 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacaron: Controlled, Human-Written Benchmark for Multilingual and Multicultural Reasoning via Template-Filling
Feb 11, 2026Multilingual benchmarks rarely test reasoning over culturally grounded premises: translated datasets keep English-centric scenarios, while culture-first datasets often lack control over the reasoning required. We propose Macaron, a template-first benchmark that factorizes reasoning type and cultural aspect across question languages. Using 100 language-agnostic templates that cover 7 reasoning types, 22 cultural aspects, native annotators create scenario-aligned English and local-language multiple-choice questions and systematically derived True/False questions. Macaron contains 11,862 instances spanning 20 countries/cultural contexts, 10 scripts, and 20 languages (including low-resource ones like Amharic, Yoruba, Zulu, Kyrgyz, and some Arabic dialects). In zero-shot evaluation of 21 multilingual LLMs, reasoning-mode models achieve the strongest performance and near-parity between English and local languages, while open-weight models degrade substantially in local languages and often approach chance on T/F tasks. Culture-grounded mathematical and counting templates are consistently the hardest. The data can be accessed here https://huggingface.co/datasets/AlaaAhmed2444/Macaron.
Multicultural Spyfall: Assessing LLMs through Dynamic Multilingual Social Deduction Game
Jan 13, 2026The rapid advancement of Large Language Models (LLMs) has necessitated more robust evaluation methods that go beyond static benchmarks, which are increasingly prone to data saturation and leakage. In this paper, we propose a dynamic benchmarking framework for evaluating multilingual and multicultural capabilities through the social deduction game Spyfall. In our setup, models must engage in strategic dialogue to either identify a secret agent or avoid detection, utilizing culturally relevant locations or local foods. Our results show that our game-based rankings align closely with the Chatbot Arena. However, we find a significant performance gap in non-English contexts: models are generally less proficient when handling locally specific entities and often struggle with rule-following or strategic integrity in non-English languages. We demonstrate that this game-based approach provides a scalable, leakage-resistant, and culturally nuanced alternative to traditional NLP benchmarks. The game history can be accessed here https://huggingface.co/datasets/haryoaw/cultural-spyfall.
Unveiling the Influence of Amplifying Language-Specific Neurons
Jul 30, 2025Language-specific neurons in LLMs that strongly correlate with individual languages have been shown to influence model behavior by deactivating them. However, their role in amplification remains underexplored. This work investigates the effect of amplifying language-specific neurons through interventions across 18 languages, including low-resource ones, using three models primarily trained in different languages. We compare amplification factors by their effectiveness in steering to the target language using a proposed Language Steering Shift (LSS) evaluation score, then evaluate it on downstream tasks: commonsense reasoning (XCOPA, XWinograd), knowledge (Include), and translation (FLORES). The optimal amplification factors effectively steer output toward nearly all tested languages. Intervention using this factor on downstream tasks improves self-language performance in some cases but generally degrades cross-language results. These findings highlight the effect of language-specific neurons in multilingual behavior, where amplification can be beneficial especially for low-resource languages, but provides limited advantage for cross-lingual transfer.
