 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 8th AI City Challenge
Apr 15, 2024
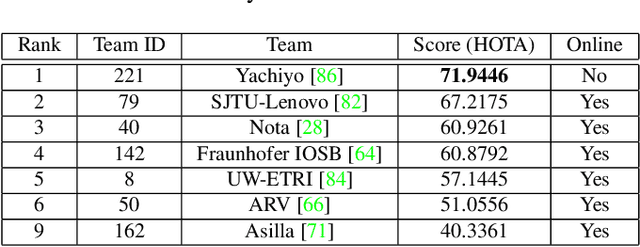

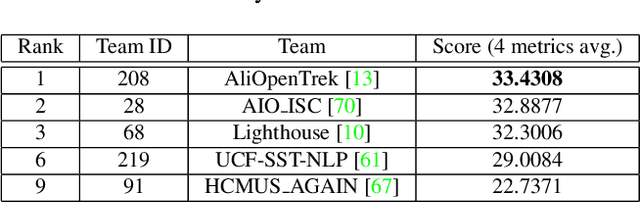
The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
FishEye8K: A Benchmark and Dataset for Fisheye Camera Object Detection
Jun 06, 2023



With the advance of AI, road object detection has been a prominent topic in computer vision, mostly using perspective cameras. Fisheye lens provides omnidirectional wide coverage for using fewer cameras to monitor road intersections, however with view distortions. To our knowledge, there is no existing open dataset prepared for traffic surveillance on fisheye cameras. This paper introduces an open FishEye8K benchmark dataset for road object detection tasks, which comprises 157K bounding boxes across five classes (Pedestrian, Bike, Car, Bus, and Truck). In addition, we present benchmark results of State-of-The-Art (SoTA) models, including variations of YOLOv5, YOLOR, YOLO7, and YOLOv8. The dataset comprises 8,000 images recorded in 22 videos using 18 fisheye cameras for traffic monitoring in Hsinchu, Taiwan, at resolutions of 1080$\times$1080 and 1280$\times$1280. The data annotation and validation process were arduous and time-consuming, due to the ultra-wide panoramic and hemispherical fisheye camera images with large distortion and numerous road participants, particularly people riding scooters. To avoid bias, frames from a particular camera were assigned to either the training or test sets, maintaining a ratio of about 70:30 for both the number of images and bounding boxes in each class. Experimental results show that YOLOv8 and YOLOR outperform on input sizes 640$\times$640 and 1280$\times$1280, respectively. The dataset will be available on GitHub with PASCAL VOC, MS COCO, and YOLO annotation formats. The FishEye8K benchmark will provide significant contributions to the fisheye video analytics and smart city applications.
SARAS-Net: Scale and Relation Aware Siamese Network for Change Detection
Dec 02, 2022


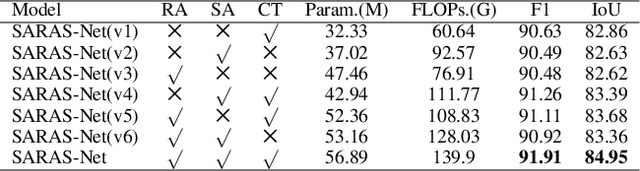
Change detection (CD) aims to find the difference between two images at different times and outputs a change map to represent whether the region has changed or not. To achieve a better result in generating the change map, many State-of-The-Art (SoTA) methods design a deep learning model that has a powerful discriminative ability. However, these methods still get lower performance because they ignore spatial information and scaling changes between objects, giving rise to blurry or wrong boundaries. In addition to these, they also neglect the interactive information of two different images. To alleviate these problems, we propose our network, the Scale and Relation-Aware Siamese Network (SARAS-Net) to deal with this issue. In this paper, three modules are proposed that include relation-aware, scale-aware, and cross-transformer to tackle the problem of scene change detection more effectively. To verify our model, we tested three public datasets, including LEVIR-CD, WHU-CD, and DSFIN, and obtained SoTA accuracy. Our code is available at https://github.com/f64051041/SARAS-Net.
SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking
Nov 17, 2022



Multiple Object Tracking (MOT) is widely investigated in computer vision with many applications. Tracking-By-Detection (TBD) is a popular multiple-object tracking paradigm. TBD consists of the first step of object detection and the subsequent of data association, tracklet generation, and update. We propose a Similarity Learning Module (SLM) motivated from the Siamese network to extract important object appearance features and a procedure to combine object motion and appearance features effectively. This design strengthens the modeling of object motion and appearance features for data association. We design a Similarity Matching Cascade (SMC) for the data association of our SMILEtrack tracker. SMILEtrack achieves 81.06 MOTA and 80.5 IDF1 on the MOTChallenge and the MOT17 test set, respectively.
Learnable Discrete Wavelet Pooling (LDW-Pooling) For Convolutional Networks
Sep 15, 2021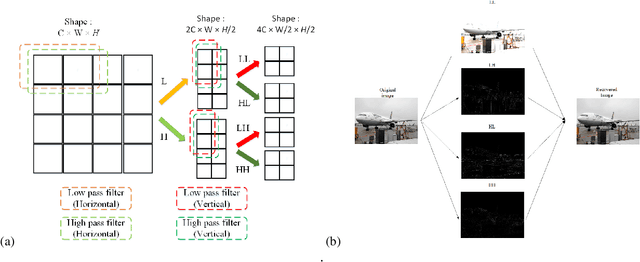

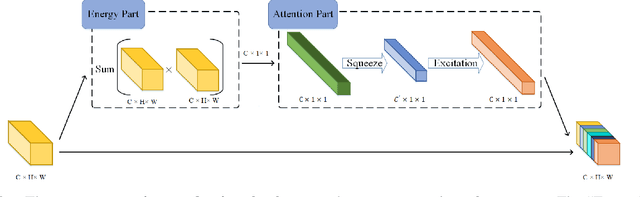
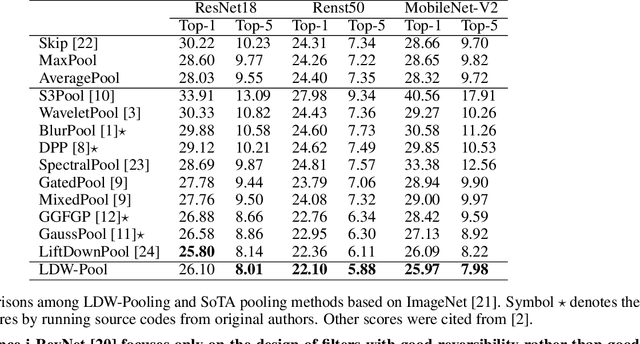
Pooling is a simple but essential layer in modern deep CNN architectures for feature aggregation and extraction. Typical CNN design focuses on the conv layers and activation functions, while leaving the pooling layers with fewer options. We introduce the Learning Discrete Wavelet Pooling (LDW-Pooling) that can be applied universally to replace standard pooling operations to better extract features with improved accuracy and efficiency. Motivated from the wavelet theory, we adopt the low-pass (L) and high-pass (H) filters horizontally and vertically for pooling on a 2D feature map. Feature signals are decomposed into four (LL, LH, HL, HH) subbands to retain features better and avoid information dropping. The wavelet transform ensures features after pooling can be fully preserved and recovered. We next adopt an energy-based attention learning to fine-select crucial and representative features. LDW-Pooling is effective and efficient when compared with other state-of-the-art pooling techniques such as WaveletPooling and LiftPooling. Extensive experimental validation shows that LDW-Pooling can be applied to a wide range of standard CNN architectures and consistently outperform standard (max, mean, mixed, and stochastic) pooling operations.
