 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Simple In-place Data Augmentation for Surveillance Object Detection
Apr 17, 2024



Motivated by the need to improve model performance in traffic monitoring tasks with limited labeled samples, we propose a straightforward augmentation technique tailored for object detection datasets, specifically designed for stationary camera-based applications. Our approach focuses on placing objects in the same positions as the originals to ensure its effectiveness. By applying in-place augmentation on objects from the same camera input image, we address the challenge of overlapping with original and previously selected objects. Through extensive testing on two traffic monitoring datasets, we illustrate the efficacy of our augmentation strategy in improving model performance, particularly in scenarios with limited labeled samples and imbalanced class distributions. Notably, our method achieves comparable performance to models trained on the entire dataset while utilizing only 8.5 percent of the original data. Moreover, we report significant improvements, with mAP@.5 increasing from 0.4798 to 0.5025, and the mAP@.5:.95 rising from 0.29 to 0.3138 on the FishEye8K dataset. These results highlight the potential of our augmentation approach in enhancing object detection models for traffic monitoring applications.
The 8th AI City Challenge
Apr 15, 2024
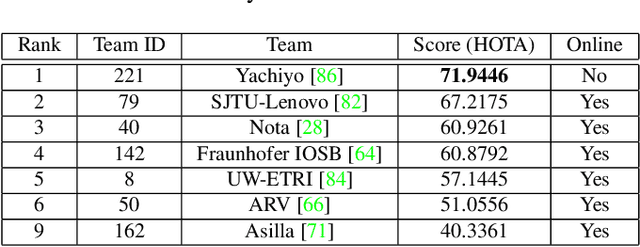

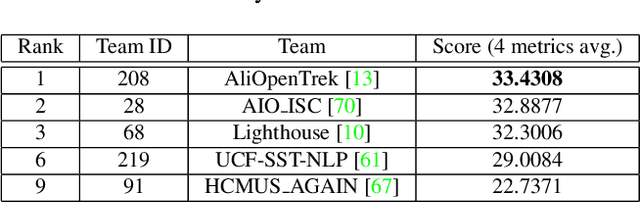
The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
FishEye8K: A Benchmark and Dataset for Fisheye Camera Object Detection
Jun 06, 2023With the advance of AI, road object detection has been a prominent topic in computer vision, mostly using perspective cameras. Fisheye lens provides omnidirectional wide coverage for using fewer cameras to monitor road intersections, however with view distortions. To our knowledge, there is no existing open dataset prepared for traffic surveillance on fisheye cameras. This paper introduces an open FishEye8K benchmark dataset for road object detection tasks, which comprises 157K bounding boxes across five classes (Pedestrian, Bike, Car, Bus, and Truck). In addition, we present benchmark results of State-of-The-Art (SoTA) models, including variations of YOLOv5, YOLOR, YOLO7, and YOLOv8. The dataset comprises 8,000 images recorded in 22 videos using 18 fisheye cameras for traffic monitoring in Hsinchu, Taiwan, at resolutions of 1080$\times$1080 and 1280$\times$1280. The data annotation and validation process were arduous and time-consuming, due to the ultra-wide panoramic and hemispherical fisheye camera images with large distortion and numerous road participants, particularly people riding scooters. To avoid bias, frames from a particular camera were assigned to either the training or test sets, maintaining a ratio of about 70:30 for both the number of images and bounding boxes in each class. Experimental results show that YOLOv8 and YOLOR outperform on input sizes 640$\times$640 and 1280$\times$1280, respectively. The dataset will be available on GitHub with PASCAL VOC, MS COCO, and YOLO annotation formats. The FishEye8K benchmark will provide significant contributions to the fisheye video analytics and smart city applications.
