 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in the Noise: How Reasoning Models Fail with Contextual Distractors
Jan 12, 2026Recent advances in reasoning models and agentic AI systems have led to an increased reliance on diverse external information. However, this shift introduces input contexts that are inherently noisy, a reality that current sanitized benchmarks fail to capture. We introduce NoisyBench, a comprehensive benchmark that systematically evaluates model robustness across 11 datasets in RAG, reasoning, alignment, and tool-use tasks against diverse noise types, including random documents, irrelevant chat histories, and hard negative distractors. Our evaluation reveals a catastrophic performance drop of up to 80% in state-of-the-art models when faced with contextual distractors. Crucially, we find that agentic workflows often amplify these errors by over-trusting noisy tool outputs, and distractors can trigger emergent misalignment even without adversarial intent. We find that prompting, context engineering, SFT, and outcome-reward only RL fail to ensure robustness; in contrast, our proposed Rationale-Aware Reward (RARE) significantly strengthens resilience by incentivizing the identification of helpful information within noise. Finally, we uncover an inverse scaling trend where increased test-time computation leads to worse performance in noisy settings and demonstrate via attention visualization that models disproportionately focus on distractor tokens, providing vital insights for building the next generation of robust, reasoning-capable agents.
The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
May 15, 2025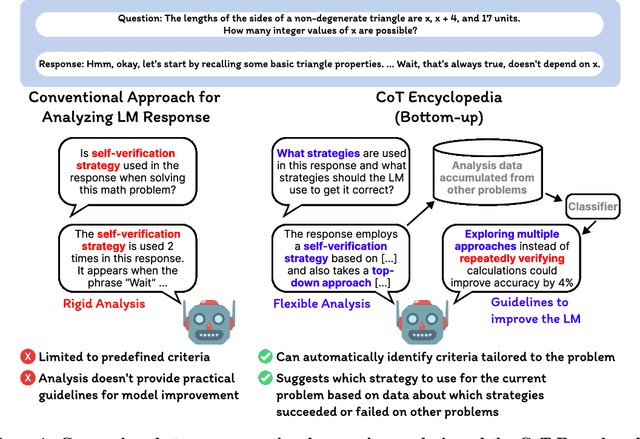
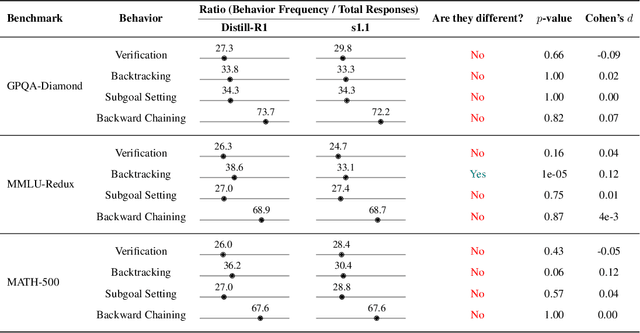
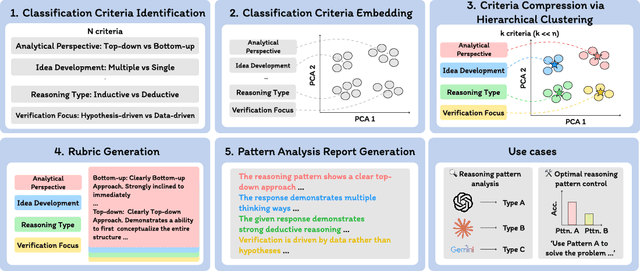
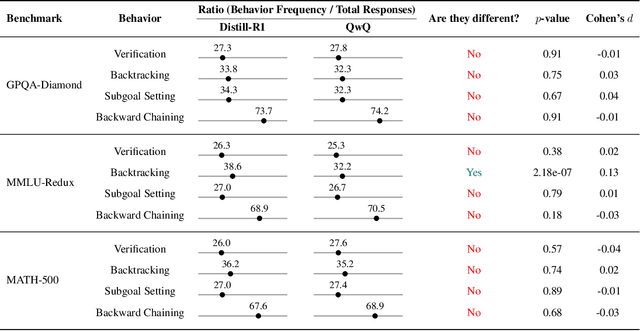
Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limited. While some prior works have attempted to categorize CoTs using predefined strategy types, such approaches are constrained by human intuition and fail to capture the full diversity of model behaviors. In this work, we introduce the CoT Encyclopedia, a bottom-up framework for analyzing and steering model reasoning. Our method automatically extracts diverse reasoning criteria from model-generated CoTs, embeds them into a semantic space, clusters them into representative categories, and derives contrastive rubrics to interpret reasoning behavior. Human evaluations show that this framework produces more interpretable and comprehensive analyses than existing methods. Moreover, we demonstrate that this understanding enables performance gains: we can predict which strategy a model is likely to use and guide it toward more effective alternatives. Finally, we provide practical insights, such as that training data format (e.g., free-form vs. multiple-choice) has a far greater impact on reasoning behavior than data domain, underscoring the importance of format-aware model design.
Paper2Code: Automating Code Generation from Scientific Papers in Machine Learning
Apr 24, 2025