MS-DARTS: Mean-Shift Based Differentiable Architecture Search
Sep 01, 2021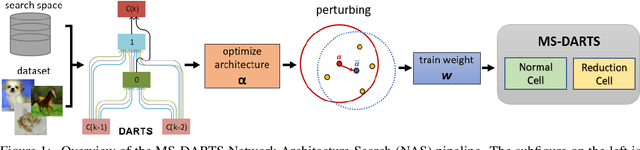

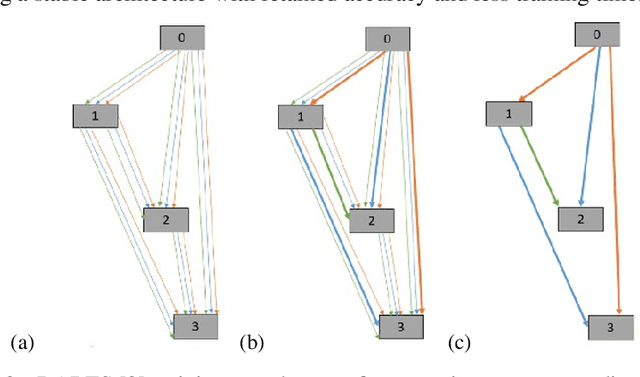
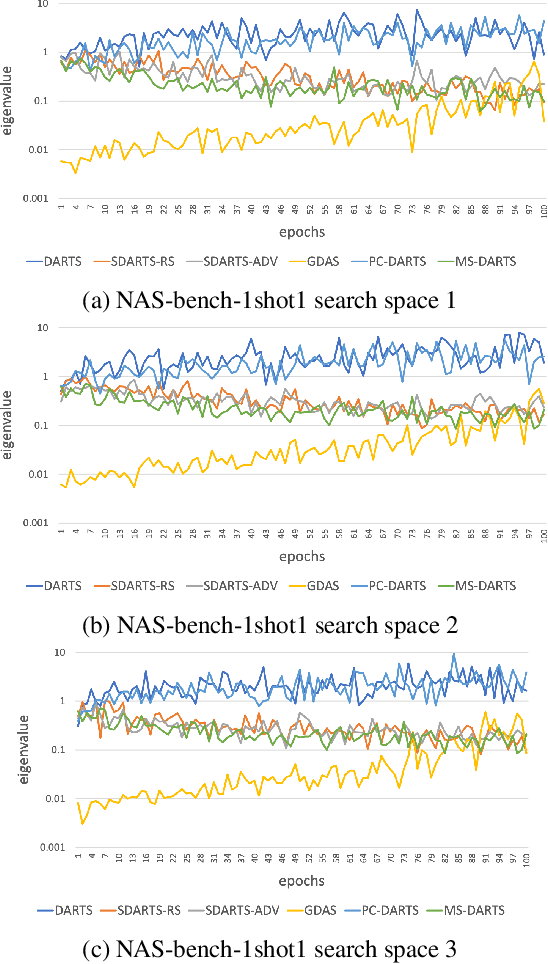
Differentiable Architecture Search (DARTS) is an effective continuous relaxation-based network architecture search (NAS) method with low search cost. It has attracted significant attentions in Auto-ML research and becomes one of the most useful paradigms in NAS. Although DARTS can produce superior efficiency over traditional NAS approaches with better control of complex parameters, oftentimes it suffers from stabilization issues in producing deteriorating architectures when discretizing the continuous architecture. We observed considerable loss of validity causing dramatic decline in performance at this final discretization step of DARTS. To address this issue, we propose a Mean-Shift based DARTS (MS-DARTS) to improve stability based on sampling and perturbation. Our approach can improve bot the stability and accuracy of DARTS, by smoothing the loss landscape and sampling architecture parameters within a suitable bandwidth. We investigate the convergence of our mean-shift approach, together with the effects of bandwidth selection that affects stability and accuracy. Evaluations performed on CIFAR-10, CIFAR-100, and ImageNet show that MS-DARTS archives higher performance over other state-of-the-art NAS methods with reduced search cost.
