 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfri-MCQA: Multimodal Cultural Question Answering for African Languages
Jan 09, 2026Africa is home to over one-third of the world's languages, yet remains underrepresented in AI research. We introduce Afri-MCQA, the first Multilingual Cultural Question-Answering benchmark covering 7.5k Q&A pairs across 15 African languages from 12 countries. The benchmark offers parallel English-African language Q&A pairs across text and speech modalities and was entirely created by native speakers. Benchmarking large language models (LLMs) on Afri-MCQA shows that open-weight models perform poorly across evaluated cultures, with near-zero accuracy on open-ended VQA when queried in native language or speech. To evaluate linguistic competence, we include control experiments meant to assess this specific aspect separate from cultural knowledge, and we observe significant performance gaps between native languages and English for both text and speech. These findings underscore the need for speech-first approaches, culturally grounded pretraining, and cross-lingual cultural transfer. To support more inclusive multimodal AI development in African languages, we release our Afri-MCQA under academic license or CC BY-NC 4.0 on HuggingFace (https://huggingface.co/datasets/Atnafu/Afri-MCQA)
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025



Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
Tell me Habibi, is it Real or Fake?
May 28, 2025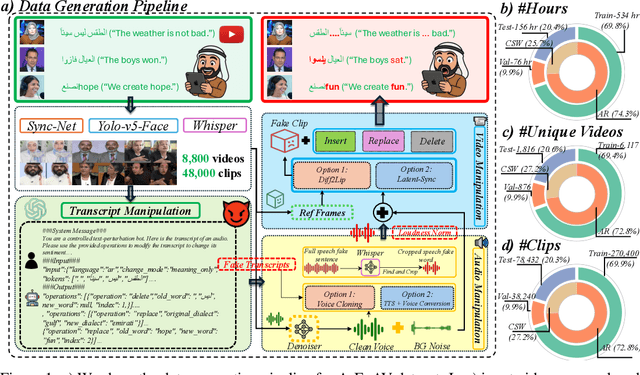
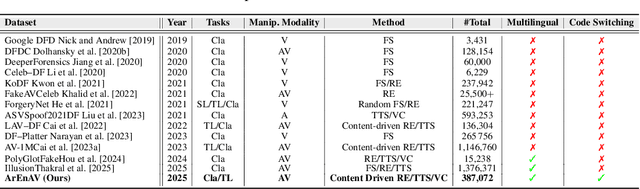
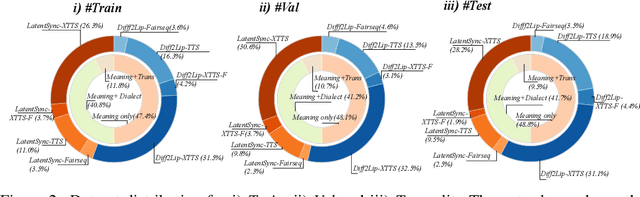

Deepfake generation methods are evolving fast, making fake media harder to detect and raising serious societal concerns. Most deepfake detection and dataset creation research focuses on monolingual content, often overlooking the challenges of multilingual and code-switched speech, where multiple languages are mixed within the same discourse. Code-switching, especially between Arabic and English, is common in the Arab world and is widely used in digital communication. This linguistic mixing poses extra challenges for deepfake detection, as it can confuse models trained mostly on monolingual data. To address this, we introduce \textbf{ArEnAV}, the first large-scale Arabic-English audio-visual deepfake dataset featuring intra-utterance code-switching, dialectal variation, and monolingual Arabic content. It \textbf{contains 387k videos and over 765 hours of real and fake videos}. Our dataset is generated using a novel pipeline integrating four Text-To-Speech and two lip-sync models, enabling comprehensive analysis of multilingual multimodal deepfake detection. We benchmark our dataset against existing monolingual and multilingual datasets, state-of-the-art deepfake detection models, and a human evaluation, highlighting its potential to advance deepfake research. The dataset can be accessed \href{https://huggingface.co/datasets/kartik060702/ArEnAV-Full}{here}.
How Individual Traits and Language Styles Shape Preferences In Open-ended User-LLM Interaction: A Preliminary Study
Apr 23, 2025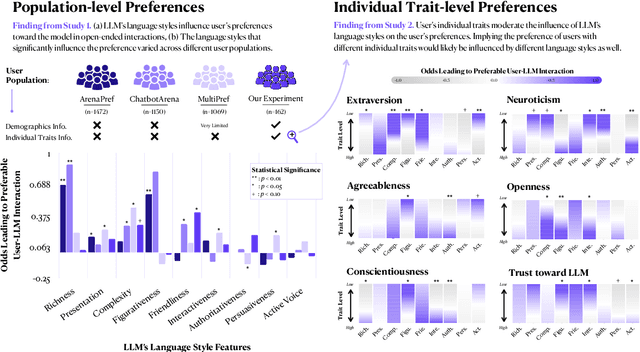

