 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Graphs Beyond Grids: Benchmark for Maritime Anomaly Detection
Dec 23, 2025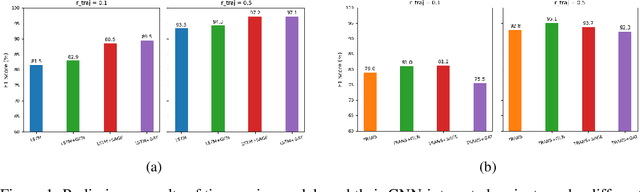

Spatio-temporal graph neural networks (ST-GNNs) have achieved notable success in structured domains such as road traffic and public transportation, where spatial entities can be naturally represented as fixed nodes. In contrast, many real-world systems including maritime traffic lack such fixed anchors, making the construction of spatio-temporal graphs a fundamental challenge. Anomaly detection in these non-grid environments is particularly difficult due to the absence of canonical reference points, the sparsity and irregularity of trajectories, and the fact that anomalies may manifest at multiple granularities. In this work, we introduce a novel benchmark dataset for anomaly detection in the maritime domain, extending the Open Maritime Traffic Analysis Dataset (OMTAD) into a benchmark tailored for graph-based anomaly detection. Our dataset enables systematic evaluation across three different granularities: node-level, edge-level, and graph-level anomalies. We plan to employ two specialized LLM-based agents: \emph{Trajectory Synthesizer} and \emph{Anomaly Injector} to construct richer interaction contexts and generate semantically meaningful anomalies. We expect this benchmark to promote reproducibility and to foster methodological advances in anomaly detection for non-grid spatio-temporal systems.
Adaptive Sparsified Graph Learning Framework for Vessel Behavior Anomalies
Feb 20, 2025Graph neural networks have emerged as a powerful tool for learning spatiotemporal interactions. However, conventional approaches often rely on predefined graphs, which may obscure the precise relationships being modeled. Additionally, existing methods typically define nodes based on fixed spatial locations, a strategy that is ill-suited for dynamic environments like maritime environments. Our method introduces an innovative graph representation where timestamps are modeled as distinct nodes, allowing temporal dependencies to be explicitly captured through graph edges. This setup is extended to construct a multi-ship graph that effectively captures spatial interactions while preserving graph sparsity. The graph is processed using Graph Convolutional Network layers to capture spatiotemporal patterns, with a forecasting layer for feature prediction and a Variational Graph Autoencoder for reconstruction, enabling robust anomaly detection.
SegINR: Segment-wise Implicit Neural Representation for Sequence Alignment in Neural Text-to-Speech
Oct 07, 2024



