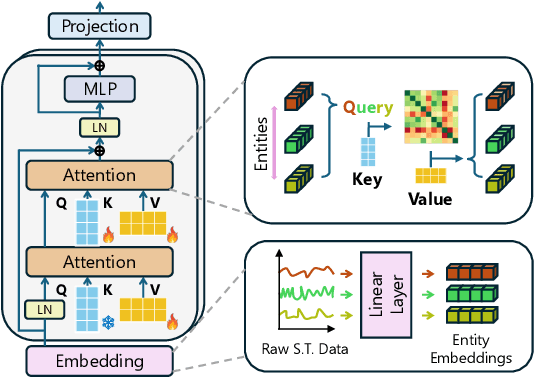
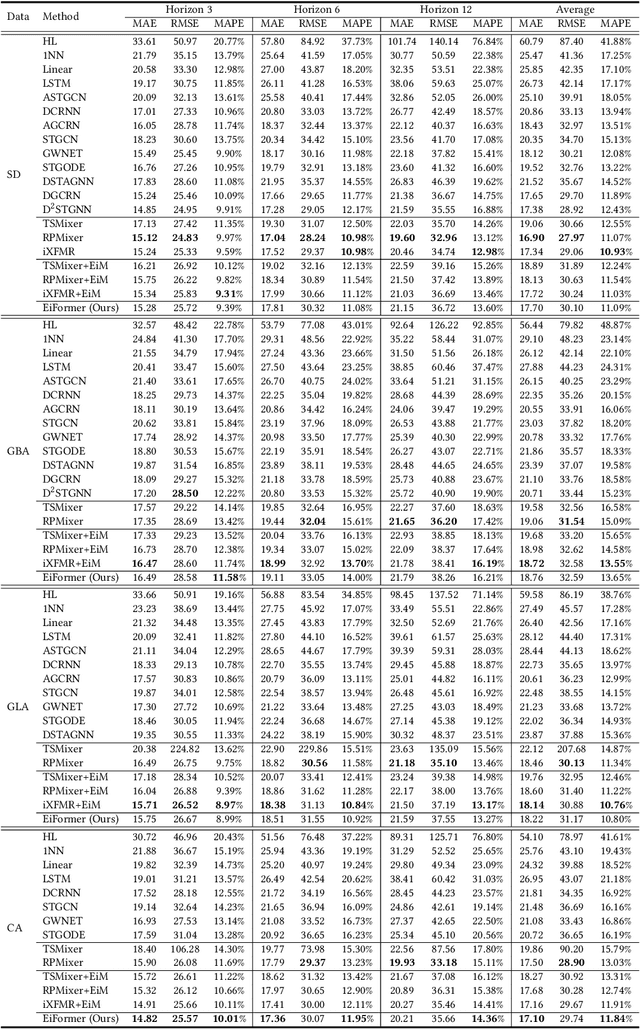
Time series forecasting at scale presents significant challenges for modern prediction systems, particularly when dealing with large sets of synchronized series, such as in a global payment network. In such systems, three key challenges must be overcome for accurate and scalable predictions: 1) emergence of new entities, 2) disappearance of existing entities, and 3) the large number of entities present in the data. The recently proposed Inverted Transformer (iTransformer) architecture has shown promising results by effectively handling variable entities. However, its practical application in large-scale settings is limited by quadratic time and space complexity ($O(N^2)$) with respect to the number of entities $N$. In this paper, we introduce EiFormer, an improved inverted transformer architecture that maintains the adaptive capabilities of iTransformer while reducing computational complexity to linear scale ($O(N)$). Our key innovation lies in restructuring the attention mechanism to eliminate redundant computations without sacrificing model expressiveness. Additionally, we incorporate a random projection mechanism that not only enhances efficiency but also improves prediction accuracy through better feature representation. Extensive experiments on the public LargeST benchmark dataset and a proprietary large-scale time series dataset demonstrate that EiFormer significantly outperforms existing methods in both computational efficiency and forecasting accuracy. Our approach enables practical deployment of transformer-based forecasting in industrial applications where handling time series at scale is essential.
