 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoot-Selecting Fixed-Point Inversion for Rectified Flows via Trajectory Straightness
Jun 16, 2026Finding the initial noise that generates a given data sample, known as inversion, is a key component for downstream applications such as training-free image editing. Existing fixed-point inversion methods improve inversion accuracy by formulating each inversion step as a fixed-point problem, but they lack a principled mechanism for selecting among multiple fixed-point solutions that can arise in practice. We observe that different selections induce different inversion trajectories, leading to substantial variation in reconstruction and editing quality. For rectified flows, we further find that this variation is closely associated with trajectory straightness, motivating straightness as a principled selection criterion. We propose SelFix, a fixed-point inversion method that selects fixed-point solutions inducing straighter inverse trajectories while retaining convergence to an exact inverse root under standard local assumptions. Experiments on FLUX.1-dev and PIE-Bench show that SelFix improves fixed-point inversion, achieving stronger real-image reconstruction and better source-preserving prompt-based editing than prior inversion baselines. The code is available at https://github.com/seminkim/selfix.
Raon-OpenTTS: Open Models and Data for Robust Text-to-Speech
May 20, 2026Recent advances in text-to-speech (TTS) models show impressive speech naturalness and quality, yet the role of large-scale open data in driving this progress remains underexplored. In this work, we introduce Raon-OpenTTS, an open TTS model that performs competitively with state-of-the-art closed-data TTS models, and Raon-OpenTTS-Pool, a large-scale open dataset for reproducible TTS training. Raon-OpenTTS-Pool consists of 615K hours of 240M speech segments aggregated from publicly available English speech corpora and web-sourced recordings. With a model-based filtering pipeline applied to Raon-OpenTTS-Pool, we derive Raon-OpenTTS-Core, a curated, high-quality subset of 510K hours and 194M speech segments. Using Raon-OpenTTS-Core, we train Raon-OpenTTS, a series of diffusion transformer (DiT)-based TTS models from 0.3B to 1B parameters. On multiple benchmarks, Raon-OpenTTS-1B shows comparable performance to state-of-the-art models such as Qwen3-TTS and CosyVoice 3, which are trained on several million hours of proprietary speech data. Notably, on Seed-TTS-Eval, Raon-OpenTTS-1B achieves a word error rate (WER) of 1.78% and a speaker similarity (SIM) of 0.749, ranking second on WER and first on SIM among recent open-weight TTS baselines. On CV3-Hard-EN, Raon-OpenTTS-1B achieves a WER of 6.15% and a SIM of 0.775, ranking first on both metrics. Furthermore, to support robust evaluation, we introduce Raon-OpenTTS-Eval, a structured benchmark for assessing TTS robustness across diverse acoustic conditions including clean, noisy, in-the-wild, and expressive speech. On Raon-OpenTTS-Eval, Raon-OpenTTS-1B achieves the best average WER and SIM among all evaluated models, and the second-best human preference, as measured by comparative mean opinion score (CMOS). Our data pool, filtering pipeline, training code, and checkpoints are publicly available at https://github.com/krafton-ai/RAON-OpenTTS.
Training-Free Refinement of Flow Matching with Divergence-based Sampling
Apr 06, 2026Flow-based models learn a target distribution by modeling a marginal velocity field, defined as the average of sample-wise velocities connecting each sample from a simple prior to the target data. When sample-wise velocities conflict at the same intermediate state, however, this averaged velocity can misguide samples toward low-density regions, degrading generation quality. To address this issue, we propose the Flow Divergence Sampler (FDS), a training-free framework that refines intermediate states before each solver step. Our key finding reveals that the severity of this misguidance is quantified by the divergence of the marginal velocity field that is readily computable during inference with a well-optimized model. FDS exploits this signal to steer states toward less ambiguous regions. As a plug-and-play framework compatible with standard solvers and off-the-shelf flow backbones, FDS consistently improves fidelity across various generation tasks including text-to-image synthesis, and inverse problems.
FlowBind: Efficient Any-to-Any Generation with Bidirectional Flows
Dec 17, 2025



Any-to-any generation seeks to translate between arbitrary subsets of modalities, enabling flexible cross-modal synthesis. Despite recent success, existing flow-based approaches are challenged by their inefficiency, as they require large-scale datasets often with restrictive pairing constraints, incur high computational cost from modeling joint distribution, and rely on complex multi-stage training. We propose FlowBind, an efficient framework for any-to-any generation. Our approach is distinguished by its simplicity: it learns a shared latent space capturing cross-modal information, with modality-specific invertible flows bridging this latent to each modality. Both components are optimized jointly under a single flow-matching objective, and at inference the invertible flows act as encoders and decoders for direct translation across modalities. By factorizing interactions through the shared latent, FlowBind naturally leverages arbitrary subsets of modalities for training, and achieves competitive generation quality while substantially reducing data requirements and computational cost. Experiments on text, image, and audio demonstrate that FlowBind attains comparable quality while requiring up to 6x fewer parameters and training 10x faster than prior methods. The project page with code is available at https://yeonwoo378.github.io/official_flowbind.