We present SegINR, a novel approach to neural Text-to-Speech (TTS) that addresses sequence alignment without relying on an auxiliary duration predictor and complex autoregressive (AR) or non-autoregressive (NAR) frame-level sequence modeling. SegINR simplifies the process by converting text sequences directly into frame-level features. It leverages an optimal text encoder to extract embeddings, transforming each into a segment of frame-level features using a conditional implicit neural representation (INR). This method, named segment-wise INR (SegINR), models temporal dynamics within each segment and autonomously defines segment boundaries, reducing computational costs. We integrate SegINR into a two-stage TTS framework, using it for semantic token prediction. Our experiments in zero-shot adaptive TTS scenarios demonstrate that SegINR outperforms conventional methods in speech quality with computational efficiency.
CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction
Oct 02, 2024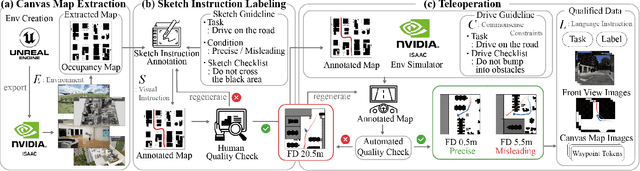
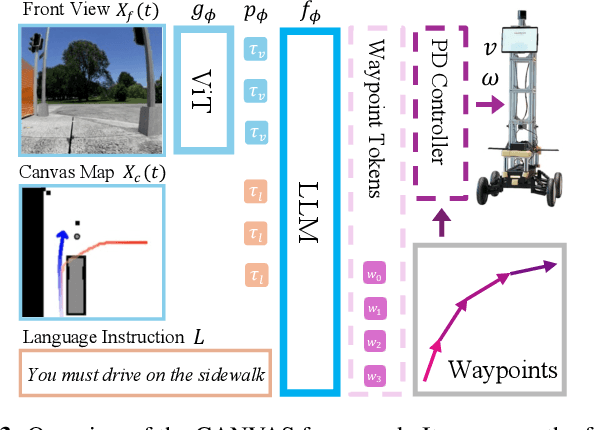
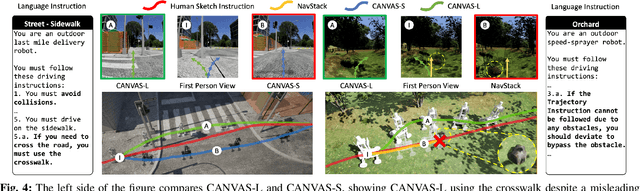
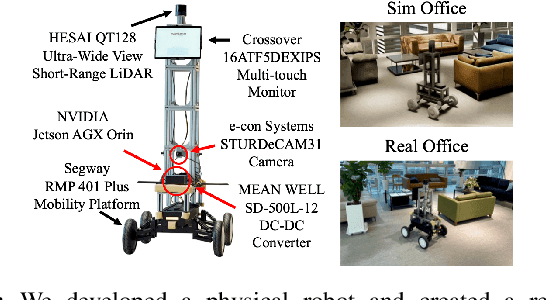
Real-life robot navigation involves more than just reaching a destination; it requires optimizing movements while addressing scenario-specific goals. An intuitive way for humans to express these goals is through abstract cues like verbal commands or rough sketches. Such human guidance may lack details or be noisy. Nonetheless, we expect robots to navigate as intended. For robots to interpret and execute these abstract instructions in line with human expectations, they must share a common understanding of basic navigation concepts with humans. To this end, we introduce CANVAS, a novel framework that combines visual and linguistic instructions for commonsense-aware navigation. Its success is driven by imitation learning, enabling the robot to learn from human navigation behavior. We present COMMAND, a comprehensive dataset with human-annotated navigation results, spanning over 48 hours and 219 km, designed to train commonsense-aware navigation systems in simulated environments. Our experiments show that CANVAS outperforms the strong rule-based system ROS NavStack across all environments, demonstrating superior performance with noisy instructions. Notably, in the orchard environment, where ROS NavStack records a 0% total success rate, CANVAS achieves a total success rate of 67%. CANVAS also closely aligns with human demonstrations and commonsense constraints, even in unseen environments. Furthermore, real-world deployment of CANVAS showcases impressive Sim2Real transfer with a total success rate of 69%, highlighting the potential of learning from human demonstrations in simulated environments for real-world applications.
High Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked Language Model
Jun 25, 2024
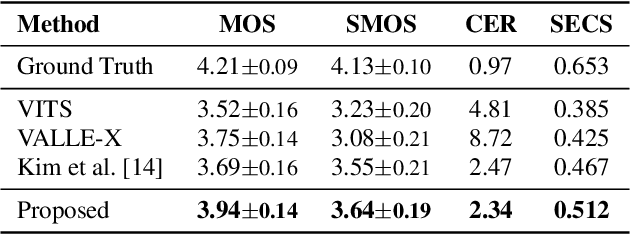
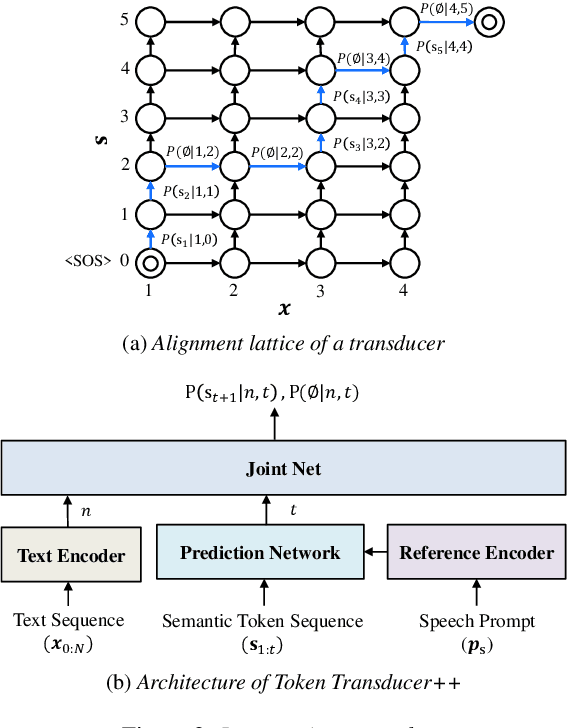

We propose a novel two-stage text-to-speech (TTS) framework with two types of discrete tokens, i.e., semantic and acoustic tokens, for high-fidelity speech synthesis. It features two core components: the Interpreting module, which processes text and a speech prompt into semantic tokens focusing on linguistic contents and alignment, and the Speaking module, which captures the timbre of the target voice to generate acoustic tokens from semantic tokens, enriching speech reconstruction. The Interpreting stage employs a transducer for its robustness in aligning text to speech. In contrast, the Speaking stage utilizes a Conformer-based architecture integrated with a Grouped Masked Language Model (G-MLM) to boost computational efficiency. Our experiments verify that this innovative structure surpasses the conventional models in the zero-shot scenario in terms of speech quality and speaker similarity.
MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
Jun 10, 2024