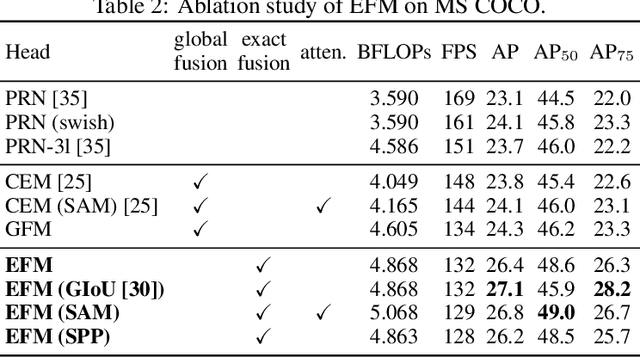
Parallel Residual Bi-Fusion Feature Pyramid Network for Accurate Single-Shot Object Detection
Dec 03, 2020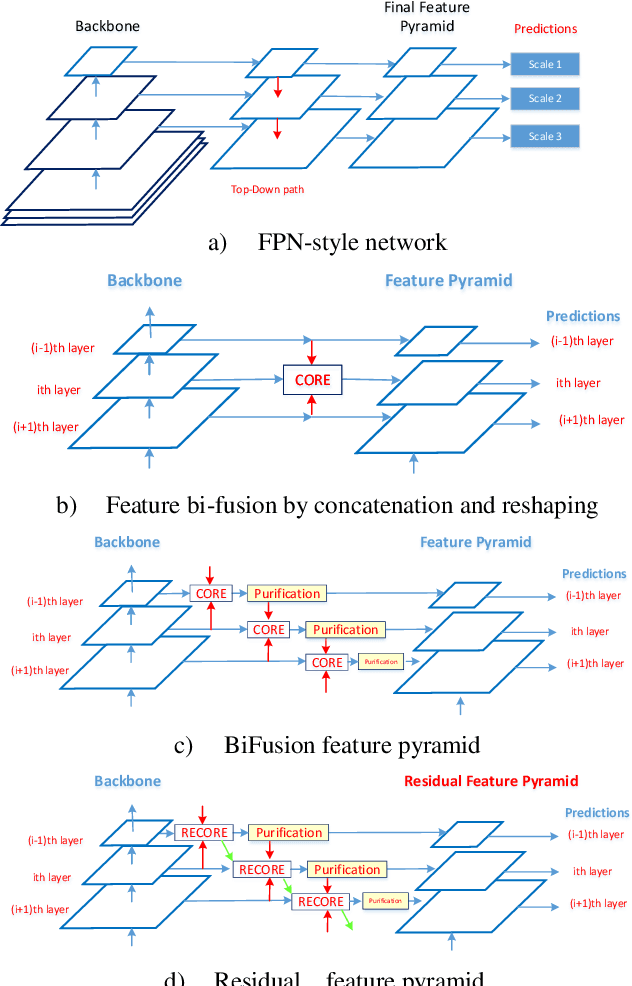
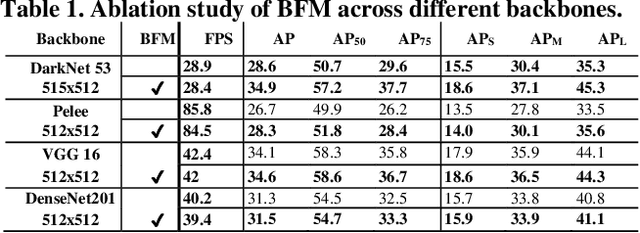

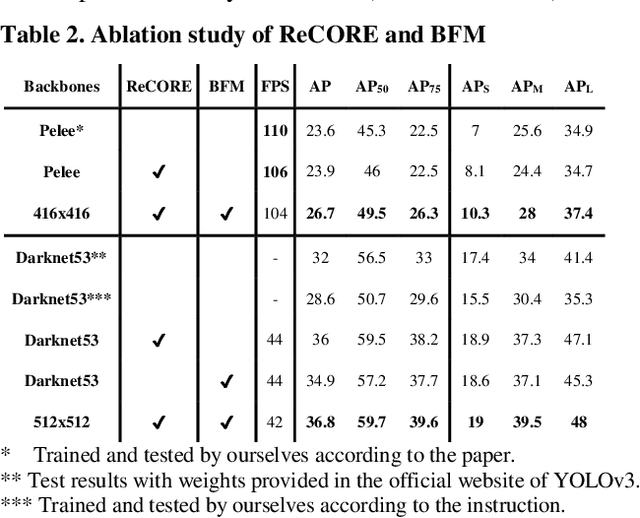
We propose the Parallel Residual Bi-Fusion Feature Pyramid Network (PRB-FPN) for fast and accurate single-shot object detection. Feature Pyramid (FP) is widely used in recent visual detection, however the top-down pathway of FP cannot preserve accurate localization due to pooling shifting. The advantage of FP is weaken as deeper backbones with more layers are used. To address this issue, we propose a new parallel FP structure with bi-directional (top-down and bottom-up) fusion and associated improvements to retain high-quality features for accurate localization. Our method is particularly suitable for detecting small objects. We provide the following design improvements: (1) A parallel bifusion FP structure with a Bottom-up Fusion Module (BFM) to detect both small and large objects at once with high accuracy. (2) A COncatenation