 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Reasoning for Few-Shot Object Detection
Nov 02, 2022Although modern object detectors rely heavily on a significant amount of training data, humans can easily detect novel objects using a few training examples. The mechanism of the human visual system is to interpret spatial relationships among various objects and this process enables us to exploit contextual information by considering the co-occurrence of objects. Thus, we propose a spatial reasoning framework that detects novel objects with only a few training examples in a context. We infer geometric relatedness between novel and base RoIs (Region-of-Interests) to enhance the feature representation of novel categories using an object detector well trained on base categories. We employ a graph convolutional network as the RoIs and their relatedness are defined as nodes and edges, respectively. Furthermore, we present spatial data augmentation to overcome the few-shot environment where all objects and bounding boxes in an image are resized randomly. Using the PASCAL VOC and MS COCO datasets, we demonstrate that the proposed method significantly outperforms the state-of-the-art methods and verify its efficacy through extensive ablation studies.
GC-TTS: Few-shot Speaker Adaptation with Geometric Constraints
Aug 16, 2021

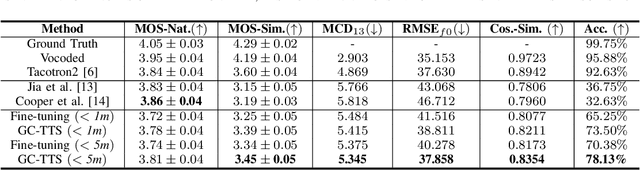

Few-shot speaker adaptation is a specific Text-to-Speech (TTS) system that aims to reproduce a novel speaker's voice with a few training data. While numerous attempts have been made to the few-shot speaker adaptation system, there is still a gap in terms of speaker similarity to the target speaker depending on the amount of data. To bridge the gap, we propose GC-TTS which achieves high-quality speaker adaptation with significantly improved speaker similarity. Specifically, we leverage two geometric constraints to learn discriminative speaker representations. Here, a TTS model is pre-trained for base speakers with a sufficient amount of data, and then fine-tuned for novel speakers on a