 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Framework for Collaborative Learning: Leveraging Advanced LLM with Adaptive Feedback Mechanisms
Jan 29, 2026This paper presents a framework for integrating LLM into collaborative learning platforms to enhance student engagement, critical thinking, and inclusivity. The framework employs advanced LLMs as dynamic moderators to facilitate real-time discussions and adapt to learners' evolving needs, ensuring diverse and inclusive educational experiences. Key innovations include robust feedback mechanisms that refine AI moderation, promote reflective learning, and balance participation among users. The system's modular architecture featuring ReactJS for the frontend, Flask for backend operations, and efficient question retrieval supports personalized and engaging interactions through dynamic adjustments to prompts and discussion flows. Testing demonstrates that the framework significantly improves student collaboration, fosters deeper comprehension, and scales effectively across various subjects and user groups. By addressing limitations in static moderation and personalization in existing systems, this work establishes a strong foundation for next-generation AI-driven educational tools, advancing equitable and impactful learning outcomes.
Multi-modal Integration Analysis of Alzheimer's Disease Using Large Language Models and Knowledge Graphs
May 21, 2025We propose a novel framework for integrating fragmented multi-modal data in Alzheimer's disease (AD) research using large language models (LLMs) and knowledge graphs. While traditional multimodal analysis requires matched patient IDs across datasets, our approach demonstrates population-level integration of MRI, gene expression, biomarkers, EEG, and clinical indicators from independent cohorts. Statistical analysis identified significant features in each modality, which were connected as nodes in a knowledge graph. LLMs then analyzed the graph to extract potential correlations and generate hypotheses in natural language. This approach revealed several novel relationships, including a potential pathway linking metabolic risk factors to tau protein abnormalities via neuroinflammation (r>0.6, p<0.001), and unexpected correlations between frontal EEG channels and specific gene expression profiles (r=0.42-0.58, p<0.01). Cross-validation with independent datasets confirmed the robustness of major findings, with consistent effect sizes across cohorts (variance <15%). The reproducibility of these findings was further supported by expert review (Cohen's k=0.82) and computational validation. Our framework enables cross modal integration at a conceptual level without requiring patient ID matching, offering new possibilities for understanding AD pathology through fragmented data reuse and generating testable hypotheses for future research.
The 8th AI City Challenge
Apr 15, 2024
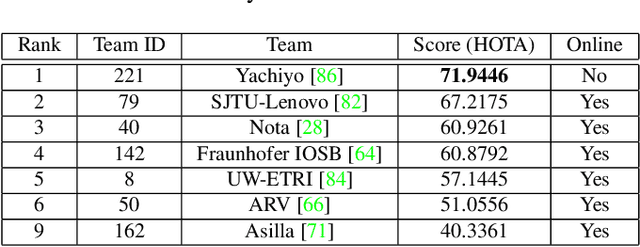

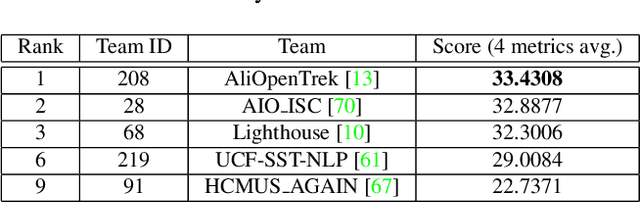
The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
FishEye8K: A Benchmark and Dataset for Fisheye Camera Object Detection
Jun 06, 2023With the advance of AI, road object detection has been a prominent topic in computer vision, mostly using perspective cameras. Fisheye lens provides omnidirectional wide coverage for using fewer cameras to monitor road intersections, however with view distortions. To our knowledge, there is no existing open dataset prepared for traffic surveillance on fisheye cameras. This paper introduces an open FishEye8K benchmark dataset for road object detection tasks, which comprises 157K bounding boxes across five classes (Pedestrian, Bike, Car, Bus, and Truck). In addition, we present benchmark results of State-of-The-Art (SoTA) models, including variations of YOLOv5, YOLOR, YOLO7, and YOLOv8. The dataset comprises 8,000 images recorded in 22 videos using 18 fisheye cameras for traffic monitoring in Hsinchu, Taiwan, at resolutions of 1080$\times$1080 and 1280$\times$1280. The data annotation and validation process were arduous and time-consuming, due to the ultra-wide panoramic and hemispherical fisheye camera images with large distortion and numerous road participants, particularly people riding scooters. To avoid bias, frames from a particular camera were assigned to either the training or test sets, maintaining a ratio of about 70:30 for both the number of images and bounding boxes in each class. Experimental results show that YOLOv8 and YOLOR outperform on input sizes 640$\times$640 and 1280$\times$1280, respectively. The dataset will be available on GitHub with PASCAL VOC, MS COCO, and YOLO annotation formats. The FishEye8K benchmark will provide significant contributions to the fisheye video analytics and smart city applications.