 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LLM Evaluator Behavior: A Structured Multi-Evaluator Framework for Merchant Risk Assessment
Feb 04, 2026Large Language Models (LLMs) are increasingly used as evaluators of reasoning quality, yet their reliability and bias in payments-risk settings remain poorly understood. We introduce a structured multi-evaluator framework for assessing LLM reasoning in Merchant Category Code (MCC)-based merchant risk assessment, combining a five-criterion rubric with Monte-Carlo scoring to evaluate rationale quality and evaluator stability. Five frontier LLMs generate and cross-evaluate MCC risk rationales under attributed and anonymized conditions. To establish a judge-independent reference, we introduce a consensus-deviation metric that eliminates circularity by comparing each judge's score to the mean of all other judges, yielding a theoretically grounded measure of self-evaluation and cross-model deviation. Results reveal substantial heterogeneity: GPT-5.1 and Claude 4.5 Sonnet show negative self-evaluation bias (-0.33, -0.31), while Gemini-2.5 Pro and Grok 4 display positive bias (+0.77, +0.71), with bias attenuating by 25.8 percent under anonymization. Evaluation by 26 payment-industry experts shows LLM judges assign scores averaging +0.46 points above human consensus, and that the negative bias of GPT-5.1 and Claude 4.5 Sonnet reflects closer alignment with human judgment. Ground-truth validation using payment-network data shows four models exhibit statistically significant alignment (Spearman rho = 0.56 to 0.77), confirming that the framework captures genuine quality. Overall, the framework provides a replicable basis for evaluating LLM-as-a-judge systems in payment-risk workflows and highlights the need for bias-aware protocols in operational financial settings.
TransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Empowering Time Series Forecasting with LLM-Agents
Aug 06, 2025Large Language Model (LLM) powered agents have emerged as effective planners for Automated Machine Learning (AutoML) systems. While most existing AutoML approaches focus on automating feature engineering and model architecture search, recent studies in time series forecasting suggest that lightweight models can often achieve state-of-the-art performance. This observation led us to explore improving data quality, rather than model architecture, as a potentially fruitful direction for AutoML on time series data. We propose DCATS, a Data-Centric Agent for Time Series. DCATS leverages metadata accompanying time series to clean data while optimizing forecasting performance. We evaluated DCATS using four time series forecasting models on a large-scale traffic volume forecasting dataset. Results demonstrate that DCATS achieves an average 6% error reduction across all tested models and time horizons, highlighting the potential of data-centric approaches in AutoML for time series forecasting.
SimAug: Enhancing Recommendation with Pretrained Language Models for Dense and Balanced Data Augmentation
May 03, 2025Deep Neural Networks (DNNs) are extensively used in collaborative filtering due to their impressive effectiveness. These systems depend on interaction data to learn user and item embeddings that are crucial for recommendations. However, the data often suffers from sparsity and imbalance issues: limited observations of user-item interactions can result in sub-optimal performance, and a predominance of interactions with popular items may introduce recommendation bias. To address these challenges, we employ Pretrained Language Models (PLMs) to enhance the interaction data with textual information, leading to a denser and more balanced dataset. Specifically, we propose a simple yet effective data augmentation method (SimAug) based on the textual similarity from PLMs, which can be seamlessly integrated to any systems as a lightweight, plug-and-play component in the pre-processing stage. Our experiments across nine datasets consistently demonstrate improvements in both utility and fairness when training with the augmented data generated by SimAug. The code is available at https://github.com/YuyingZhao/SimAug.
