 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked Language Model
Jun 25, 2024
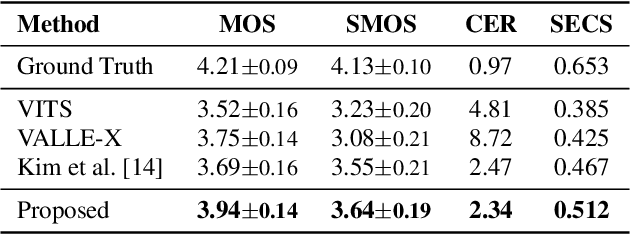
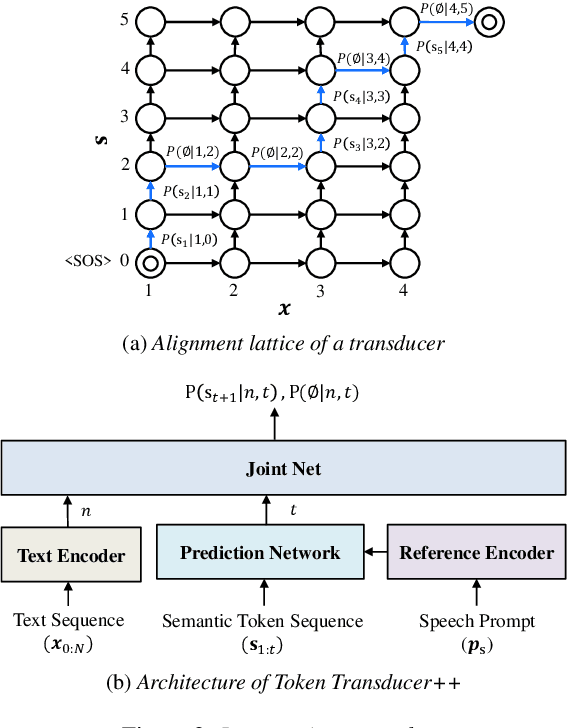

We propose a novel two-stage text-to-speech (TTS) framework with two types of discrete tokens, i.e., semantic and acoustic tokens, for high-fidelity speech synthesis. It features two core components: the Interpreting module, which processes text and a speech prompt into semantic tokens focusing on linguistic contents and alignment, and the Speaking module, which captures the timbre of the target voice to generate acoustic tokens from semantic tokens, enriching speech reconstruction. The Interpreting stage employs a transducer for its robustness in aligning text to speech. In contrast, the Speaking stage utilizes a Conformer-based architecture integrated with a Grouped Masked Language Model (G-MLM) to boost computational efficiency. Our experiments verify that this innovative structure surpasses the conventional models in the zero-shot scenario in terms of speech quality and speaker similarity.
Latent Filling: Latent Space Data Augmentation for Zero-shot Speech Synthesis
Oct 05, 2023Previous works in zero-shot text-to-speech (ZS-TTS) have attempted to enhance its systems by enlarging the training data through crowd-sourcing or augmenting existing speech data. However, the use of low-quality data has led to a decline in the overall system performance. To avoid such degradation, instead of directly augmenting the input data, we propose a latent filling (LF) method that adopts simple but effective latent space data augmentation in the speaker embedding space of the ZS-TTS system. By incorporating a consistency loss, LF can be seamlessly integrated into existing ZS-TTS systems without the need for additional training stages. Experimental results show that LF significantly improves speaker similarity while preserving speech quality.
GC-TTS: Few-shot Speaker Adaptation with Geometric Constraints
Aug 16, 2021

