 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorocycle Decision Boundaries for Large Margin Classification in Hyperbolic Space
Feb 14, 2023Hyperbolic spaces have been quite popular in the recent past for representing hierarchically organized data. Further, several classification algorithms for data in these spaces have been proposed in the literature. These algorithms mainly use either hyperplanes or geodesics for decision boundaries in a large margin classifiers setting leading to a non-convex optimization problem. In this paper, we propose a novel large margin classifier based on horocycle (horosphere) decision boundaries that leads to a geodesically convex optimization problem that can be optimized using any Riemannian gradient descent technique guaranteeing a globally optimal solution. We present several experiments depicting the performance of our classifier.
Nested Hyperbolic Spaces for Dimensionality Reduction and Hyperbolic NN Design
Dec 03, 2021

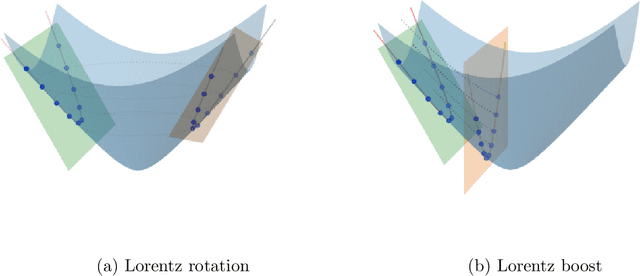

Hyperbolic neural networks have been popular in the recent past due to their ability to represent hierarchical data sets effectively and efficiently. The challenge in developing these networks lies in the nonlinearity of the embedding space namely, the Hyperbolic space. Hyperbolic space is a homogeneous Riemannian manifold of the Lorentz group. Most existing methods (with some exceptions) use local linearization to define a variety of operations paralleling those used in traditional deep neural networks in Euclidean spaces. In this paper, we present a novel fully hyperbolic neural network which uses the concept of projections (embeddings) followed by an intrinsic aggregation and a nonlinearity all within the hyperbolic space. The novelty here lies in the projection which is designed to project data on to a lower-dimensional embedded hyperbolic space and hence leads to a nested hyperbolic space representation independently useful for dimensionality reduction. The main theoretical contribution is that the proposed embedding is proved to be isometric and equivariant under the Lorentz transformations. This projection is computationally efficient since it can be expressed by simple linear operations, and, due to the aforementioned equivariance property, it allows for weight sharing. The nested hyperbolic space representation is the core component of our network and therefore, we first compare this ensuing nested hyperbolic space representation with other dimensionality reduction methods such as tangent PCA, principal geodesic analysis (PGA) and HoroPCA. Based on this equivariant embedding, we develop a novel fully hyperbolic graph convolutional neural network architecture to learn the parameters of the projection. Finally, we present experiments demonstrating comparative performance of our network on several publicly available data sets.
Nested Grassmanns for Dimensionality Reduction
Oct 27, 2020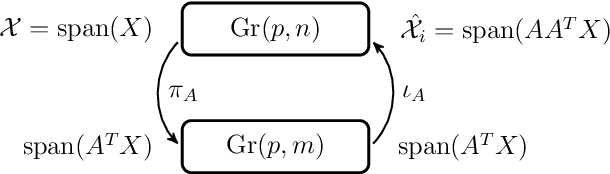

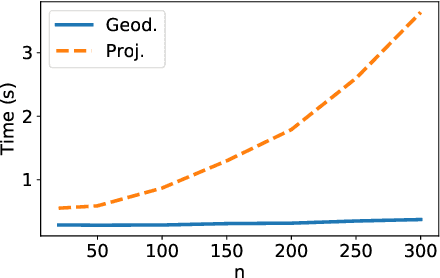
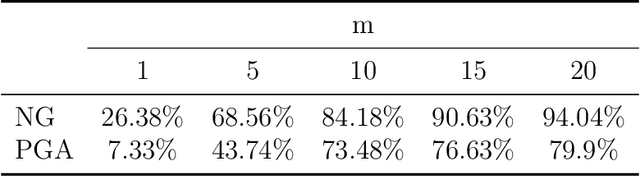
Grassmann manifolds have been widely used to represent the geometry of feature spaces in a variety of problems in computer vision including but not limited to face recognition, action recognition, subspace clustering and motion segmentation. For these problems, the features usually lie in a very high-dimensional Grassmann manifold and hence an appropriate dimensionality reduction technique is called for in order to curtail the computational burden. To this end, the Principal Geodesic Analysis (PGA), a nonlinear extension of the well known principal component analysis, is applicable as a general tool to many Riemannian manifolds. In this paper, we propose a novel dimensionality reduction framework suited for Grassmann manifolds by utilizing the geometry of the manifold. Specifically, we project points in a Grassmann manifold to an embedded lower dimensional Grassmann manifold. A salient feature of our method is that it leads to higher expressed variance compared to PGA which we demonstrate via synthetic and real data experiments.
MVC-Net: A Convolutional Neural Network Architecture for Manifold-Valued Images With Applications
Mar 06, 2020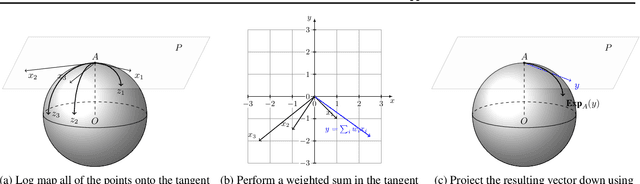