and RE-organization (CORE) module provides a bottom-up pathway for feature fusion, which leads to the bi-directional fusion FP that can recover lost information from lower-layer feature maps. (3) The CORE feature is further purified to retain richer contextual information. Such purification is performed with CORE in a few iterations in both top-down and bottom-up pathways. (4) The adding of a residual design to CORE leads to a new Re-CORE module that enables easy training and integration with a wide range of (deeper or lighter) backbones. The proposed network achieves state-of-the-art performance on UAVDT17 and MS COCO datasets.
Residual Bi-Fusion Feature Pyramid Network for Accurate Single-shot Object Detection
Dec 10, 2019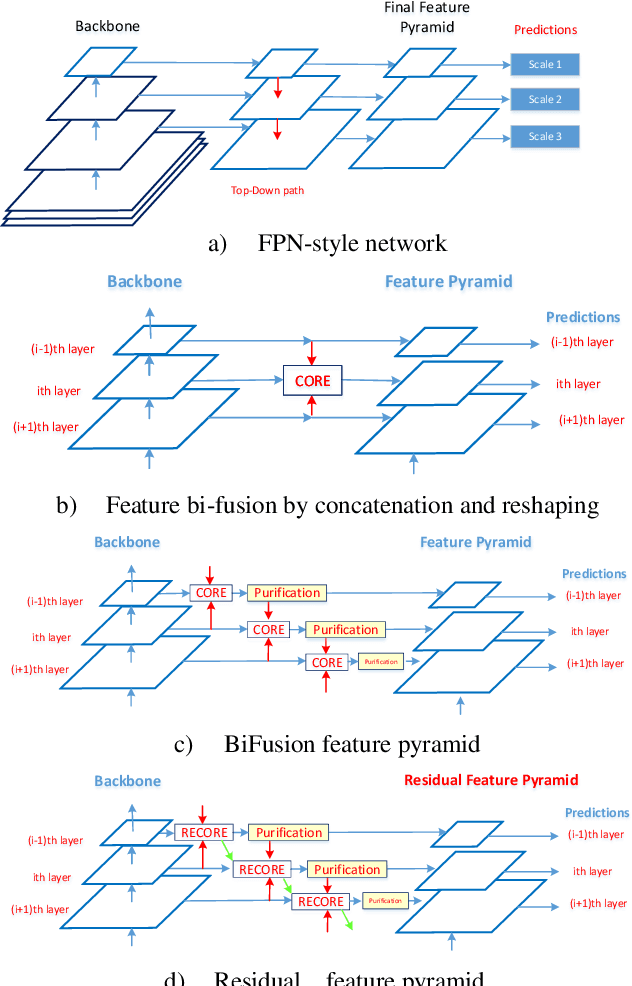
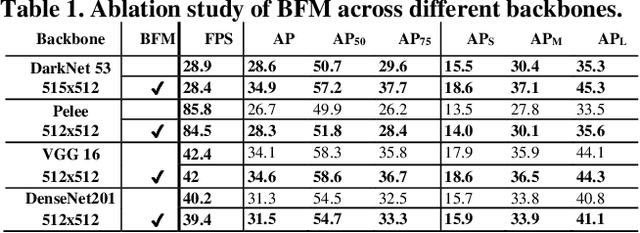
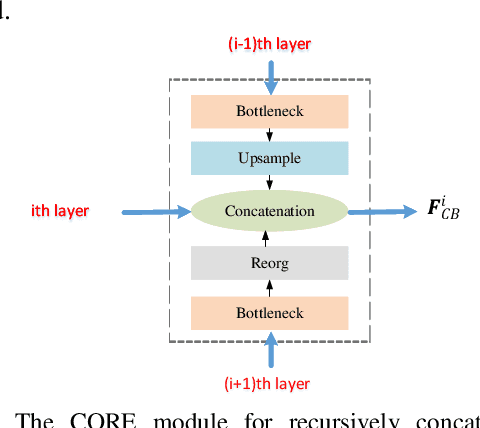
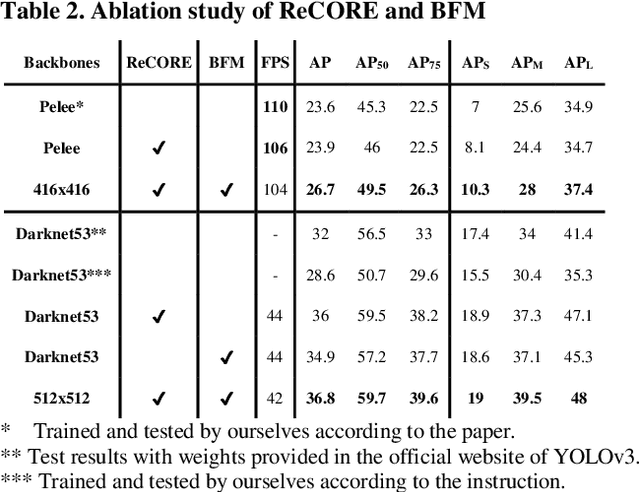
State-of-the-art (SoTA) models have improved the accuracy of object detection with a large margin via a FP (feature pyramid). FP is a top-down aggregation to collect semantically strong features to improve scale invariance in both two-stage and one-stage detectors. However, this top-down pathway cannot preserve accurate object positions due to the shift-effect of pooling. Thus, the advantage of FP to improve detection accuracy will disappear when more layers are used. The original FP lacks a bottom-up pathway to offset the lost information from lower-layer feature maps. It performs well in large-sized object detection but poor in small-sized object detection. A new structure "residual feature pyramid" is proposed in this paper. It is bidirectional to fuse both deep and shallow features towards more effective and robust detection for both small-sized and large-sized objects. Due to the "residual" nature, it can be easily trained and integrated to different backbones (even deeper or lighter) than other bi-directional methods. One important property of this residual FP is: accuracy improvement is still found even if more layers are adopted. Extensive experiments on VOC and MS COCO datasets showed the proposed method achieved the SoTA results for highly-accurate and efficient object detection..
