 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning an Ensemble Token from Task-driven Priors in Facial Analysis
Jul 02, 2025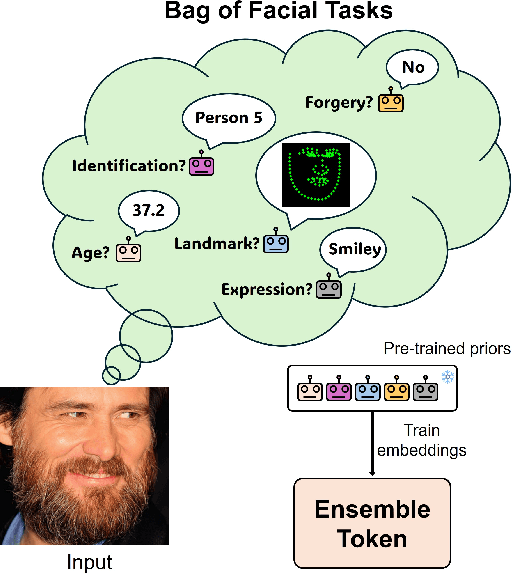
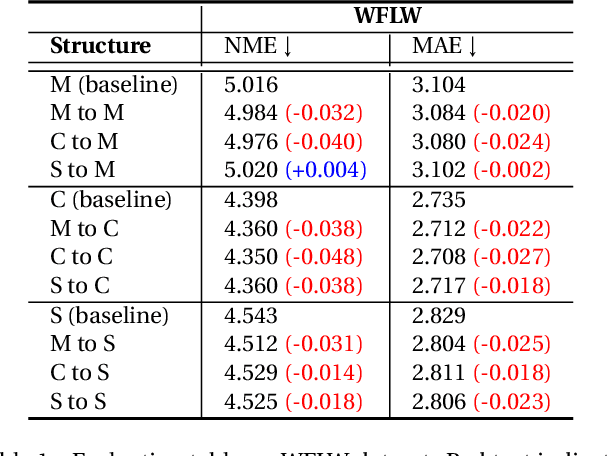
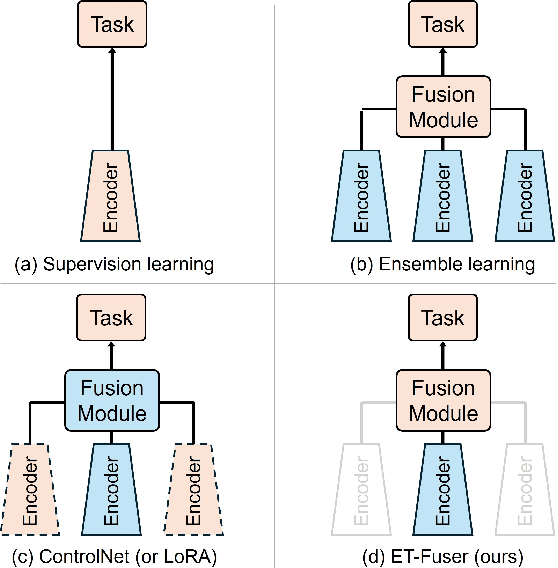
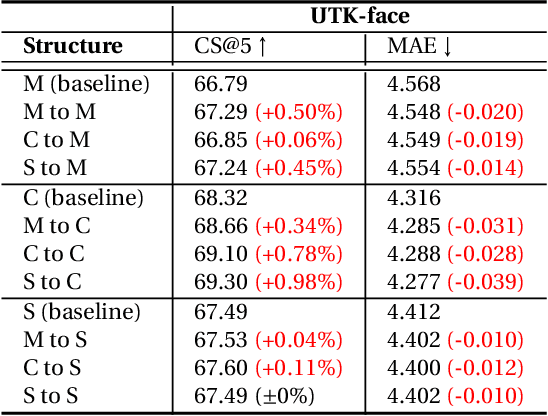
Facial analysis exhibits task-specific feature variations. While Convolutional Neural Networks (CNNs) have enabled the fine-grained representation of spatial information, Vision Transformers (ViTs) have facilitated the representation of semantic information at the patch level. Although the generalization of conventional methodologies has advanced visual interpretability, there remains paucity of research that preserves the unified feature representation on single task learning during the training process. In this work, we introduce ET-Fuser, a novel methodology for learning ensemble token by leveraging attention mechanisms based on task priors derived from pre-trained models for facial analysis. Specifically, we propose a robust prior unification learning method that generates a ensemble token within a self-attention mechanism, which shares the mutual information along the pre-trained encoders. This ensemble token approach offers high efficiency with negligible computational cost. Our results show improvements across a variety of facial analysis, with statistically significant enhancements observed in the feature representations.
Color Universal Design Neural Network for the Color Vision Deficiencies
Feb 12, 2025Information regarding images should be visually understood by anyone, including those with color deficiency. However, such information is not recognizable if the color that seems to be distorted to the color deficiencies meets an adjacent object. The aim of this paper is to propose a color universal design network, called CUD-Net, that generates images that are visually understandable by individuals with color deficiency. CUD-Net is a convolutional deep neural network that can preserve color and distinguish colors for input images by regressing the node point of a piecewise linear function and using a specific filter for each image. To generate CUD images for color deficiencies, we follow a four-step process. First, we refine the CUD dataset based on specific criteria by color experts. Second, we expand the input image information through pre-processing that is specialized for color deficiency vision. Third, we employ a multi-modality fusion architecture to combine features and process the expanded images. Finally, we propose a conjugate loss function based on the composition of the predicted image through the model to address one-to-many problems that arise from the dataset. Our approach is able to produce high-quality CUD images that maintain color and contrast stability. The code for CUD-Net is available on the GitHub repository
Full-scale Representation Guided Network for Retinal Vessel Segmentation
Jan 31, 2025



The U-Net architecture and its variants have remained state-of-the-art (SOTA) for retinal vessel segmentation over the past decade. In this study, we introduce a Full Scale Guided Network (FSG-Net), where the feature representation network with modernized convolution blocks extracts full-scale information and the guided convolution block refines that information. Attention-guided filter is introduced to the guided convolution block under the interpretation that the filter behaves like the unsharp mask filter. Passing full-scale information to the attention block allows for the generation of improved attention maps, which are then passed to the attention-guided filter, resulting in performance enhancement of the segmentation network. The structure preceding the guided convolution block can be replaced by any U-Net variant, which enhances the scalability of the proposed approach. For a fair comparison, we re-implemented recent studies available in public repositories to evaluate their scalability and reproducibility. Our experiments also show that the proposed network demonstrates competitive results compared to current SOTA models on various public datasets. Ablation studies demonstrate that the proposed model is competitive with much smaller parameter sizes. Lastly, by applying the proposed model to facial wrinkle segmentation, we confirmed the potential for scalability to similar tasks in other domains. Our code is available on https://github.com/ZombaSY/FSG-Net-pytorch.