 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025



Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
Knowledge Base Construction for Knowledge-Augmented Text-to-SQL
May 28, 2025Text-to-SQL aims to translate natural language queries into SQL statements, which is practical as it enables anyone to easily retrieve the desired information from databases. Recently, many existing approaches tackle this problem with Large Language Models (LLMs), leveraging their strong capability in understanding user queries and generating corresponding SQL code. Yet, the parametric knowledge in LLMs might be limited to covering all the diverse and domain-specific queries that require grounding in various database schemas, which makes generated SQLs less accurate oftentimes. To tackle this, we propose constructing the knowledge base for text-to-SQL, a foundational source of knowledge, from which we retrieve and generate the necessary knowledge for given queries. In particular, unlike existing approaches that either manually annotate knowledge or generate only a few pieces of knowledge for each query, our knowledge base is comprehensive, which is constructed based on a combination of all the available questions and their associated database schemas along with their relevant knowledge, and can be reused for unseen databases from different datasets and domains. We validate our approach on multiple text-to-SQL datasets, considering both the overlapping and non-overlapping database scenarios, where it outperforms relevant baselines substantially.
System Prompt Optimization with Meta-Learning
May 14, 2025Large Language Models (LLMs) have shown remarkable capabilities, with optimizing their input prompts playing a pivotal role in maximizing their performance. However, while LLM prompts consist of both the task-agnostic system prompts and task-specific user prompts, existing work on prompt optimization has focused on user prompts specific to individual queries or tasks, and largely overlooked the system prompt that is, once optimized, applicable across different tasks and domains. Motivated by this, we introduce the novel problem of bilevel system prompt optimization, whose objective is to design system prompts that are robust to diverse user prompts and transferable to unseen tasks. To tackle this problem, we then propose a meta-learning framework, which meta-learns the system prompt by optimizing it over various user prompts across multiple datasets, while simultaneously updating the user prompts in an iterative manner to ensure synergy between them. We conduct experiments on 14 unseen datasets spanning 5 different domains, on which we show that our approach produces system prompts that generalize effectively to diverse user prompts. Also, our findings reveal that the optimized system prompt enables rapid adaptation even to unseen tasks, requiring fewer optimization steps for test-time user prompts while achieving improved performance.
UniversalRAG: Retrieval-Augmented Generation over Multiple Corpora with Diverse Modalities and Granularities
Apr 29, 2025



Retrieval-Augmented Generation (RAG) has shown substantial promise in improving factual accuracy by grounding model responses with external knowledge relevant to queries. However, most existing RAG approaches are limited to a text-only corpus, and while recent efforts have extended RAG to other modalities such as images and videos, they typically operate over a single modality-specific corpus. In contrast, real-world queries vary widely in the type of knowledge they require, which a single type of knowledge source cannot address. To address this, we introduce UniversalRAG, a novel RAG framework designed to retrieve and integrate knowledge from heterogeneous sources with diverse modalities and granularities. Specifically, motivated by the observation that forcing all modalities into a unified representation space derived from a single combined corpus causes a modality gap, where the retrieval tends to favor items from the same modality as the query, we propose a modality-aware routing mechanism that dynamically identifies the most appropriate modality-specific corpus and performs targeted retrieval within it. Also, beyond modality, we organize each modality into multiple granularity levels, enabling fine-tuned retrieval tailored to the complexity and scope of the query. We validate UniversalRAG on 8 benchmarks spanning multiple modalities, showing its superiority over modality-specific and unified baselines.
Paper2Code: Automating Code Generation from Scientific Papers in Machine Learning
Apr 24, 2025



Despite the rapid growth of machine learning research, corresponding code implementations are often unavailable, making it slow and labor-intensive for researchers to reproduce results and build upon prior work. In the meantime, recent Large Language Models (LLMs) excel at understanding scientific documents and generating high-quality code. Inspired by this, we introduce PaperCoder, a multi-agent LLM framework that transforms machine learning papers into functional code repositories. PaperCoder operates in three stages: planning, where it constructs a high-level roadmap, designs the system architecture with diagrams, identifies file dependencies, and generates configuration files; analysis, which focuses on interpreting implementation-specific details; and generation, where modular, dependency-aware code is produced. Moreover, each phase is instantiated through a set of specialized agents designed to collaborate effectively across the pipeline. We then evaluate PaperCoder on generating code implementations from machine learning papers based on both model-based and human evaluations, specifically from the original paper authors, with author-released repositories as ground truth if available. Our results demonstrate the effectiveness of PaperCoder in creating high-quality, faithful implementations. Furthermore, it consistently shows strengths in the recently released PaperBench benchmark, surpassing strong baselines by substantial margins.
Sketch-of-Thought: Efficient LLM Reasoning with Adaptive Cognitive-Inspired Sketching
Mar 07, 2025Recent advances in large language models have demonstrated remarkable reasoning capabilities through Chain of Thought (CoT) prompting, but often at the cost of excessive verbosity in their intermediate outputs, which increases computational overhead. We introduce Sketch-of-Thought (SoT), a novel prompting framework that combines cognitive-inspired reasoning paradigms with linguistic constraints to minimize token usage while preserving reasoning accuracy. SoT is designed as a flexible framework that can incorporate any custom reasoning paradigms based on cognitive science, and we instantiate it with three such paradigms - Conceptual Chaining, Chunked Symbolism, and Expert Lexicons - each tailored to different reasoning tasks and selected dynamically via a lightweight routing model. Through comprehensive evaluation across 15 reasoning datasets with multiple languages and multimodal scenarios, we demonstrate that SoT achieves token reductions of 76% with negligible accuracy impact. In certain domains like mathematical and multi-hop reasoning, it even improves accuracy while using significantly fewer tokens. Our code is publicly available: https://www.github.com/SimonAytes/SoT.
Towards Better Understanding of Program-of-Thought Reasoning in Cross-Lingual and Multilingual Environments
Feb 25, 2025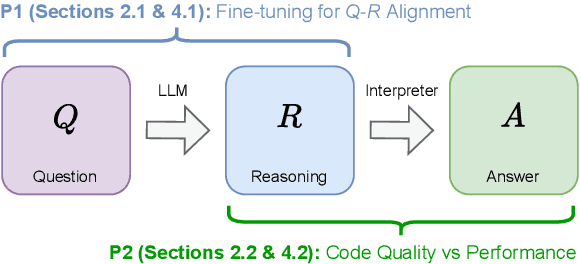