few minutes of data with two geometric constraints. Two geometric constraints enable the model to extract discriminative speaker embeddings from limited data, which leads to the synthesis of intelligible speech. We discuss and verify the effectiveness of GC-TTS by comparing it with popular and essential methods. The experimental results demonstrate that GC-TTS generates high-quality speech from only a few minutes of training data, outperforming standard techniques in terms of speaker similarity to the target speaker.
Weakly Supervised Thoracic Disease Localization via Disease Masks
Jan 25, 2021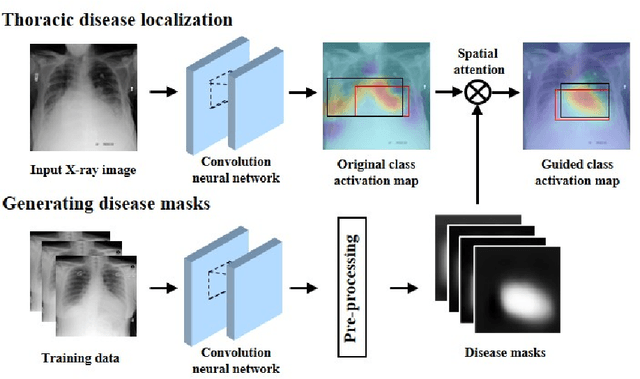
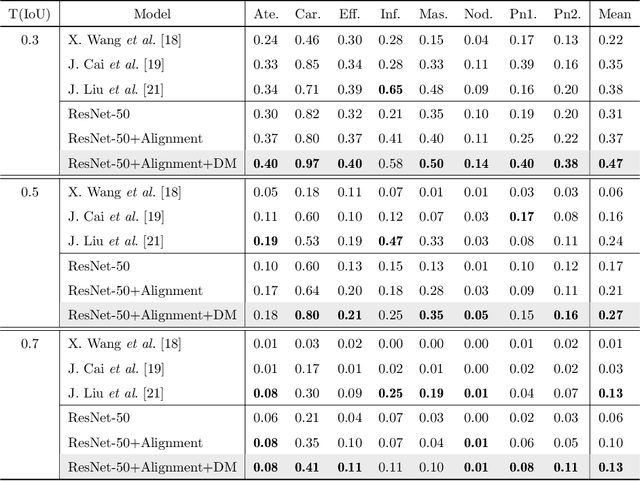
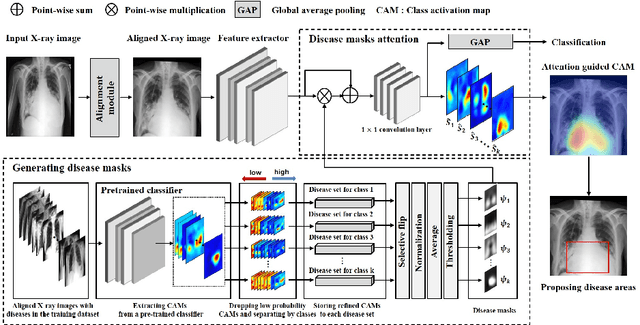
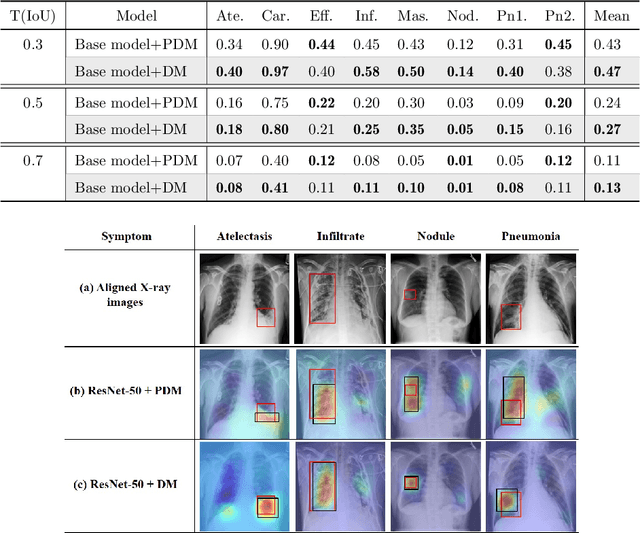
To enable a deep learning-based system to be used in the medical domain as a computer-aided diagnosis system, it is essential to not only classify diseases but also present the locations of the diseases. However, collecting instance-level annotations for various thoracic diseases is expensive. Therefore, weakly supervised localization methods have been proposed that use only image-level annotation. While the previous methods presented the disease location as the most discriminative part for classification, this causes a deep network to localize wrong areas for indistinguishable X-ray images. To solve this issue, we propose a spatial attention method using disease masks that describe the areas where diseases mainly occur. We then apply the spatial attention to find the precise disease area by highlighting the highest probability of disease occurrence. Meanwhile, the various sizes, rotations and noise in chest X-ray images make generating the disease masks challenging. To reduce the variation among images, we employ an alignment module to transform an input X-ray image into a generalized image. Through extensive experiments on the NIH-Chest X-ray dataset with eight kinds of diseases, we show that the proposed method results in superior localization performances compared to state-of-the-art methods.
