 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
The Coverage Principle: A Framework for Understanding Compositional Generalization
May 26, 2025Large language models excel at pattern matching, yet often fall short in systematic compositional generalization. We propose the coverage principle: a data-centric framework showing that models relying primarily on pattern matching for compositional tasks cannot reliably generalize beyond substituting fragments that yield identical results when used in the same contexts. We demonstrate that this framework has a strong predictive power for the generalization capabilities of Transformers. First, we derive and empirically confirm that the training data required for two-hop generalization grows at least quadratically with the token set size, and the training data efficiency does not improve with 20x parameter scaling. Second, for compositional tasks with path ambiguity where one variable affects the output through multiple computational paths, we show that Transformers learn context-dependent state representations that undermine both performance and interoperability. Third, Chain-of-Thought supervision improves training data efficiency for multi-hop tasks but still struggles with path ambiguity. Finally, we outline a \emph{mechanism-based} taxonomy that distinguishes three ways neural networks can generalize: structure-based (bounded by coverage), property-based (leveraging algebraic invariances), and shared-operator (through function reuse). This conceptual lens contextualizes our results and highlights where new architectural ideas are needed to achieve systematic compositionally. Overall, the coverage principle provides a unified lens for understanding compositional reasoning, and underscores the need for fundamental architectural or training innovations to achieve truly systematic compositionality.
The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
May 15, 2025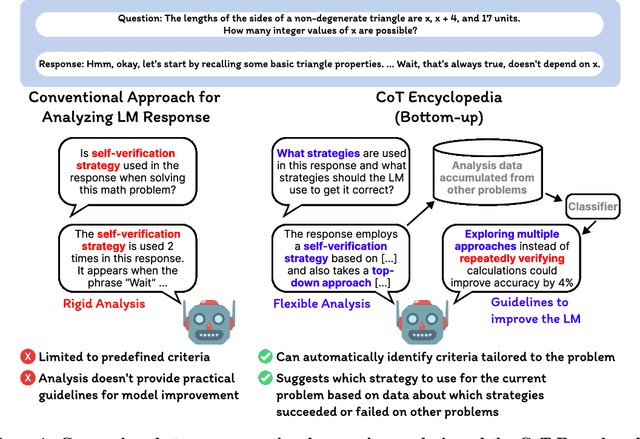
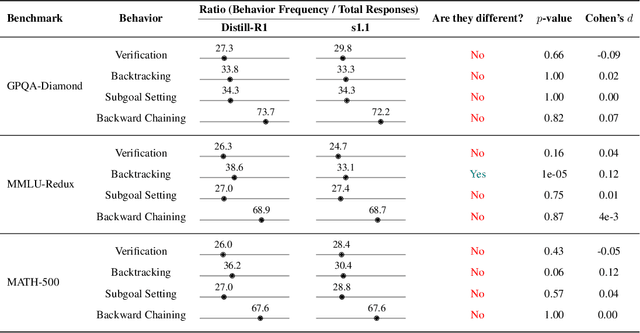
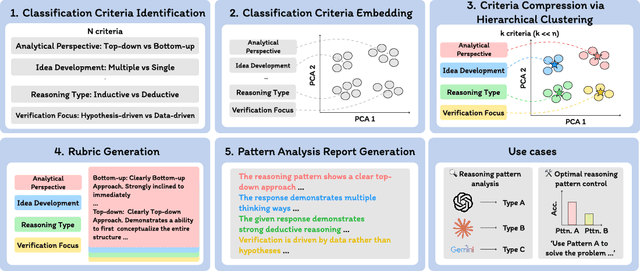
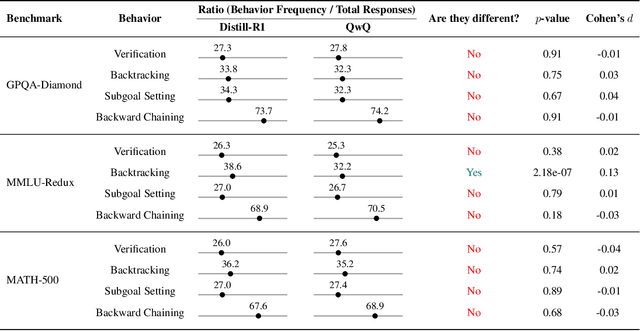
Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limited. While some prior works have attempted to categorize CoTs using predefined strategy types, such approaches are constrained by human intuition and fail to capture the full diversity of model behaviors. In this work, we introduce the CoT Encyclopedia, a bottom-up framework for analyzing and steering model reasoning. Our method automatically extracts diverse reasoning criteria from model-generated CoTs, embeds them into a semantic space, clusters them into representative categories, and derives contrastive rubrics to interpret reasoning behavior. Human evaluations show that this framework produces more interpretable and comprehensive analyses than existing methods. Moreover, we demonstrate that this understanding enables performance gains: we can predict which strategy a model is likely to use and guide it toward more effective alternatives. Finally, we provide practical insights, such as that training data format (e.g., free-form vs. multiple-choice) has a far greater impact on reasoning behavior than data domain, underscoring the importance of format-aware model design.
