 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Explanation Based on Gradual Construction for Deep Networks
Aug 05, 2020

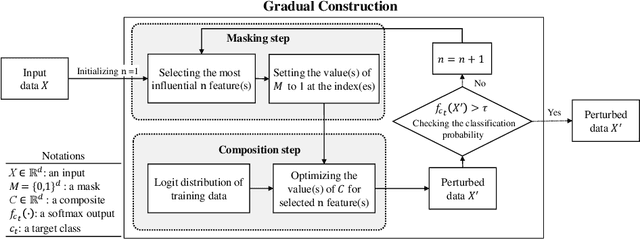

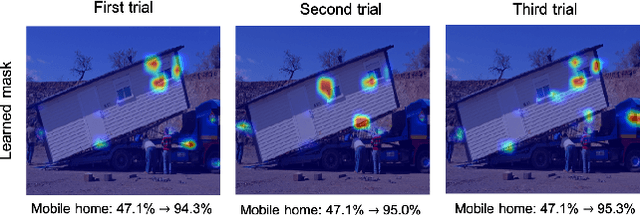
To understand the black-box characteristics of deep networks, counterfactual explanation that deduces not only the important features of an input space but also how those features should be modified to classify input as a target class has gained an increasing interest. The patterns that deep networks have learned from a training dataset can be grasped by observing the feature variation among various classes. However, current approaches perform the feature modification to increase the classification probability for the target class irrespective of the internal characteristics of deep networks. This often leads to unclear explanations that deviate from real-world data distributions. To address this problem, we propose a counterfactual explanation method that exploits the statistics learned from a training dataset. Especially, we gradually construct an explanation by iterating over masking and composition steps. The masking step aims to select an important feature from the input data to be classified as a target class. Meanwhile, the composition step aims to optimize the previously selected feature by ensuring that its output score is close to the logit space of the training data that are classified as the target class. Experimental results show that our method produces human-friendly interpretations on various classification datasets and verify that such interpretations can be achieved with fewer feature modification.
Interpreting Undesirable Pixels for Image Classification on Black-Box Models
Sep 27, 2019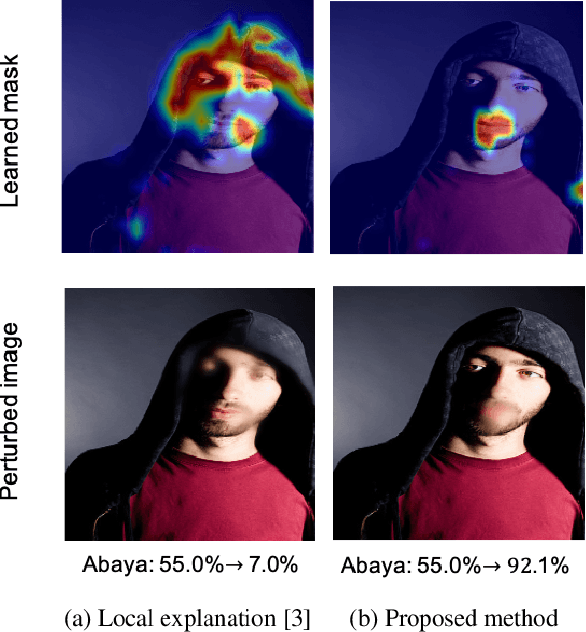

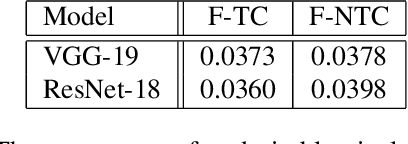
In an effort to interpret black-box models, researches for developing explanation methods have proceeded in recent years. Most studies have tried to identify input pixels that are crucial to the prediction of a classifier. While this approach is meaningful to analyse the characteristic of blackbox models, it is also important to investigate pixels that interfere with the prediction. To tackle this issue, in this paper, we propose an explanation method that visualizes undesirable regions to classify an image as a target class. To be specific, we divide the concept of undesirable regions into two terms: (1) factors for a target class, which hinder that black-box models identify intrinsic characteristics of a target class and (2) factors for non-target classes that are important regions for an image to be classified as other classes. We visualize such undesirable regions on heatmaps to qualitatively validate the proposed method. Furthermore, we present an evaluation metric to provide quantitative results on ImageNet.