CSPNet: A New Backbone that can Enhance Learning Capability of CNN
Nov 27, 2019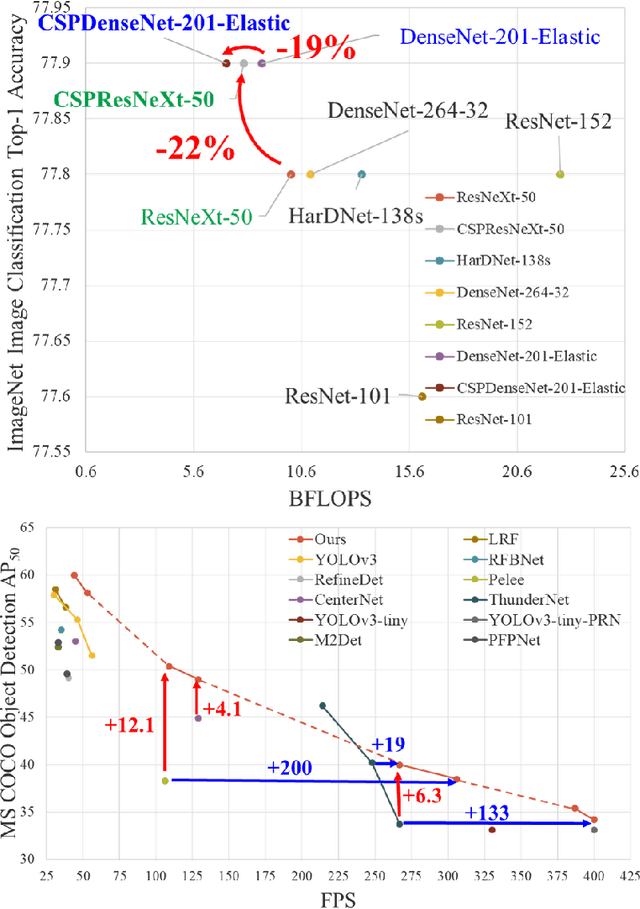


Neural networks have enabled state-of-the-art approaches to achieve incredible results on computer vision tasks such as object detection. However, such success greatly relies on costly computation resources, which hinders people with cheap devices from appreciating the advanced technology. In this paper, we propose Cross Stage Partial Network (CSPNet) to mitigate the problem that previous works require heavy inference computations from the network architecture perspective. We attribute the problem to the duplicate gradient information within network optimization. The proposed networks respect the variability of the gradients by integrating feature maps from the beginning and the end of a network stage, which, in our experiments, reduces computations by 20% with equivalent or even superior accuracy on the ImageNet dataset, and significantly outperforms state-of-the-art approaches in terms of AP50 on the MS COCO object detection dataset. The CSPNet is easy to implement and general enough to cope with architectures based on ResNet, ResNeXt, and DenseNet. Source code is at https://github.com/WongKinYiu/CrossStagePartialNetworks.
Multiple-Instance Logistic Regression with LASSO Penalty
Jul 13, 2016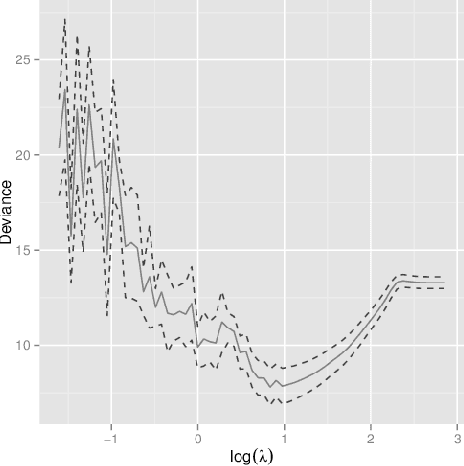
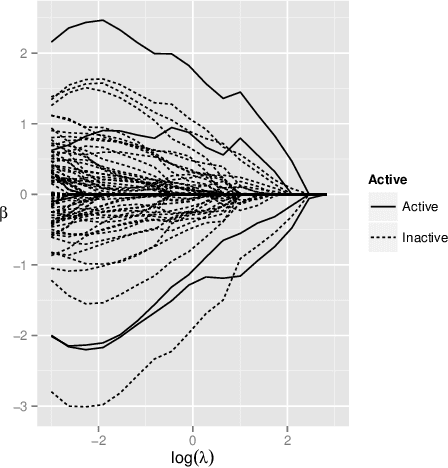


In this work, we consider a manufactory process which can be described by a multiple-instance logistic regression model. In order to compute the maximum likelihood estimation of the unknown coefficient, an expectation-maximization algorithm is proposed, and the proposed modeling approach can be extended to identify the important covariates by adding the coefficient penalty term into the likelihood function. In addition to essential technical details, we demonstrate the usefulness of the proposed method by simulations and real examples.