Geometric deep learning has attracted significant attention in recent years, in part due to the availability of exotic data types for which traditional neural network architectures are not well suited. Our goal in this paper is to generalize convolutional neural networks (CNN) to the manifold-valued image case which arises commonly in medical imaging and computer vision applications. Explicitly, the input data to the network is an image where each pixel value is a sample from a Riemannian manifold. To achieve this goal, we must generalize the basic building block of traditional CNN architectures, namely, the weighted combinations operation. To this end, we develop a tangent space combination operation which is used to define a convolution operation on manifold-valued images that we call, the Manifold-Valued Convolution (MVC). We prove theoretical properties of the MVC operation, including equivariance to the action of the isometry group admitted by the manifold and characterizing when compositions of MVC layers collapse to a single layer. We present a detailed description of how to use MVC layers to build full, multi-layer neural networks that operate on manifold-valued images, which we call the MVC-net. Further, we empirically demonstrate superior performance of the MVC-nets in medical imaging and computer vision tasks.
A Statistical Recurrent Model on the Manifold of Symmetric Positive Definite Matrices
Oct 27, 2018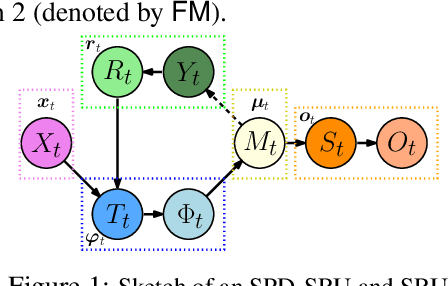
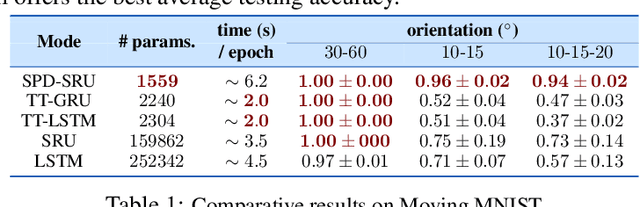
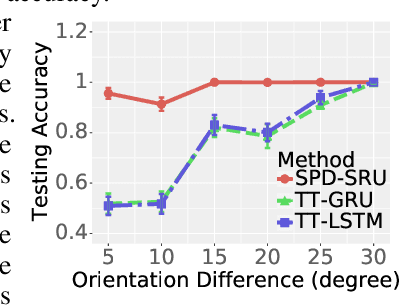
In a number of disciplines, the data (e.g., graphs, manifolds) to be analyzed are non-Euclidean in nature. Geometric deep learning corresponds to techniques that generalize deep neural network models to such non-Euclidean spaces. Several recent papers have shown how convolutional neural networks (CNNs) can be extended to learn with graph-based data. In this work, we study the setting where the data (or measurements) are ordered, longitudinal or temporal in nature and live on a Riemannian manifold -- this setting is common in a variety of problems in statistical machine learning, vision and medical imaging. We show how recurrent statistical recurrent network models can be defined in such spaces. We give an efficient algorithm and conduct a rigorous analysis of its statistical properties. We perform extensive numerical experiments demonstrating competitive performance with state of the art methods but with significantly less number of parameters. We also show applications to a statistical analysis task in brain imaging, a regime where deep neural network models have only been utilized in limited ways.
A mixture model for aggregation of multiple pre-trained weak classifiers
May 31, 2018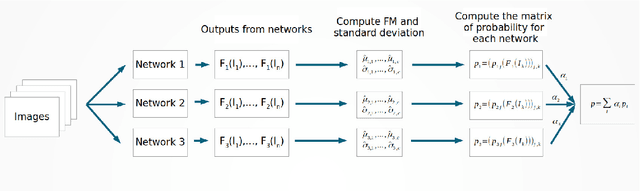
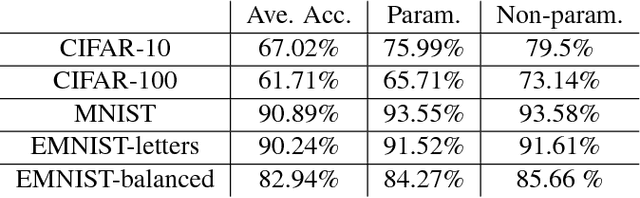