In this paper, we propose MakeSinger, a semi-supervised training method for singing voice synthesis (SVS) via classifier-free diffusion guidance. The challenge in SVS lies in the costly process of gathering aligned sets of text, pitch, and audio data. MakeSinger enables the training of the diffusion-based SVS model from any speech and singing voice data regardless of its labeling, thereby enhancing the quality of generated voices with large amount of unlabeled data. At inference, our novel dual guiding mechanism gives text and pitch guidance on the reverse diffusion step by estimating the score of masked input. Experimental results show that the model trained in a semi-supervised manner outperforms other baselines trained only on the labeled data in terms of pronunciation, pitch accuracy and overall quality. Furthermore, we demonstrate that by adding Text-to-Speech (TTS) data in training, the model can synthesize the singing voices of TTS speakers even without their singing voices.
Exploiting Semantic Reconstruction to Mitigate Hallucinations in Vision-Language Models
Mar 26, 2024Hallucinations in vision-language models pose a significant challenge to their reliability, particularly in the generation of long captions. Current methods fall short of accurately identifying and mitigating these hallucinations. To address this issue, we introduce ESREAL, a novel unsupervised learning framework designed to suppress the generation of hallucinations through accurate localization and penalization of hallucinated tokens. Initially, ESREAL creates a reconstructed image based on the generated caption and aligns its corresponding regions with those of the original image. This semantic reconstruction aids in identifying both the presence and type of token-level hallucinations within the generated caption. Subsequently, ESREAL computes token-level hallucination scores by assessing the semantic similarity of aligned regions based on the type of hallucination. Finally, ESREAL employs a proximal policy optimization algorithm, where it selectively penalizes hallucinated tokens according to their token-level hallucination scores. Our framework notably reduces hallucinations in LLaVA, InstructBLIP, and mPLUG-Owl2 by 32.81%, 27.08%, and 7.46% on the CHAIR metric. This improvement is achieved solely through signals derived from the image itself, without the need for any image-text pairs.
Utilizing Neural Transducers for Two-Stage Text-to-Speech via Semantic Token Prediction
Jan 03, 2024

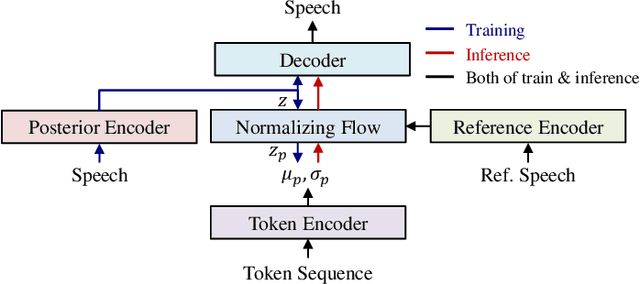

We propose a novel text-to-speech (TTS) framework centered around a neural transducer. Our approach divides the whole TTS pipeline into semantic-level sequence-to-sequence (seq2seq) modeling and fine-grained acoustic modeling stages, utilizing discrete semantic tokens obtained from wav2vec2.0 embeddings. For a robust and efficient alignment modeling, we employ a neural transducer named token transducer for the semantic token prediction, benefiting from its hard monotonic alignment constraints. Subsequently, a non-autoregressive (NAR) speech generator efficiently synthesizes waveforms from these semantic tokens. Additionally, a reference speech controls temporal dynamics and acoustic conditions at each stage. This decoupled framework reduces the training complexity of TTS while allowing each stage to focus on semantic and acoustic modeling. Our experimental results on zero-shot adaptive TTS demonstrate that our model surpasses the baseline in terms of speech quality and speaker similarity, both objectively and subjectively. We also delve into the inference speed and prosody control capabilities of our approach, highlighting the potential of neural transducers in TTS frameworks.
Efficient Parallel Audio Generation using Group Masked Language Modeling
Jan 02, 2024



We present a fast and high-quality codec language model for parallel audio generation. While SoundStorm, a state-of-the-art parallel audio generation model, accelerates inference speed compared to autoregressive models, it still suffers from slow inference due to iterative sampling. To resolve this problem, we propose Group-Masked Language Modeling~(G-MLM) and Group Iterative Parallel Decoding~(G-IPD) for efficient parallel audio generation. Both the training and sampling schemes enable the model to synthesize high-quality audio with a small number of iterations by effectively modeling the group-wise conditional dependencies. In addition, our model employs a cross-attention-based architecture to capture the speaker style of the prompt voice and improves computational efficiency. Experimental results demonstrate that our proposed model outperforms the baselines in prompt-based audio generation.
Transduce and Speak: Neural Transducer for Text-to-Speech with Semantic Token Prediction
Nov 08, 2023We introduce a text-to-speech(TTS) framework based on a neural transducer. We use discretized semantic tokens acquired from wav2vec2.0 embeddings, which makes it easy to adopt a neural transducer for the TTS framework enjoying its monotonic alignment constraints. The proposed model first generates aligned semantic tokens using the neural transducer, then synthesizes a speech sample from the semantic tokens using a non-autoregressive(NAR) speech generator. This decoupled framework alleviates the training complexity of TTS and allows each stage to focus on 1) linguistic and alignment modeling and 2) fine-grained acoustic modeling, respectively. Experimental results on the zero-shot adaptive TTS show that the proposed model exceeds the baselines in speech quality and speaker similarity via objective and subjective measures. We also investigate the inference speed and prosody controllability of our proposed model, showing the potential of the neural transducer for TTS frameworks.