Learning an Ensemble Token from Task-driven Priors in Facial Analysis
Jul 02, 2025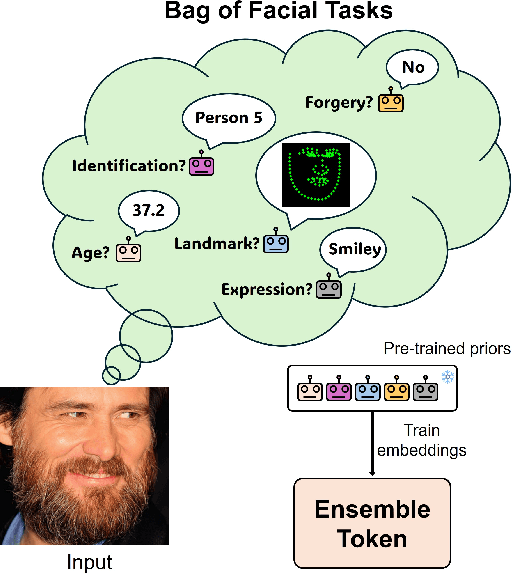
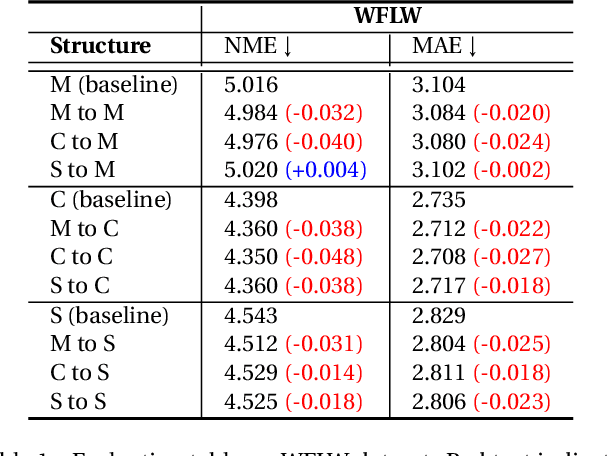
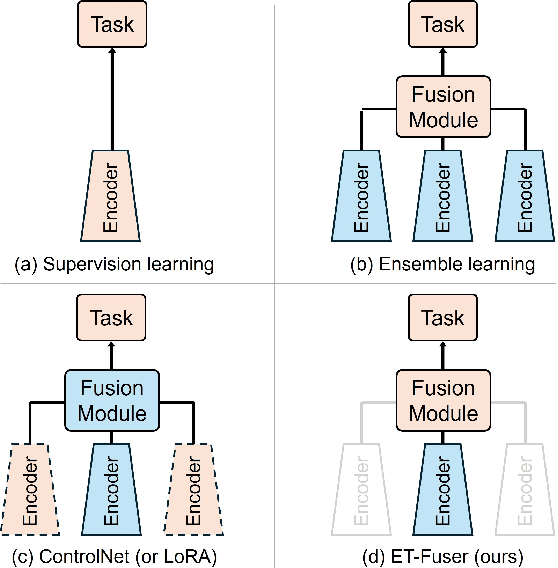
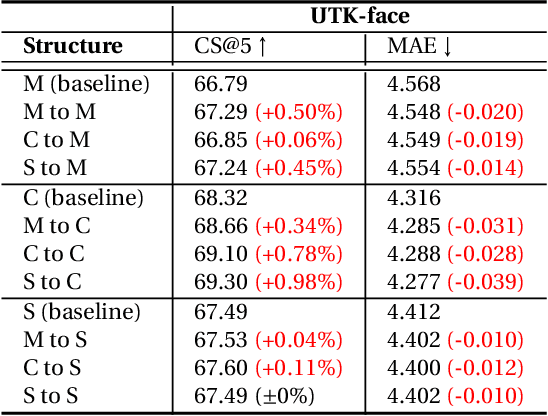
Facial analysis exhibits task-specific feature variations. While Convolutional Neural Networks (CNNs) have enabled the fine-grained representation of spatial information, Vision Transformers (ViTs) have facilitated the representation of semantic information at the patch level. Although the generalization of conventional methodologies has advanced visual interpretability, there remains paucity of research that preserves the unified feature representation on single task learning during the training process. In this work, we introduce ET-Fuser, a novel methodology for learning ensemble token by leveraging attention mechanisms based on task priors derived from pre-trained models for facial analysis. Specifically, we propose a robust prior unification learning method that generates a ensemble token within a self-attention mechanism, which shares the mutual information along the pre-trained encoders. This ensemble token approach offers high efficiency with negligible computational cost. Our results show improvements across a variety of facial analysis, with statistically significant enhancements observed in the feature representations.