Towards Efficient Large Scale Spatial-Temporal Time Series Forecasting via Improved Inverted Transformers
Mar 13, 2025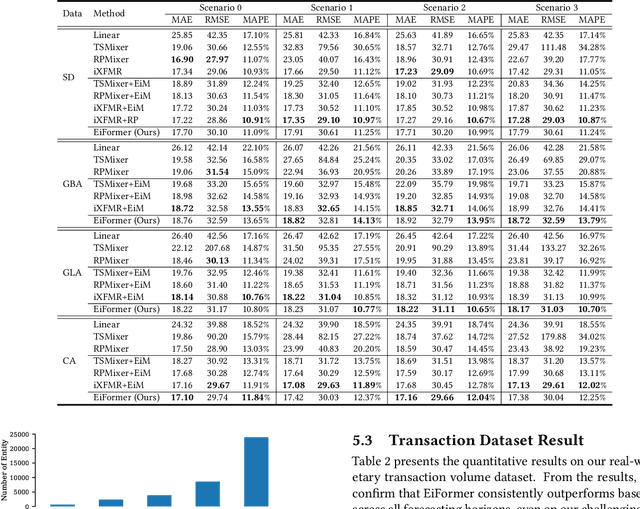
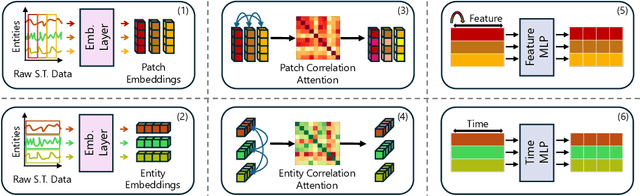
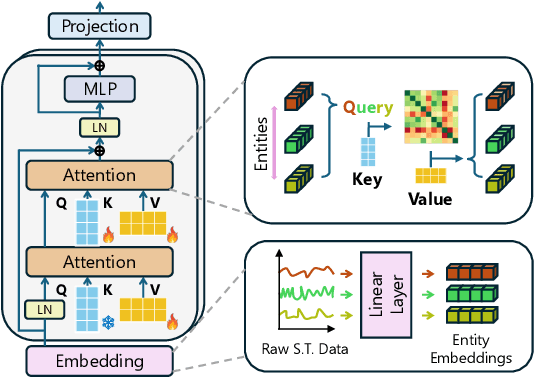
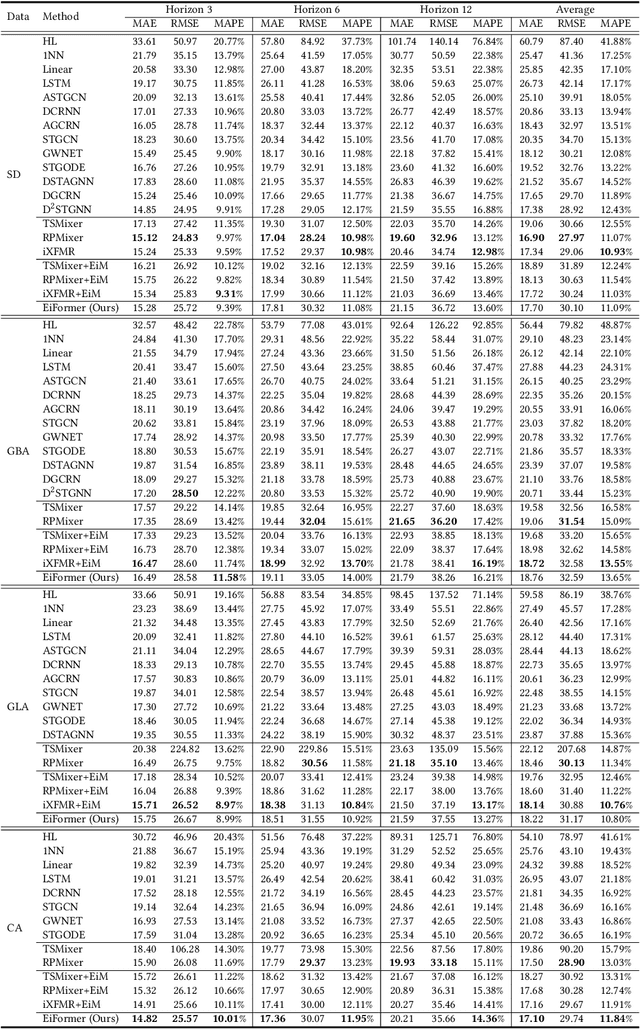
Time series forecasting at scale presents significant challenges for modern prediction systems, particularly when dealing with large sets of synchronized series, such as in a global payment network. In such systems, three key challenges must be overcome for accurate and scalable predictions: 1) emergence of new entities, 2) disappearance of existing entities, and 3) the large number of entities present in the data. The recently proposed Inverted Transformer (iTransformer) architecture has shown promising results by effectively handling variable entities. However, its practical application in large-scale settings is limited by quadratic time and space complexity ($O(N^2)$) with respect to the number of entities $N$. In this paper, we introduce EiFormer, an improved inverted transformer architecture that maintains the adaptive capabilities of iTransformer while reducing computational complexity to linear scale ($O(N)$). Our key innovation lies in restructuring the attention mechanism to eliminate redundant computations without sacrificing model expressiveness. Additionally, we incorporate a random projection mechanism that not only enhances efficiency but also improves prediction accuracy through better feature representation. Extensive experiments on the public LargeST benchmark dataset and a proprietary large-scale time series dataset demonstrate that EiFormer significantly outperforms existing methods in both computational efficiency and forecasting accuracy. Our approach enables practical deployment of transformer-based forecasting in industrial applications where handling time series at scale is essential.