What makes an interaction with the LLM more preferable for the user? While it is intuitive to assume that information accuracy in the LLM's responses would be one of the influential variables, recent studies have found that inaccurate LLM's responses could still be preferable when they are perceived to be more authoritative, certain, well-articulated, or simply verbose. These variables interestingly fall under the broader category of language style, implying that the style in the LLM's responses might meaningfully influence users' preferences. This hypothesized dynamic could have double-edged consequences: enhancing the overall user experience while simultaneously increasing their susceptibility to risks such as LLM's misinformation or hallucinations. In this short paper, we present our preliminary studies in exploring this subject. Through a series of exploratory and experimental user studies, we found that LLM's language style does indeed influence user's preferences, but how and which language styles influence the preference varied across different user populations, and more interestingly, moderated by the user's very own individual traits. As a preliminary work, the findings in our studies should be interpreted with caution, particularly given the limitations in our samples, which still need wider demographic diversity and larger sample sizes. Our future directions will first aim to address these limitations, which would enable a more comprehensive joint effect analysis between the language style, individual traits, and preferences, and further investigate the potential causal relationship between and beyond these variables.
Enhancing Depression Detection via Question-wise Modality Fusion
Mar 26, 2025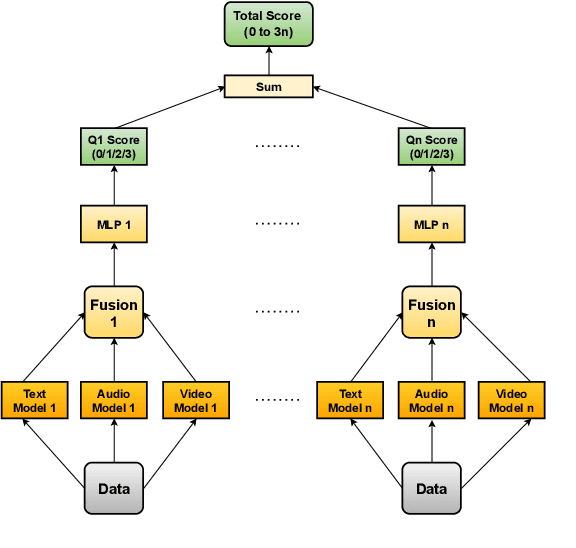
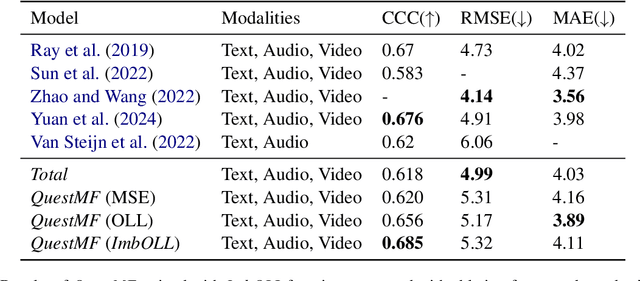
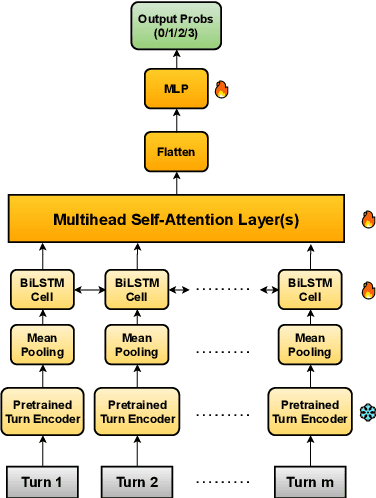
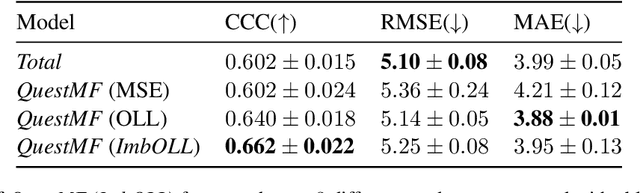
Depression is a highly prevalent and disabling condition that incurs substantial personal and societal costs. Current depression diagnosis involves determining the depression severity of a person through self-reported questionnaires or interviews conducted by clinicians. This often leads to delayed treatment and involves substantial human resources. Thus, several works try to automate the process using multimodal data. However, they usually overlook the following: i) The variable contribution of each modality for each question in the questionnaire and ii) Using ordinal classification for the task. This results in sub-optimal fusion and training methods. In this work, we propose a novel Question-wise Modality Fusion (QuestMF) framework trained with a novel Imbalanced Ordinal Log-Loss (ImbOLL) function to tackle these issues. The performance of our framework is comparable to the current state-of-the-art models on the E-DAIC dataset and enhances interpretability by predicting scores for each question. This will help clinicians identify an individual's symptoms, allowing them to customise their interventions accordingly. We also make the code for the QuestMF framework publicly available.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
ProverbEval: Exploring LLM Evaluation Challenges for Low-resource Language Understanding
Nov 07, 2024



