 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Answering based on Local-Scene-Aware Referring Expression Generation
Jan 22, 2021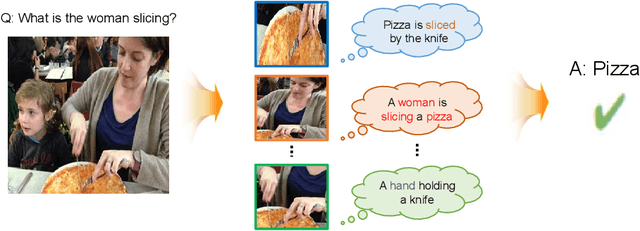
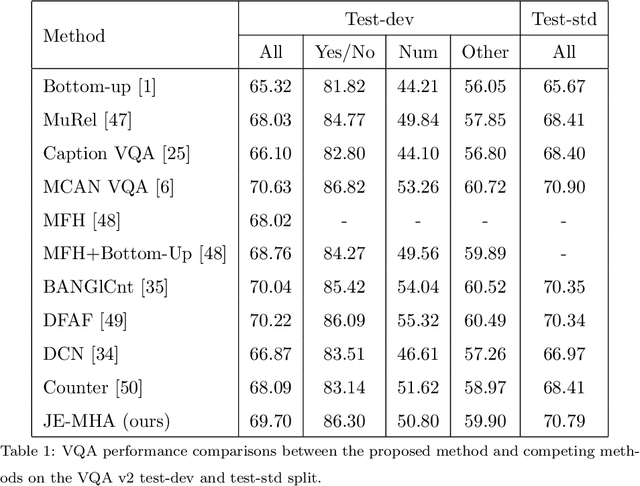
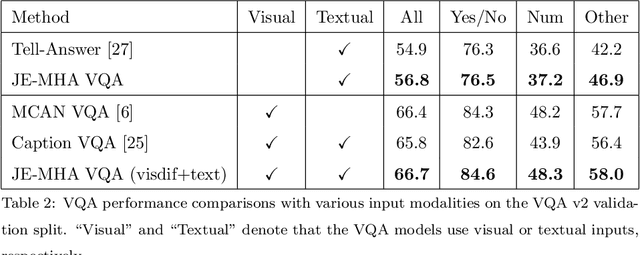
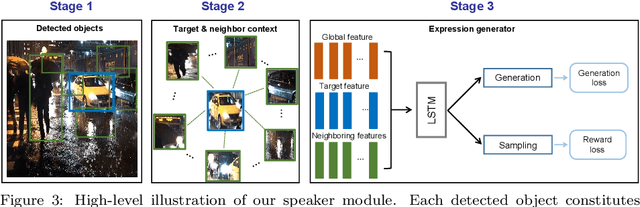
Visual question answering requires a deep understanding of both images and natural language. However, most methods mainly focus on visual concept; such as the relationships between various objects. The limited use of object categories combined with their relationships or simple question embedding is insufficient for representing complex scenes and explaining decisions. To address this limitation, we propose the use of text expressions generated for images, because such expressions have few structural constraints and can provide richer descriptions of images. The generated expressions can be incorporated with visual features and question embedding to obtain the question-relevant answer. A joint-embedding multi-head attention network is also proposed to model three different information modalities with co-attention. We quantitatively and qualitatively evaluated the proposed method on the VQA v2 dataset and compared it with state-of-the-art methods in terms of answer prediction. The quality of the generated expressions was also evaluated on the RefCOCO, RefCOCO+, and RefCOCOg datasets. Experimental results demonstrate the effectiveness of the proposed method and reveal that it outperformed all of the competing methods in terms of both quantitative and qualitative results.