A Compact Model for Large-Scale Time Series Forecasting
Feb 28, 2025



Spatio-temporal data, which commonly arise in real-world applications such as traffic monitoring, financial transactions, and ride-share demands, represent a special category of multivariate time series. They exhibit two distinct characteristics: high dimensionality and commensurability across spatial locations. These attributes call for computationally efficient modeling approaches and facilitate the use of univariate forecasting models in a channel-independent fashion. SparseTSF, a recently introduced competitive univariate forecasting model, harnesses periodicity to achieve compactness by concentrating on cross-period dynamics, thereby extending the Pareto frontier with respect to model size and predictive performance. Nonetheless, it underperforms on spatio-temporal data due to an inadequate capture of intra-period temporal dependencies. To address this shortcoming, we propose UltraSTF, which integrates a cross-period forecasting module with an ultra-compact shape bank component. Our model effectively detects recurring patterns in time series through the attention mechanism of the shape bank component, thereby strengthening its ability to learn intra-period dynamics. UltraSTF achieves state-of-the-art performance on the LargeST benchmark while employing fewer than 0.2% of the parameters required by the second-best approaches, thus further extending the Pareto frontier of existing methods.
Discrete-state Continuous-time Diffusion for Graph Generation
May 19, 2024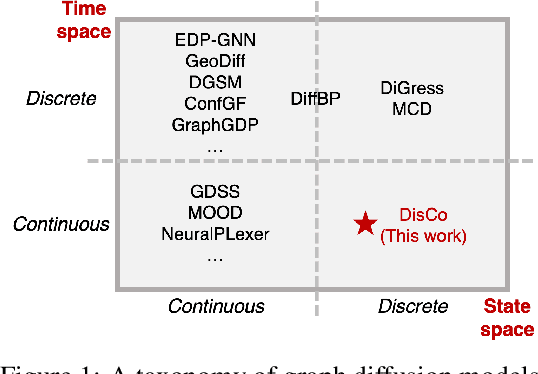
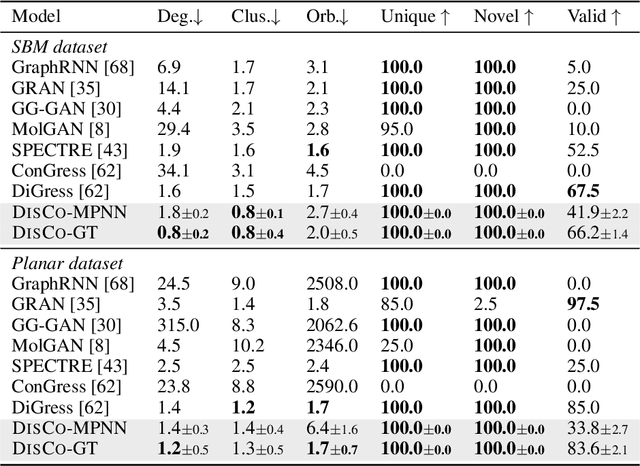

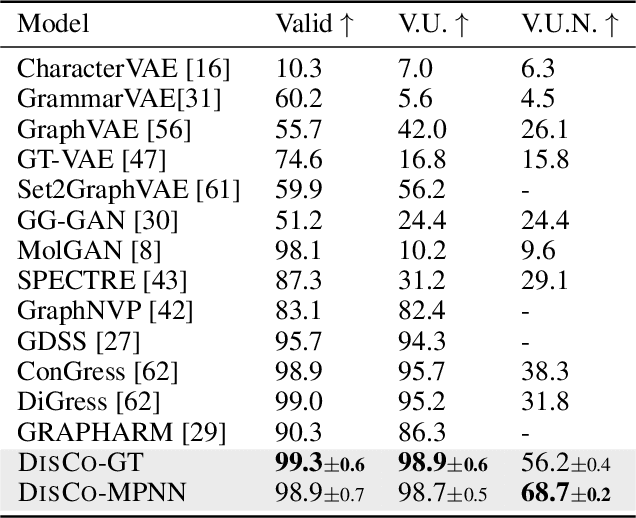
Graph is a prevalent discrete data structure, whose generation has wide applications such as drug discovery and circuit design. Diffusion generative models, as an emerging research focus, have been applied to graph generation tasks. Overall, according to the space of states and time steps, diffusion generative models can be categorized into discrete-/continuous-state discrete-/continuous-time fashions. In this paper, we formulate the graph diffusion generation in a discrete-state continuous-time setting, which has never been studied in previous graph diffusion models. The rationale of such a formulation is to preserve the discrete nature of graph-structured data and meanwhile provide flexible sampling trade-offs between sample quality and efficiency. Analysis shows that our training objective is closely related to generation quality, and our proposed generation framework enjoys ideal invariant/equivariant properties concerning the permutation of node ordering. Our proposed model shows competitive empirical performance against state-of-the-art graph generation solutions on various benchmarks and, at the same time, can flexibly trade off the generation quality and efficiency in the sampling phase.