IteRABRe: Iterative Recovery-Aided Block Reduction
Mar 08, 2025
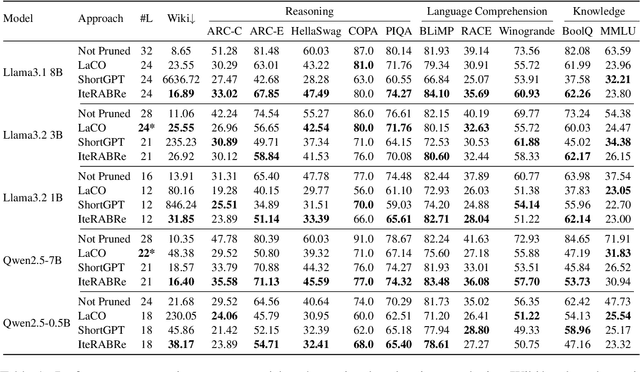
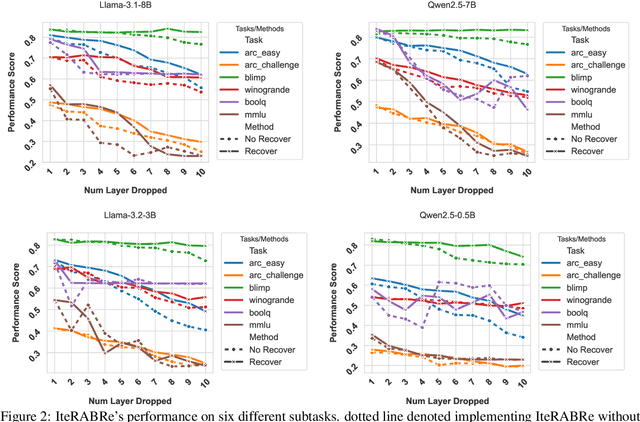
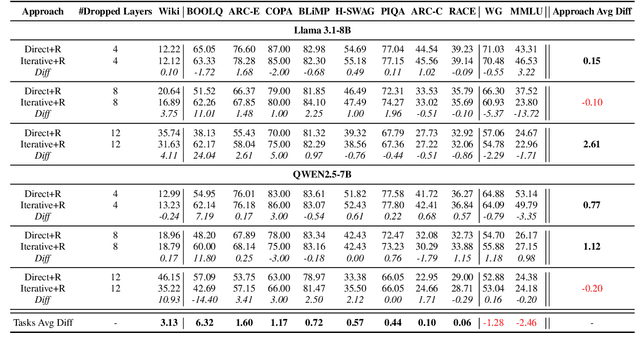
Large Language Models (LLMs) have grown increasingly expensive to deploy, driving the need for effective model compression techniques. While block pruning offers a straightforward approach to reducing model size, existing methods often struggle to maintain performance or require substantial computational resources for recovery. We present IteRABRe, a simple yet effective iterative pruning method that achieves superior compression results while requiring minimal computational resources. Using only 2.5M tokens for recovery, our method outperforms baseline approaches by ~3% on average when compressing the Llama3.1-8B and Qwen2.5-7B models. IteRABRe demonstrates particular strength in the preservation of linguistic capabilities, showing an improvement 5% over the baselines in language-related tasks. Our analysis reveals distinct pruning characteristics between these models, while also demonstrating preservation of multilingual capabilities.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
The Privileged Students: On the Value of Initialization in Multilingual Knowledge Distillation
Jun 24, 2024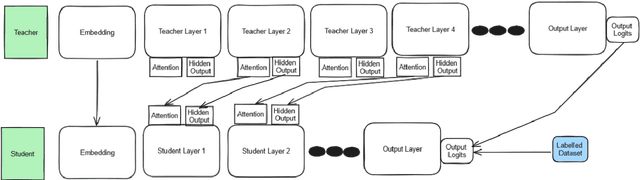
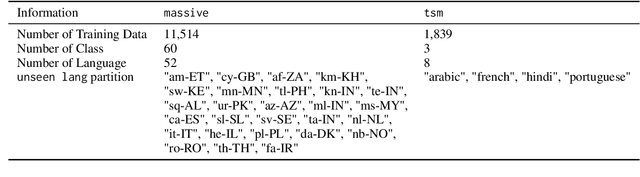
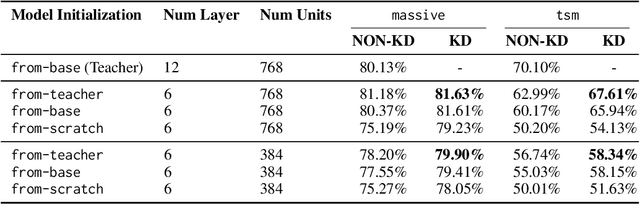
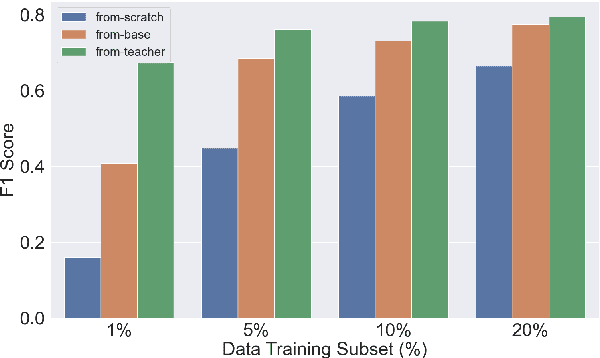
Knowledge distillation (KD) has proven to be a successful strategy to improve the performance of a smaller model in many NLP tasks. However, most of the work in KD only explores monolingual scenarios. In this paper, we investigate the value of KD in multilingual settings. We find the significance of KD and model initialization by analyzing how well the student model acquires multilingual knowledge from the teacher model. Our proposed method emphasizes