Visual Question Answering based on Local-Scene-Aware Referring Expression Generation
Jan 22, 2021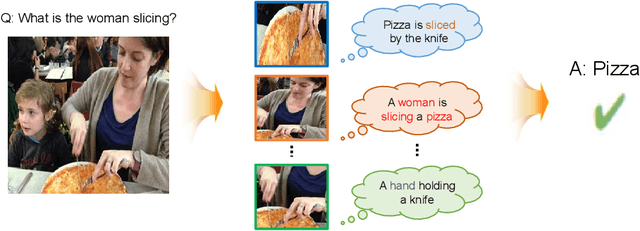
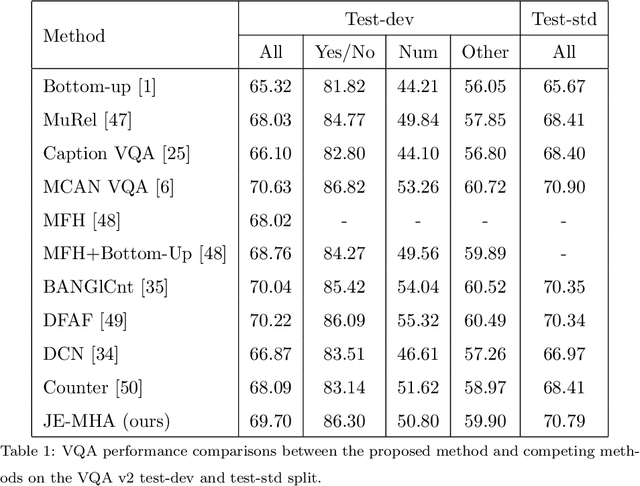
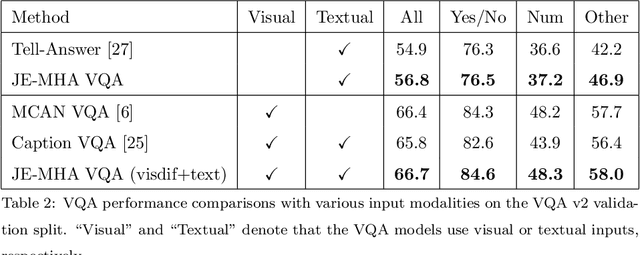
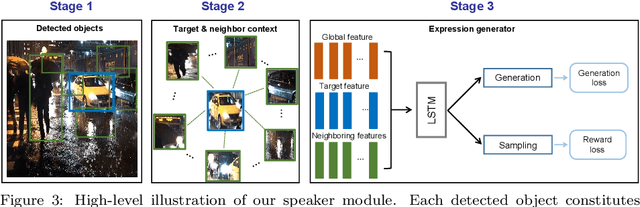
Visual question answering requires a deep understanding of both images and natural language. However, most methods mainly focus on visual concept; such as the relationships between various objects. The limited use of object categories combined with their relationships or simple question embedding is insufficient for representing complex scenes and explaining decisions. To address this limitation, we propose the use of text expressions generated for images, because such expressions have few structural constraints and can provide richer descriptions of images. The generated expressions can be incorporated with visual features and question embedding to obtain the question-relevant answer. A joint-embedding multi-head attention network is also proposed to model three different information modalities with co-attention. We quantitatively and qualitatively evaluated the proposed method on the VQA v2 dataset and compared it with state-of-the-art methods in terms of answer prediction. The quality of the generated expressions was also evaluated on the RefCOCO, RefCOCO+, and RefCOCOg datasets. Experimental results demonstrate the effectiveness of the proposed method and reveal that it outperformed all of the competing methods in terms of both quantitative and qualitative results.
Few-Shot Object Detection via Knowledge Transfer
Aug 28, 2020
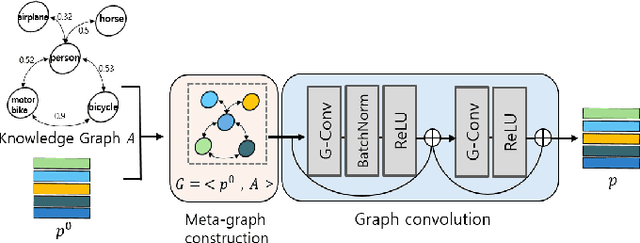


Conventional methods for object detection usually require substantial amounts of training data and annotated bounding boxes. If there are only a few training data and annotations, the object detectors easily overfit and fail to generalize. It exposes the practical weakness of the object detectors. On the other hand, human can easily master new reasoning rules with only a few demonstrations using previously learned knowledge. In this paper, we introduce a few-shot object detection via knowledge transfer, which aims to detect objects from a few training examples. Central to our method is prototypical knowledge transfer with an attached meta-learner. The meta-learner takes support set images that include the few examples of the novel categories and base categories, and predicts prototypes that represent each category as a vector. Then, the prototypes reweight each RoI (Region-of-Interest) feature vector from a query image to remodels R-CNN predictor heads. To facilitate the remodeling process, we predict the prototypes under a graph structure, which propagates information of the correlated base categories to the novel categories with explicit guidance of prior knowledge that represents correlations among categories. Extensive experiments on the PASCAL VOC dataset verifies the effectiveness of the proposed method.
