 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA mixture model for aggregation of multiple pre-trained weak classifiers
Paper and Code
May 31, 2018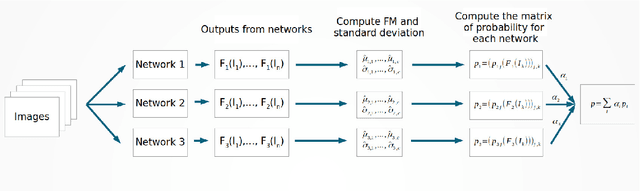
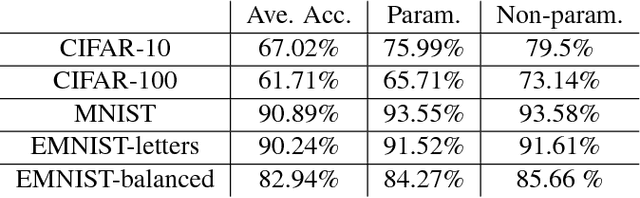

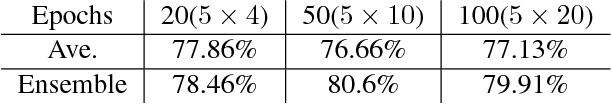
Deep networks have gained immense popularity in Computer Vision and other fields in the past few years due to their remarkable performance on recognition/classification tasks surpassing the state-of-the art. One of the keys to their success lies in the richness of the automatically learned features. In order to get very good accuracy, one popular option is to increase the depth of the network. Training such a deep network is however infeasible or impractical with moderate computational resources and budget. The other alternative to increase the performance is to learn multiple weak classifiers and boost their performance using a boosting algorithm or a variant thereof. But, one of the problems with boosting algorithms is that they require a re-training of the networks based on the misclassified samples. Motivated by these problems, in this work we propose an aggregation technique which combines the output of multiple weak classifiers. We formulate the aggregation problem using a mixture model fitted to the trained classifier outputs. Our model does not require any re-training of the `weak' networks and is computationally very fast (takes $<30$ seconds to run in our experiments). Thus, using a less expensive training stage and without doing any re-training of networks, we experimentally demonstrate that it is possible to boost the performance by $12\%$. Furthermore, we present experiments using hand-crafted features and improved the classification performance using the proposed aggregation technique. One of the major advantages of our framework is that our framework allows one to combine features that are very likely to be of distinct dimensions since they are extracted using different networks/algorithms. Our experimental results demonstrate a significant performance gain from the use of our aggregation technique at a very small computational cost.