Despite the rapid growth of machine learning research, corresponding code implementations are often unavailable, making it slow and labor-intensive for researchers to reproduce results and build upon prior work. In the meantime, recent Large Language Models (LLMs) excel at understanding scientific documents and generating high-quality code. Inspired by this, we introduce PaperCoder, a multi-agent LLM framework that transforms machine learning papers into functional code repositories. PaperCoder operates in three stages: planning, where it constructs a high-level roadmap, designs the system architecture with diagrams, identifies file dependencies, and generates configuration files; analysis, which focuses on interpreting implementation-specific details; and generation, where modular, dependency-aware code is produced. Moreover, each phase is instantiated through a set of specialized agents designed to collaborate effectively across the pipeline. We then evaluate PaperCoder on generating code implementations from machine learning papers based on both model-based and human evaluations, specifically from the original paper authors, with author-released repositories as ground truth if available. Our results demonstrate the effectiveness of PaperCoder in creating high-quality, faithful implementations. Furthermore, it consistently shows strengths in the recently released PaperBench benchmark, surpassing strong baselines by substantial margins.
Efficient Long Context Language Model Retrieval with Compression
Dec 24, 2024



Long Context Language Models (LCLMs) have emerged as a new paradigm to perform Information Retrieval (IR), which enables the direct ingestion and retrieval of information by processing an entire corpus in their single context, showcasing the potential to surpass traditional sparse and dense retrieval methods. However, processing a large number of passages within in-context for retrieval is computationally expensive, and handling their representations during inference further exacerbates the processing time; thus, we aim to make LCLM retrieval more efficient and potentially more effective with passage compression. Specifically, we propose a new compression approach tailored for LCLM retrieval, which is trained to maximize the retrieval performance while minimizing the length of the compressed passages. To accomplish this, we generate the synthetic data, where compressed passages are automatically created and labeled as chosen or rejected according to their retrieval success for a given query, and we train the proposed Compression model for Long context Retrieval (CoLoR) with this data via preference optimization while adding the length regularization loss on top of it to enforce brevity. Through extensive experiments on 9 datasets, we show that CoLoR improves the retrieval performance by 6% while compressing the in-context size by a factor of 1.91.
Rethinking Code Refinement: Learning to Judge Code Efficiency
Oct 29, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities in understanding and generating codes. Due to these capabilities, many recent methods are proposed to automatically refine the codes with LLMs. However, we should rethink that the refined codes (from LLMs and even humans) are not always more efficient than their original versions. On the other hand, running two different versions of codes and comparing them every time is not ideal and time-consuming. Therefore, in this work, we propose a novel method based on the code language model that is trained to judge the efficiency between two different codes (generated across humans and machines) by either classifying the superior one or predicting the relative improvement. We validate our method on multiple programming languages with multiple refinement steps, demonstrating that the proposed method can effectively distinguish between more and less efficient versions of code.
LG AI Research & KAIST at EHRSQL 2024: Self-Training Large Language Models with Pseudo-Labeled Unanswerable Questions for a Reliable Text-to-SQL System on EHRs
May 18, 2024



Text-to-SQL models are pivotal for making Electronic Health Records (EHRs) accessible to healthcare professionals without SQL knowledge. With the advancements in large language models, these systems have become more adept at translating complex questions into SQL queries. Nonetheless, the critical need for reliability in healthcare necessitates these models to accurately identify unanswerable questions or uncertain predictions, preventing misinformation. To address this problem, we present a self-training strategy using pseudo-labeled unanswerable questions to enhance the reliability of text-to-SQL models for EHRs. This approach includes a two-stage training process followed by a filtering method based on the token entropy and query execution. Our methodology's effectiveness is validated by our top performance in the EHRSQL 2024 shared task, showcasing the potential to improve healthcare decision-making through more reliable text-to-SQL systems.
Retrieval-Augmented Data Augmentation for Low-Resource Domain Tasks
Feb 21, 2024Despite large successes of recent language models on diverse tasks, they suffer from severe performance degeneration in low-resource settings with limited training data available. Many existing works tackle this problem by generating synthetic data from the training data and then training models on them, recently using Large Language Models (LLMs). However, in low-resource settings, the amount of seed data samples to use for data augmentation is very small, which makes generated samples suboptimal and less diverse. To tackle this challenge, we propose a novel method that augments training data by incorporating a wealth of examples from other datasets, along with the given training data. Specifically, we first retrieve the relevant instances from other datasets, such as their input-output pairs or contexts, based on their similarities with the given seed data, and then prompt LLMs to generate new samples with the contextual information within and across the original and retrieved samples. This approach can ensure that the generated data is not only relevant but also more diverse than what could be achieved using the limited seed data alone. We validate our proposed Retrieval-Augmented Data Augmentation (RADA) framework on multiple datasets under low-resource settings of training and test-time data augmentation scenarios, on which it outperforms existing LLM-powered data augmentation baselines.