Counterfactual Explanation Based on Gradual Construction for Deep Networks
Aug 05, 2020

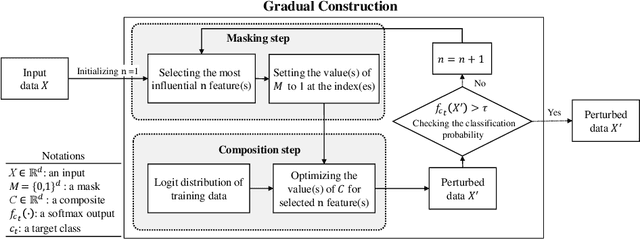

To understand the black-box characteristics of deep networks, counterfactual explanation that deduces not only the important features of an input space but also how those features should be modified to classify input as a target class has gained an increasing interest. The patterns that deep networks have learned from a training dataset can be grasped by observing the feature variation among various classes. However, current approaches perform the feature modification to increase the classification probability for the target class irrespective of the internal characteristics of deep networks. This often leads to unclear explanations that deviate from real-world data distributions. To address this problem, we propose a counterfactual explanation method that exploits the statistics learned from a training dataset. Especially, we gradually construct an explanation by iterating over masking and composition steps. The masking step aims to select an important feature from the input data to be classified as a target class. Meanwhile, the composition step aims to optimize the previously selected feature by ensuring that its output score is close to the logit space of the training data that are classified as the target class. Experimental results show that our method produces human-friendly interpretations on various classification datasets and verify that such interpretations can be achieved with fewer feature modification.