Horocycle Decision Boundaries for Large Margin Classification in Hyperbolic Space
Feb 14, 2023Hyperbolic spaces have been quite popular in the recent past for representing hierarchically organized data. Further, several classification algorithms for data in these spaces have been proposed in the literature. These algorithms mainly use either hyperplanes or geodesics for decision boundaries in a large margin classifiers setting leading to a non-convex optimization problem. In this paper, we propose a novel large margin classifier based on horocycle (horosphere) decision boundaries that leads to a geodesically convex optimization problem that can be optimized using any Riemannian gradient descent technique guaranteeing a globally optimal solution. We present several experiments depicting the performance of our classifier.
Nested Hyperbolic Spaces for Dimensionality Reduction and Hyperbolic NN Design
Dec 03, 2021

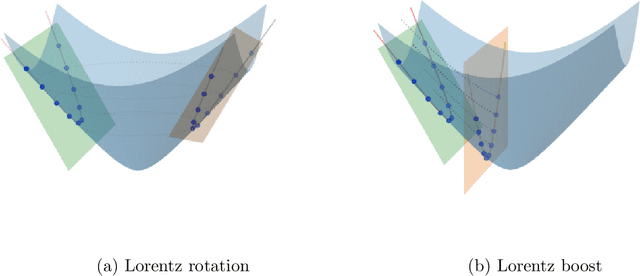

Hyperbolic neural networks have been popular in the recent past due to their ability to represent hierarchical data sets effectively and efficiently. The challenge in developing these networks lies in the nonlinearity of the embedding space namely, the Hyperbolic space. Hyperbolic space is a homogeneous Riemannian manifold of the Lorentz group. Most existing methods (with some exceptions) use local linearization to define a variety of operations paralleling those used in traditional deep neural networks in Euclidean spaces. In this paper, we present a novel fully hyperbolic neural network which uses the concept of projections (embeddings) followed by an intrinsic aggregation and a nonlinearity all within the hyperbolic space. The novelty here lies in the projection which is designed to project data on to a lower-dimensional embedded hyperbolic space and hence leads to a nested hyperbolic space representation independently useful for dimensionality reduction. The main theoretical contribution is that the proposed embedding is proved to be isometric and equivariant under the Lorentz transformations. This projection is computationally efficient since it can be expressed by simple linear operations, and, due to the aforementioned equivariance property, it allows for weight sharing. The nested hyperbolic space representation is the core component of our network and therefore, we first compare this ensuing nested hyperbolic space representation with other dimensionality reduction methods such as tangent PCA, principal geodesic analysis (PGA) and HoroPCA. Based on this equivariant embedding, we develop a novel fully hyperbolic graph convolutional neural network architecture to learn the parameters of the projection. Finally, we present experiments demonstrating comparative performance of our network on several publicly available data sets.