Residual Bi-Fusion Feature Pyramid Network for Accurate Single-shot Object Detection
Dec 10, 2019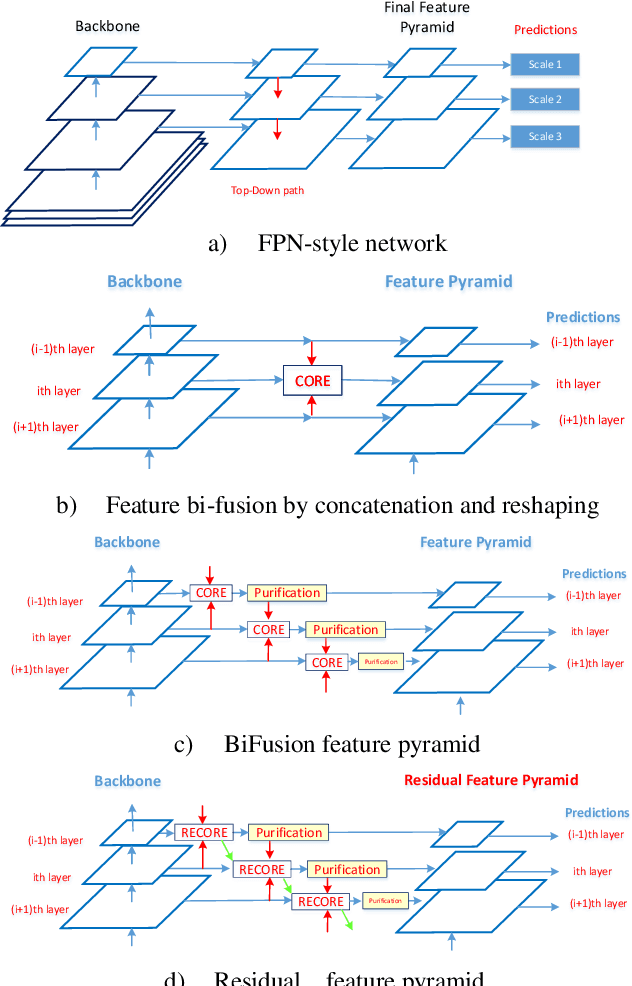
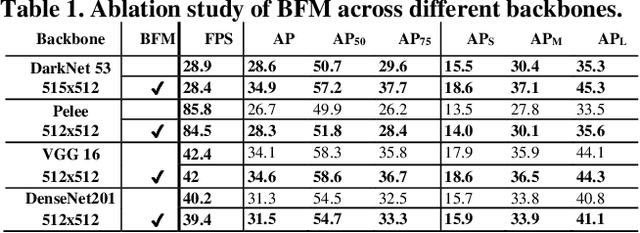
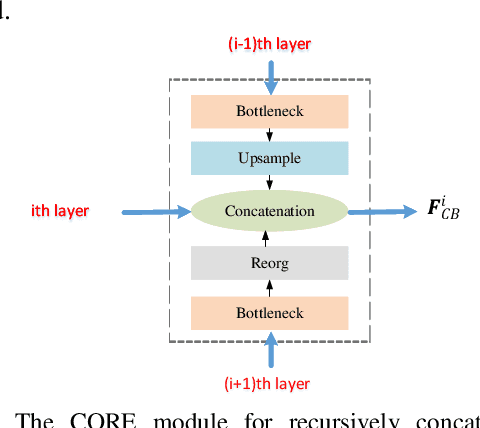
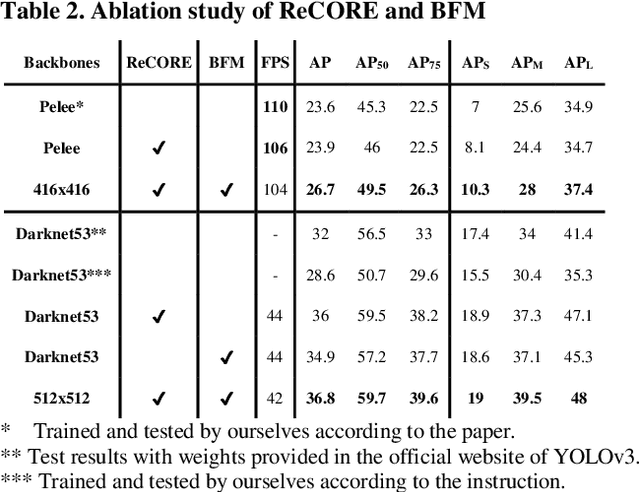
State-of-the-art (SoTA) models have improved the accuracy of object detection with a large margin via a FP (feature pyramid). FP is a top-down aggregation to collect semantically strong features to improve scale invariance in both two-stage and one-stage detectors. However, this top-down pathway cannot preserve accurate object positions due to the shift-effect of pooling. Thus, the advantage of FP to improve detection accuracy will disappear when more layers are used. The original FP lacks a bottom-up pathway to offset the lost information from lower-layer feature maps. It performs well in large-sized object detection but poor in small-sized object detection. A new structure "residual feature pyramid" is proposed in this paper. It is bidirectional to fuse both deep and shallow features towards more effective and robust detection for both small-sized and large-sized objects. Due to the "residual" nature, it can be easily trained and integrated to different backbones (even deeper or lighter) than other bi-directional methods. One important property of this residual FP is: accuracy improvement is still found even if more layers are adopted. Extensive experiments on VOC and MS COCO datasets showed the proposed method achieved the SoTA results for highly-accurate and efficient object detection..