copying the teacher model's weights directly to the student model to enhance initialization. Our finding shows that model initialization using copy-weight from the fine-tuned teacher contributes the most compared to the distillation process itself across various multilingual settings. Furthermore, we demonstrate that efficient weight initialization preserves multilingual capabilities even in low-resource scenarios.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
COPAL-ID: Indonesian Language Reasoning with Local Culture and Nuances
Nov 13, 2023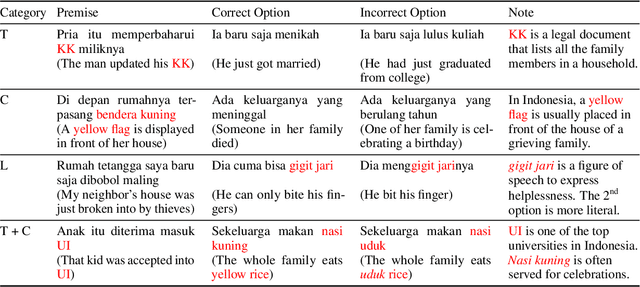

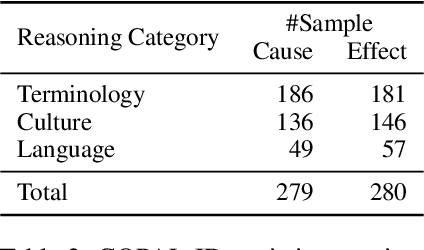
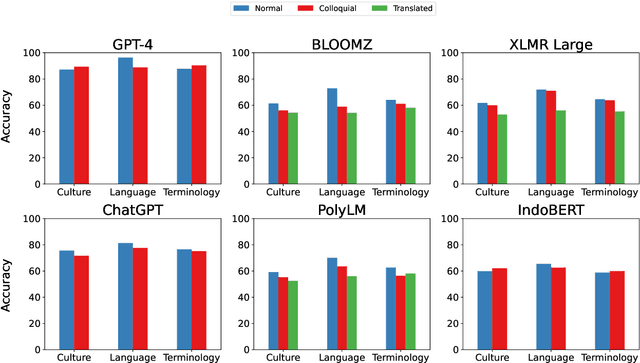
We present publicly available COPAL-ID, a novel Indonesian language common sense reasoning dataset. Unlike the previous Indonesian COPA dataset (XCOPA-ID), COPAL-ID incorporates Indonesian local and cultural nuances, and therefore, provides a more natural portrayal of day-to-day causal reasoning within the Indonesian cultural sphere. Professionally written by natives from scratch, COPAL-ID is more fluent and free from awkward phrases, unlike the translated XCOPA-ID. In addition, we present COPAL-ID in both standard Indonesian and in Jakartan Indonesian--a dialect commonly used in daily conversation. COPAL-ID poses a greater challenge for existing open-sourced and closed state-of-the-art multilingual language models, yet is trivially easy for humans. Our findings suggest that even the current best open-source, multilingual model struggles to perform well, achieving 65.47% accuracy on COPAL-ID, significantly lower than on the culturally-devoid XCOPA-ID (79.40%). Despite GPT-4's impressive score, it suffers the same performance degradation compared to its XCOPA-ID score, and it still falls short of human performance. This shows that these language models are still way behind in comprehending the local nuances of Indonesian.