Color Universal Design Neural Network for the Color Vision Deficiencies
Feb 12, 2025Information regarding images should be visually understood by anyone, including those with color deficiency. However, such information is not recognizable if the color that seems to be distorted to the color deficiencies meets an adjacent object. The aim of this paper is to propose a color universal design network, called CUD-Net, that generates images that are visually understandable by individuals with color deficiency. CUD-Net is a convolutional deep neural network that can preserve color and distinguish colors for input images by regressing the node point of a piecewise linear function and using a specific filter for each image. To generate CUD images for color deficiencies, we follow a four-step process. First, we refine the CUD dataset based on specific criteria by color experts. Second, we expand the input image information through pre-processing that is specialized for color deficiency vision. Third, we employ a multi-modality fusion architecture to combine features and process the expanded images. Finally, we propose a conjugate loss function based on the composition of the predicted image through the model to address one-to-many problems that arise from the dataset. Our approach is able to produce high-quality CUD images that maintain color and contrast stability. The code for CUD-Net is available on the GitHub repository
Cognitive Map for Language Models: Optimal Planning via Verbally Representing the World Model
Jun 21, 2024



Language models have demonstrated impressive capabilities across various natural language processing tasks, yet they struggle with planning tasks requiring multi-step simulations. Inspired by human cognitive processes, this paper investigates the optimal planning power of language models that can construct a cognitive map of a given environment. Our experiments demonstrate that cognitive map significantly enhances the performance of both optimal and reachable planning generation ability in the Gridworld path planning task. We observe that our method showcases two key characteristics similar to human cognition: \textbf{generalization of its planning ability to extrapolated environments and rapid adaptation with limited training data.} We hope our findings in the Gridworld task provide insights into modeling human cognitive processes in language models, potentially leading to the development of more advanced and robust systems that better resemble human cognition.
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
Jun 17, 2024



Despite the recent observation that large language models (LLMs) can store substantial factual knowledge, there is a limited understanding of the mechanisms of how they acquire factual knowledge through pretraining. This work addresses this gap by studying how LLMs acquire factual knowledge during pretraining. The findings reveal several important insights into the dynamics of factual knowledge acquisition during pretraining. First, counterintuitively, we observe that pretraining on more data shows no significant improvement in the model's capability to acquire and maintain factual knowledge. Next, there is a power-law relationship between training steps and forgetting of memorization and generalization of factual knowledge, and LLMs trained with duplicated training data exhibit faster forgetting. Third, training LLMs with larger batch sizes can enhance the models' robustness to forgetting. Overall, our observations suggest that factual knowledge acquisition in LLM pretraining occurs by progressively increasing the probability of factual knowledge presented in the pretraining data at each step. However, this increase is diluted by subsequent forgetting. Based on this interpretation, we demonstrate that we can provide plausible explanations for recently observed behaviors of LLMs, such as the poor performance of LLMs on long-tail knowledge and the benefits of deduplicating the pretraining corpus.