Self-Augmentation: Generalizing Deep Networks to Unseen Classes for Few-Shot Learning
Apr 01, 2020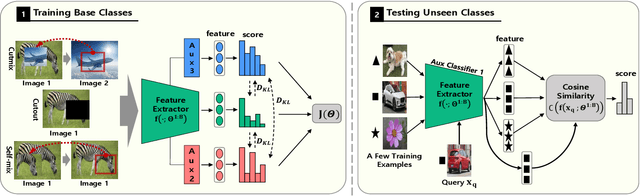
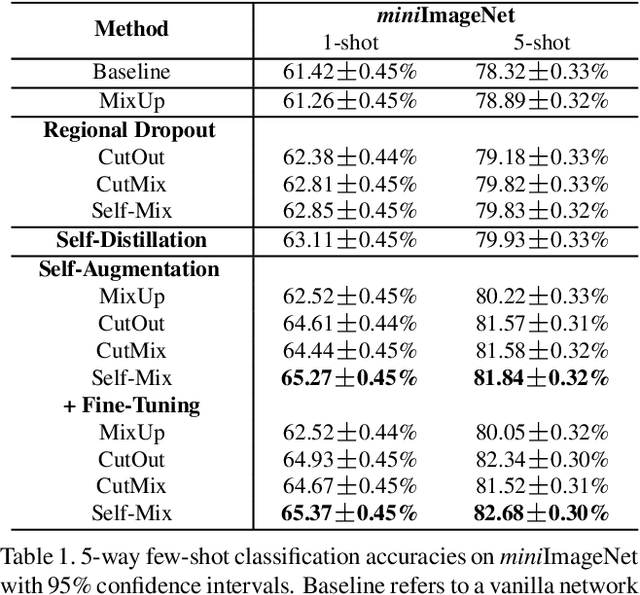
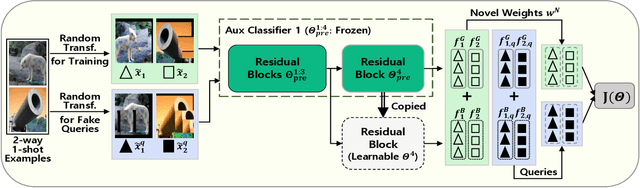
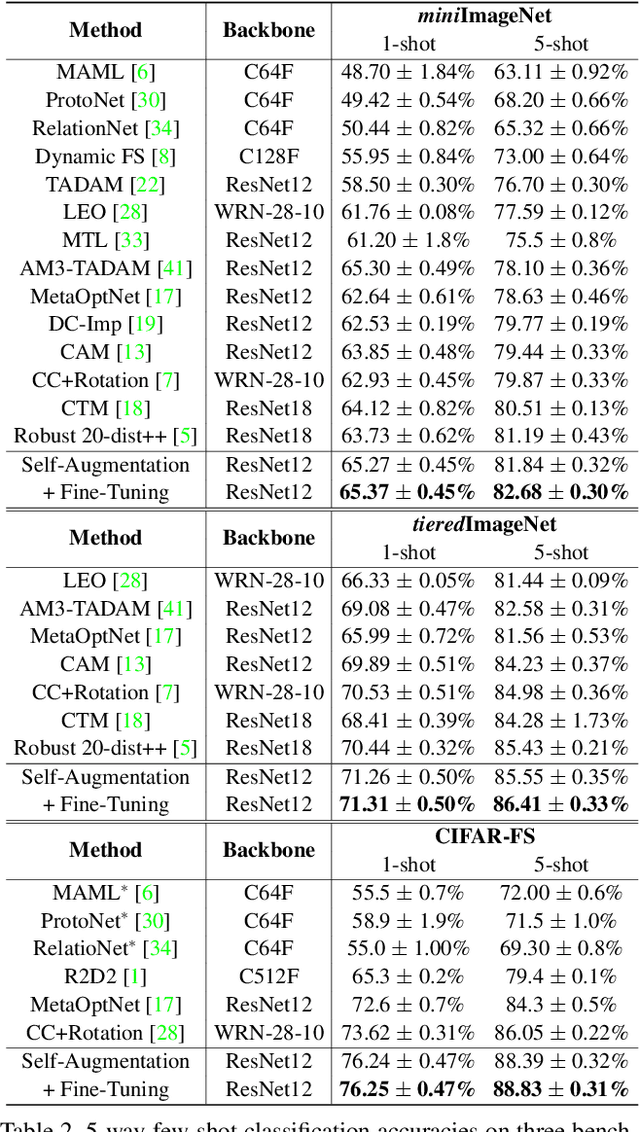
Few-shot learning aims to classify unseen classes with a few training examples. While recent works have shown that standard mini-batch training with a carefully designed training strategy can improve generalization ability for unseen classes, well-known problems in deep networks such as memorizing training statistics have been less explored for few-shot learning. To tackle this issue, we propose self-augmentation that consolidates regional dropout and self-distillation. Specifically, we exploit a data augmentation technique called regional dropout, in which a patch of an image is substituted into other values. Then, we employ a backbone network that has auxiliary branches with its own classifier to enforce knowledge sharing. Lastly, we present a fine-tuning method to further exploit a few training examples for unseen classes. Experimental results show that the proposed method outperforms the state-of-the-art methods for prevalent few-shot benchmarks and improves the generalization ability.