With the rapid development of evaluation datasets to assess LLMs understanding across a wide range of subjects and domains, identifying a suitable language understanding benchmark has become increasingly challenging. In this work, we explore LLM evaluation challenges for low-resource language understanding and introduce ProverbEval, LLM evaluation benchmark for low-resource languages based on proverbs to focus on low-resource language understanding in culture-specific scenarios. We benchmark various LLMs and explore factors that create variability in the benchmarking process. We observed performance variances of up to 50%, depending on the order in which answer choices were presented in multiple-choice tasks. Native language proverb descriptions significantly improve tasks such as proverb generation, contributing to improved outcomes. Additionally, monolingual evaluations consistently outperformed their cross-lingual counterparts. We argue special attention must be given to the order of choices, choice of prompt language, task variability, and generation tasks when creating LLM evaluation benchmarks.
The Zeno's Paradox of `Low-Resource' Languages
Oct 28, 2024



The disparity in the languages commonly studied in Natural Language Processing (NLP) is typically reflected by referring to languages as low vs high-resourced. However, there is limited consensus on what exactly qualifies as a `low-resource language.' To understand how NLP papers define and study `low resource' languages, we qualitatively analyzed 150 papers from the ACL Anthology and popular speech-processing conferences that mention the keyword `low-resource.' Based on our analysis, we show how several interacting axes contribute to `low-resourcedness' of a language and why that makes it difficult to track progress for each individual language. We hope our work (1) elicits explicit definitions of the terminology when it is used in papers and (2) provides grounding for the different axes to consider when connoting a language as low-resource.
RelUNet: Relative Channel Fusion U-Net for Multichannel Speech Enhancement
Oct 07, 2024



Neural multi-channel speech enhancement models, in particular those based on the U-Net architecture, demonstrate promising performance and generalization potential. These models typically encode input channels independently, and integrate the channels during later stages of the network. In this paper, we propose a novel modification of these models by incorporating relative information from the outset, where each channel is processed in conjunction with a reference channel through stacking. This input strategy exploits comparative differences to adaptively fuse information between channels, thereby capturing crucial spatial information and enhancing the overall performance. The experiments conducted on the CHiME-3 dataset demonstrate improvements in speech enhancement metrics across various architectures.