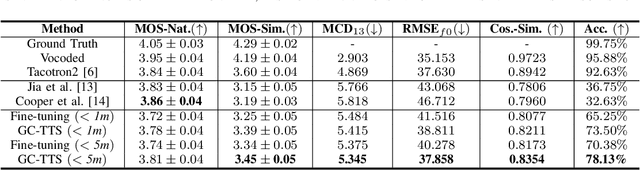

Few-shot speaker adaptation is a specific Text-to-Speech (TTS) system that aims to reproduce a novel speaker's voice with a few training data. While numerous attempts have been made to the few-shot speaker adaptation system, there is still a gap in terms of speaker similarity to the target speaker depending on the amount of data. To bridge the gap, we propose GC-TTS which achieves high-quality speaker adaptation with significantly improved speaker similarity. Specifically, we leverage two geometric constraints to learn discriminative speaker representations. Here, a TTS model is pre-trained for base speakers with a sufficient amount of data, and then fine-tuned for novel speakers on a few minutes of data with two geometric constraints. Two geometric constraints enable the model to extract discriminative speaker embeddings from limited data, which leads to the synthesis of intelligible speech. We discuss and verify the effectiveness of GC-TTS by comparing it with popular and essential methods. The experimental results demonstrate that GC-TTS generates high-quality speech from only a few minutes of training data, outperforming standard techniques in terms of speaker similarity to the target speaker.
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Jun 14, 2021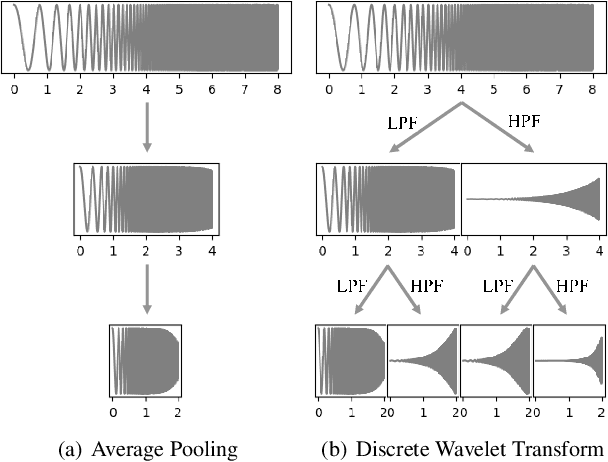
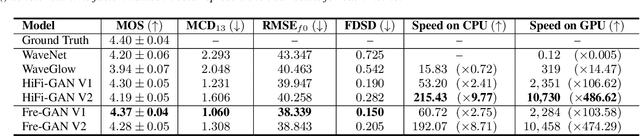
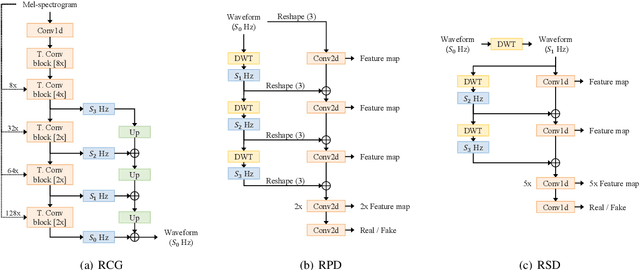
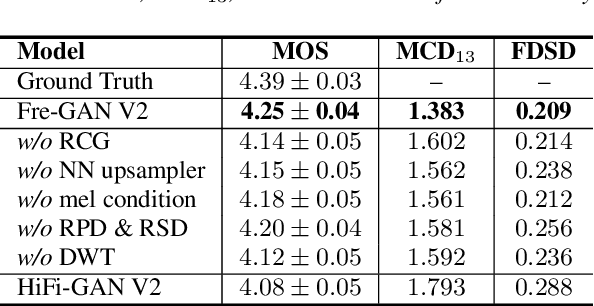
Although recent works on neural vocoder have improved the quality of synthesized audio, there still exists a gap between generated and ground-truth audio in frequency space. This difference leads to spectral artifacts such as hissing noise or reverberation, and thus degrades the sample quality. In this paper, we propose Fre-GAN which achieves frequency-consistent audio synthesis with highly improved generation quality. Specifically, we first present resolution-connected generator and resolution-wise discriminators, which help learn various scales of spectral distributions over multiple frequency bands. Additionally, to reproduce high-frequency components accurately, we leverage discrete wavelet transform in the discriminators. From our experiments, Fre-GAN achieves high-fidelity waveform generation with a gap of only 0.03 MOS compared to ground-truth audio while outperforming standard models in quality.