Few-Shot Learning with Geometric Constraints
Mar 20, 2020

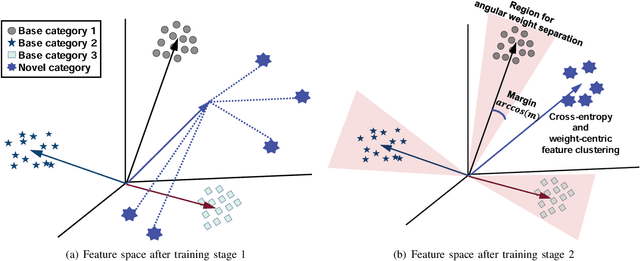

In this article, we consider the problem of few-shot learning for classification. We assume a network trained for base categories with a large number of training examples, and we aim to add novel categories to it that have only a few, e.g., one or five, training examples. This is a challenging scenario because: 1) high performance is required in both the base and novel categories; and 2) training the network for the new categories with a few training examples can contaminate the feature space trained well for the base categories. To address these challenges, we propose two geometric constraints to fine-tune the network with a few training examples. The first constraint enables features of the novel categories to cluster near the category weights, and the second maintains the weights of the novel categories far from the weights of the base categories. By applying the proposed constraints, we extract discriminative features for the novel categories while preserving the feature space learned for the base categories. Using public data sets for few-shot learning that are subsets of ImageNet, we demonstrate that the proposed method outperforms prevalent methods by a large margin.
Interpreting Undesirable Pixels for Image Classification on Black-Box Models
Sep 27, 2019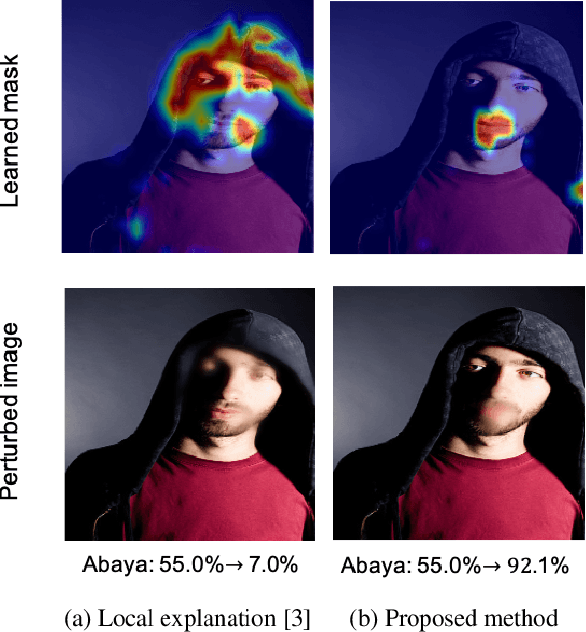

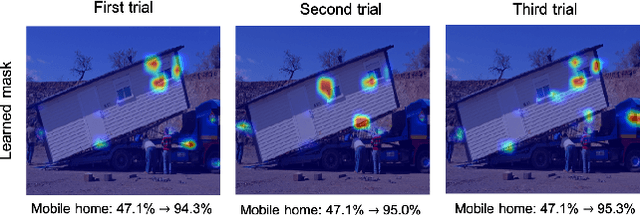
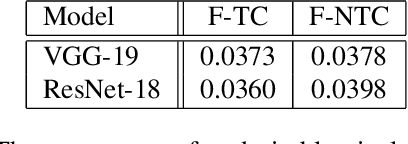
In an effort to interpret black-box models, researches for developing explanation methods have proceeded in recent years. Most studies have tried to identify input pixels that are crucial to the prediction of a classifier. While this approach is meaningful to analyse the characteristic of blackbox models, it is also important to investigate pixels that interfere with the prediction. To tackle this issue, in this paper, we propose an explanation method that visualizes undesirable regions to classify an image as a target class. To be specific, we divide the concept of undesirable regions into two terms: (1) factors for a target class, which hinder that black-box models identify intrinsic characteristics of a target class and (2) factors for non-target classes that are important regions for an image to be classified as other classes. We visualize such undesirable regions on heatmaps to qualitatively validate the proposed method. Furthermore, we present an evaluation metric to provide quantitative results on ImageNet.