Data Augmentation For Small Object using Fast AutoAugment
Jun 10, 2025



In recent years, there has been tremendous progress in object detection performance. However, despite these advances, the detection performance for small objects is significantly inferior to that of large objects. Detecting small objects is one of the most challenging and important problems in computer vision. To improve the detection performance for small objects, we propose an optimal data augmentation method using Fast AutoAugment. Through our proposed method, we can quickly find optimal augmentation policies that can overcome degradation when detecting small objects, and we achieve a 20% performance improvement on the DOTA dataset.
RA-Touch: Retrieval-Augmented Touch Understanding with Enriched Visual Data
May 20, 2025Visuo-tactile perception aims to understand an object's tactile properties, such as texture, softness, and rigidity. However, the field remains underexplored because collecting tactile data is costly and labor-intensive. We observe that visually distinct objects can exhibit similar surface textures or material properties. For example, a leather sofa and a leather jacket have different appearances but share similar tactile properties. This implies that tactile understanding can be guided by material cues in visual data, even without direct tactile supervision. In this paper, we introduce RA-Touch, a retrieval-augmented framework that improves visuo-tactile perception by leveraging visual data enriched with tactile semantics. We carefully recaption a large-scale visual dataset with tactile-focused descriptions, enabling the model to access tactile semantics typically absent from conventional visual datasets. A key challenge remains in effectively utilizing these tactile-aware external descriptions. RA-Touch addresses this by retrieving visual-textual representations aligned with tactile inputs and integrating them to focus on relevant textural and material properties. By outperforming prior methods on the TVL benchmark, our method demonstrates the potential of retrieval-based visual reuse for tactile understanding. Code is available at https://aim-skku.github.io/RA-Touch
FADEL: Uncertainty-aware Fake Audio Detection with Evidential Deep Learning
Apr 22, 2025



Recently, fake audio detection has gained significant attention, as advancements in speech synthesis and voice conversion have increased the vulnerability of automatic speaker verification (ASV) systems to spoofing attacks. A key challenge in this task is generalizing models to detect unseen, out-of-distribution (OOD) attacks. Although existing approaches have shown promising results, they inherently suffer from overconfidence issues due to the usage of softmax for classification, which can produce unreliable predictions when encountering unpredictable spoofing attempts. To deal with this limitation, we propose a novel framework called fake audio detection with evidential learning (FADEL). By modeling class probabilities with a Dirichlet distribution, FADEL incorporates model uncertainty into its predictions, thereby leading to more robust performance in OOD scenarios. Experimental results on the ASVspoof2019 Logical Access (LA) and ASVspoof2021 LA datasets indicate that the proposed method significantly improves the performance of baseline models. Furthermore, we demonstrate the validity of uncertainty estimation by analyzing a strong correlation between average uncertainty and equal error rate (EER) across different spoofing algorithms.
Full-scale Representation Guided Network for Retinal Vessel Segmentation
Jan 31, 2025



The U-Net architecture and its variants have remained state-of-the-art (SOTA) for retinal vessel segmentation over the past decade. In this study, we introduce a Full Scale Guided Network (FSG-Net), where the feature representation network with modernized convolution blocks extracts full-scale information and the guided convolution block refines that information. Attention-guided filter is introduced to the guided convolution block under the interpretation that the filter behaves like the unsharp mask filter. Passing full-scale information to the attention block allows for the generation of improved attention maps, which are then passed to the attention-guided filter, resulting in performance enhancement of the segmentation network. The structure preceding the guided convolution block can be replaced by any U-Net variant, which enhances the scalability of the proposed approach. For a fair comparison, we re-implemented recent studies available in public repositories to evaluate their scalability and reproducibility. Our experiments also show that the proposed network demonstrates competitive results compared to current SOTA models on various public datasets. Ablation studies demonstrate that the proposed model is competitive with much smaller parameter sizes. Lastly, by applying the proposed model to facial wrinkle segmentation, we confirmed the potential for scalability to similar tasks in other domains. Our code is available on https://github.com/ZombaSY/FSG-Net-pytorch.
Simulation-Free Training of Neural ODEs on Paired Data
Oct 30, 2024In this work, we investigate a method for simulation-free training of Neural Ordinary Differential Equations (NODEs) for learning deterministic mappings between paired data. Despite the analogy of NODEs as continuous-depth residual networks, their application in typical supervised learning tasks has not been popular, mainly due to the large number of function evaluations required by ODE solvers and numerical instability in gradient estimation. To alleviate this problem, we employ the flow matching framework for simulation-free training of NODEs, which directly regresses the parameterized dynamics function to a predefined target velocity field. Contrary to generative tasks, however, we show that applying flow matching directly between paired data can often lead to an ill-defined flow that breaks the coupling of the data pairs (e.g., due to crossing trajectories). We propose a simple extension that applies flow matching in the embedding space of data pairs, where the embeddings are learned jointly with the dynamic function to ensure the validity of the flow which is also easier to learn. We demonstrate the effectiveness of our method on both regression and classification tasks, where our method outperforms existing NODEs with a significantly lower number of function evaluations. The code is available at https://github.com/seminkim/simulation-free-node.