You Only Debias Once: Towards Flexible Accuracy-Fairness Trade-offs at Inference Time
Mar 10, 2025Deep neural networks are prone to various bias issues, jeopardizing their applications for high-stake decision-making. Existing fairness methods typically offer a fixed accuracy-fairness trade-off, since the weight of the well-trained model is a fixed point (fairness-optimum) in the weight space. Nevertheless, more flexible accuracy-fairness trade-offs at inference time are practically desired since: 1) stakes of the same downstream task can vary for different individuals, and 2) different regions have diverse laws or regularization for fairness. If using the previous fairness methods, we have to train multiple models, each offering a specific level of accuracy-fairness trade-off. This is often computationally expensive, time-consuming, and difficult to deploy, making it less practical for real-world applications. To address this problem, we propose You Only Debias Once (YODO) to achieve in-situ flexible accuracy-fairness trade-offs at inference time, using a single model that trained only once. Instead of pursuing one individual fixed point (fairness-optimum) in the weight space, we aim to find a "line" in the weight space that connects the accuracy-optimum and fairness-optimum points using a single model. Points (models) on this line implement varying levels of accuracy-fairness trade-offs. At inference time, by manually selecting the specific position of the learned "line", our proposed method can achieve arbitrary accuracy-fairness trade-offs for different end-users and scenarios. Experimental results on tabular and image datasets show that YODO achieves flexible trade-offs between model accuracy and fairness, at ultra-low overheads. For example, if we need $100$ levels of trade-off on the \acse dataset, YODO takes $3.53$ seconds while training $100$ fixed models consumes $425$ seconds. The code is available at https://github.com/ahxt/yodo.
A Compact Model for Large-Scale Time Series Forecasting
Feb 28, 2025



Spatio-temporal data, which commonly arise in real-world applications such as traffic monitoring, financial transactions, and ride-share demands, represent a special category of multivariate time series. They exhibit two distinct characteristics: high dimensionality and commensurability across spatial locations. These attributes call for computationally efficient modeling approaches and facilitate the use of univariate forecasting models in a channel-independent fashion. SparseTSF, a recently introduced competitive univariate forecasting model, harnesses periodicity to achieve compactness by concentrating on cross-period dynamics, thereby extending the Pareto frontier with respect to model size and predictive performance. Nonetheless, it underperforms on spatio-temporal data due to an inadequate capture of intra-period temporal dependencies. To address this shortcoming, we propose UltraSTF, which integrates a cross-period forecasting module with an ultra-compact shape bank component. Our model effectively detects recurring patterns in time series through the attention mechanism of the shape bank component, thereby strengthening its ability to learn intra-period dynamics. UltraSTF achieves state-of-the-art performance on the LargeST benchmark while employing fewer than 0.2% of the parameters required by the second-best approaches, thus further extending the Pareto frontier of existing methods.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Dec 31, 2024



Large Language Models (LLMs) are becoming essential tools for various natural language processing tasks but often suffer from generating outdated or incorrect information. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating external, real-time information retrieval to ground LLM responses. However, the existing RAG systems frequently struggle with the quality of retrieval documents, as irrelevant or noisy documents degrade performance, increase computational overhead, and undermine response reliability. To tackle this problem, we propose Multi-Agent Filtering Retrieval-Augmented Generation (MAIN-RAG), a training-free RAG framework that leverages multiple LLM agents to collaboratively filter and score retrieved documents. Specifically, MAIN-RAG introduces an adaptive filtering mechanism that dynamically adjusts the relevance filtering threshold based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents. The proposed approach leverages inter-agent consensus to ensure robust document selection without requiring additional training data or fine-tuning. Experimental results across four QA benchmarks demonstrate that MAIN-RAG consistently outperforms traditional RAG approaches, achieving a 2-11% improvement in answer accuracy while reducing the number of irrelevant retrieved documents. Quantitative analysis further reveals that our approach achieves superior response consistency and answer accuracy over baseline methods, offering a competitive and practical alternative to training-based solutions.
Understanding and Mitigating Memorization in Diffusion Models for Tabular Data
Dec 15, 2024Tabular data generation has attracted significant research interest in recent years, with the tabular diffusion models greatly improving the quality of synthetic data. However, while memorization, where models inadvertently replicate exact or near-identical training data, has been thoroughly investigated in image and text generation, its effects on tabular data remain largely unexplored. In this paper, we conduct the first comprehensive investigation of memorization phenomena in diffusion models for tabular data. Our empirical analysis reveals that memorization appears in tabular diffusion models and increases with larger training epochs. We further examine the influence of factors such as dataset sizes, feature dimensions, and different diffusion models on memorization. Additionally, we provide a theoretical explanation for why memorization occurs in tabular diffusion models. To address this issue, we propose TabCutMix, a simple yet effective data augmentation technique that exchanges randomly selected feature segments between random same-class training sample pairs. Building upon this, we introduce TabCutMixPlus, an enhanced method that clusters features based on feature correlations and ensures that features within the same cluster are exchanged together during augmentation. This clustering mechanism mitigates out-of-distribution (OOD) generation issues by maintaining feature coherence. Experimental results across various datasets and diffusion models demonstrate that TabCutMix effectively mitigates memorization while maintaining high-quality data generation.