 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGC-TTS: Few-shot Speaker Adaptation with Geometric Constraints
Paper and Code


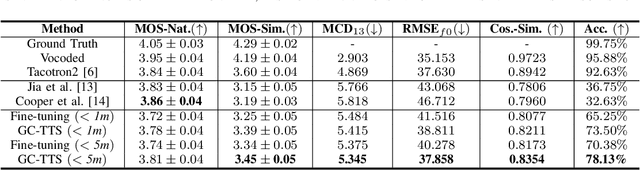

Few-shot speaker adaptation is a specific Text-to-Speech (TTS) system that aims to reproduce a novel speaker's voice with a few training data. While numerous attempts have been made to the few-shot speaker adaptation system, there is still a gap in terms of speaker similarity to the target speaker depending on the amount of data. To bridge the gap, we propose GC-TTS which achieves high-quality speaker adaptation with significantly improved speaker similarity. Specifically, we leverage two geometric constraints to learn discriminative speaker representations. Here, a TTS model is pre-trained for base speakers with a sufficient amount of data, and then fine-tuned for novel speakers on a few minutes of data with two geometric constraints. Two geometric constraints enable the model to extract discriminative speaker embeddings from limited data, which leads to the synthesis of intelligible speech. We discuss and verify the effectiveness of GC-TTS by comparing it with popular and essential methods. The experimental results demonstrate that GC-TTS generates high-quality speech from only a few minutes of training data, outperforming standard techniques in terms of speaker similarity to the target speaker.