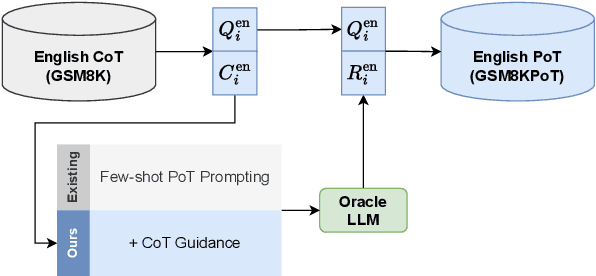

Multi-step reasoning is essential for large language models (LLMs), yet multilingual performance remains challenging. While Chain-of-Thought (CoT) prompting improves reasoning, it struggles with non-English languages due to the entanglement of reasoning and execution. Program-of-Thought (PoT) prompting separates reasoning from execution, offering a promising alternative but shifting the challenge to generating programs from non-English questions. We propose a framework to evaluate PoT by separating multilingual reasoning from code execution to examine (i) the impact of fine-tuning on question-reasoning alignment and (ii) how reasoning quality affects answer correctness. Our findings demonstrate that PoT fine-tuning substantially enhances multilingual reasoning, outperforming CoT fine-tuned models. We further demonstrate a strong correlation between reasoning quality (measured through code quality) and answer accuracy, highlighting its potential as a test-time performance improvement heuristic.
Real-time Verification and Refinement of Language Model Text Generation
Jan 14, 2025Large language models (LLMs) have shown remarkable performance across a wide range of natural language tasks. However, a critical challenge remains in that they sometimes generate factually incorrect answers. To address this, while many previous work has focused on identifying errors in their generation and further refining them, they are slow in deployment since they are designed to verify the response from LLMs only after their entire generation (from the first to last tokens) is done. Further, we observe that once LLMs generate incorrect tokens early on, there is a higher likelihood that subsequent tokens will also be factually incorrect. To this end, in this work, we propose Streaming-VR (Streaming Verification and Refinement), a novel approach designed to enhance the efficiency of verification and refinement of LLM outputs. Specifically, the proposed Streaming-VR enables on-the-fly verification and correction of tokens as they are being generated, similar to a streaming process, ensuring that each subset of tokens is checked and refined in real-time by another LLM as the LLM constructs its response. Through comprehensive evaluations on multiple datasets, we demonstrate that our approach not only enhances the factual accuracy of LLMs, but also offers a more efficient solution compared to prior refinement methods.
VideoRAG: Retrieval-Augmented Generation over Video Corpus
Jan 10, 2025


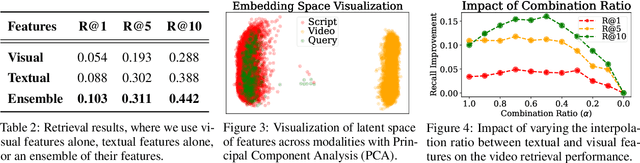
Retrieval-Augmented Generation (RAG) is a powerful strategy to address the issue of generating factually incorrect outputs in foundation models by retrieving external knowledge relevant to queries and incorporating it into their generation process. However, existing RAG approaches have primarily focused on textual information, with some recent advancements beginning to consider images, and they largely overlook videos, a rich source of multimodal knowledge capable of representing events, processes, and contextual details more effectively than any other modality. While a few recent studies explore the integration of videos in the response generation process, they either predefine query-associated videos without retrieving them according to queries, or convert videos into the textual descriptions without harnessing their multimodal richness. To tackle these, we introduce VideoRAG, a novel framework that not only dynamically retrieves relevant videos based on their relevance with queries but also utilizes both visual and textual information of videos in the output generation. Further, to operationalize this, our method revolves around the recent advance of Large Video Language Models (LVLMs), which enable the direct processing of video content to represent it for retrieval and seamless integration of the retrieved videos jointly with queries. We experimentally validate the effectiveness of VideoRAG, showcasing that it is superior to relevant baselines.