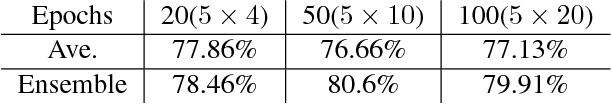
Deep networks have gained immense popularity in Computer Vision and other fields in the past few years due to their remarkable performance on recognition/classification tasks surpassing the state-of-the art. One of the keys to their success lies in the richness of the automatically learned features. In order to get very good accuracy, one popular option is to increase the depth of the network. Training such a deep network is however infeasible or impractical with moderate computational resources and budget. The other alternative to increase the performance is to learn multiple weak classifiers and boost their performance using a boosting algorithm or a variant thereof. But, one of the problems with boosting algorithms is that they require a re-training of the networks based on the misclassified samples. Motivated by these problems, in this work we propose an aggregation technique which combines the output of multiple weak classifiers. We formulate the aggregation problem using a mixture model fitted to the trained classifier outputs. Our model does not require any re-training of the `weak' networks and is computationally very fast (takes $<30$ seconds to run in our experiments). Thus, using a less expensive training stage and without doing any re-training of networks, we experimentally demonstrate that it is possible to boost the performance by $12\%$. Furthermore, we present experiments using hand-crafted features and improved the classification performance using the proposed aggregation technique. One of the major advantages of our framework is that our framework allows one to combine features that are very likely to be of distinct dimensions since they are extracted using different networks/algorithms. Our experimental results demonstrate a significant performance gain from the use of our aggregation technique at a very small computational cost.
Multiple-Instance Logistic Regression with LASSO Penalty
Jul 13, 2016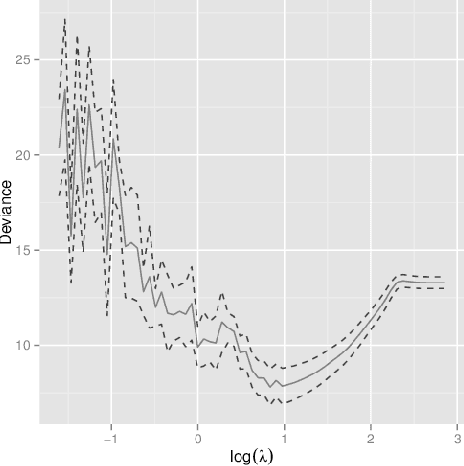
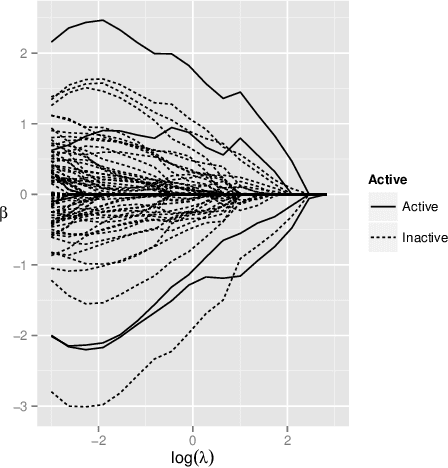


In this work, we consider a manufactory process which can be described by a multiple-instance logistic regression model. In order to compute the maximum likelihood estimation of the unknown coefficient, an expectation-maximization algorithm is proposed, and the proposed modeling approach can be extended to identify the important covariates by adding the coefficient penalty term into the likelihood function. In addition to essential technical details, we demonstrate the usefulness of the proposed method by simulations and real examples.