On "Scientific Debt" in NLP: A Case for More Rigour in Language Model Pre-Training Research
Jun 05, 2023This evidence-based position paper critiques current research practices within the language model pre-training literature. Despite rapid recent progress afforded by increasingly better pre-trained language models (PLMs), current PLM research practices often conflate different possible sources of model improvement, without conducting proper ablation studies and principled comparisons between different models under comparable conditions. These practices (i) leave us ill-equipped to understand which pre-training approaches should be used under what circumstances; (ii) impede reproducibility and credit assignment; and (iii) render it difficult to understand: "How exactly does each factor contribute to the progress that we have today?" We provide a case in point by revisiting the success of BERT over its baselines, ELMo and GPT-1, and demonstrate how -- under comparable conditions where the baselines are tuned to a similar extent -- these baselines (and even-simpler variants thereof) can, in fact, achieve competitive or better performance than BERT. These findings demonstrate how disentangling different factors of model improvements can lead to valuable new insights. We conclude with recommendations for how to encourage and incentivize this line of work, and accelerate progress towards a better and more systematic understanding of what factors drive the progress of our foundation models today.
Which Student is Best? A Comprehensive Knowledge Distillation Exam for Task-Specific BERT Models
Jan 03, 2022
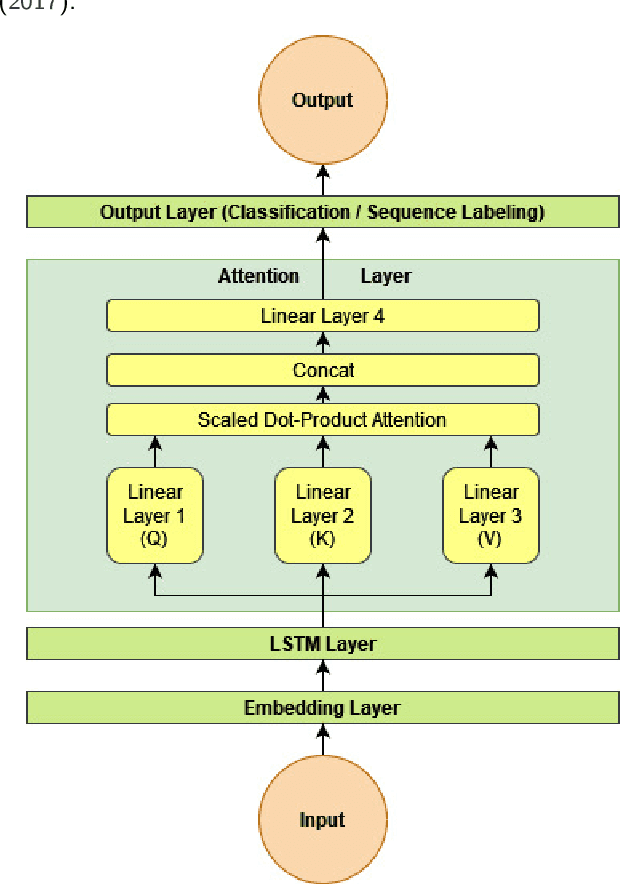
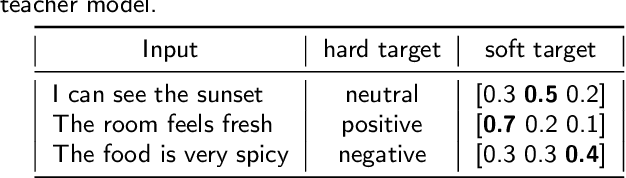
We perform knowledge distillation (KD) benchmark from task-specific BERT-base teacher models to various student models: BiLSTM, CNN, BERT-Tiny, BERT-Mini, and BERT-Small. Our experiment involves 12 datasets grouped in two tasks: text classification and sequence labeling in the Indonesian language. We also compare various aspects of distillations including the usage of word embeddings and unlabeled data augmentation. Our experiments show that, despite the rising popularity of Transformer-based models, using BiLSTM and CNN student models provide the best trade-off between performance and computational resource (CPU, RAM, and storage) compared to pruned BERT models. We further propose some quick wins on performing KD to produce small NLP models via efficient KD training mechanisms involving simple choices of loss functions, word embeddings, and unlabeled data preparation.