 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Augmentation: Generalizing Deep Networks to Unseen Classes for Few-Shot Learning
Paper and Code
Apr 01, 2020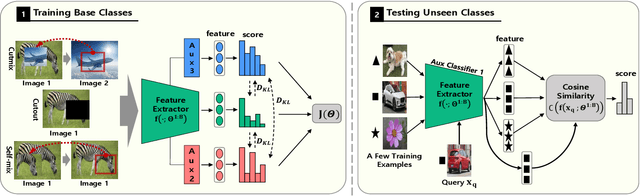
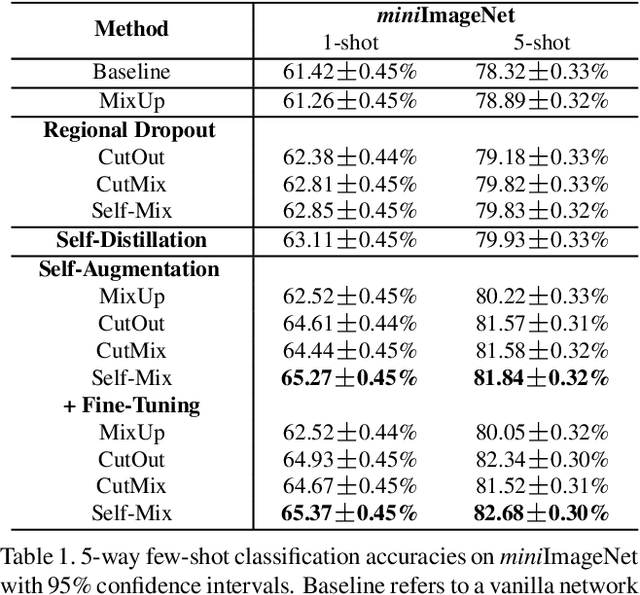
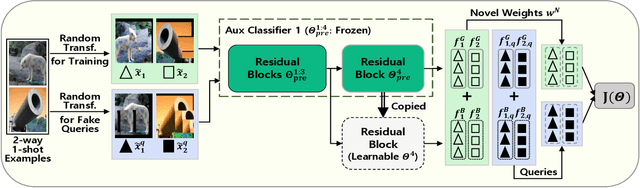
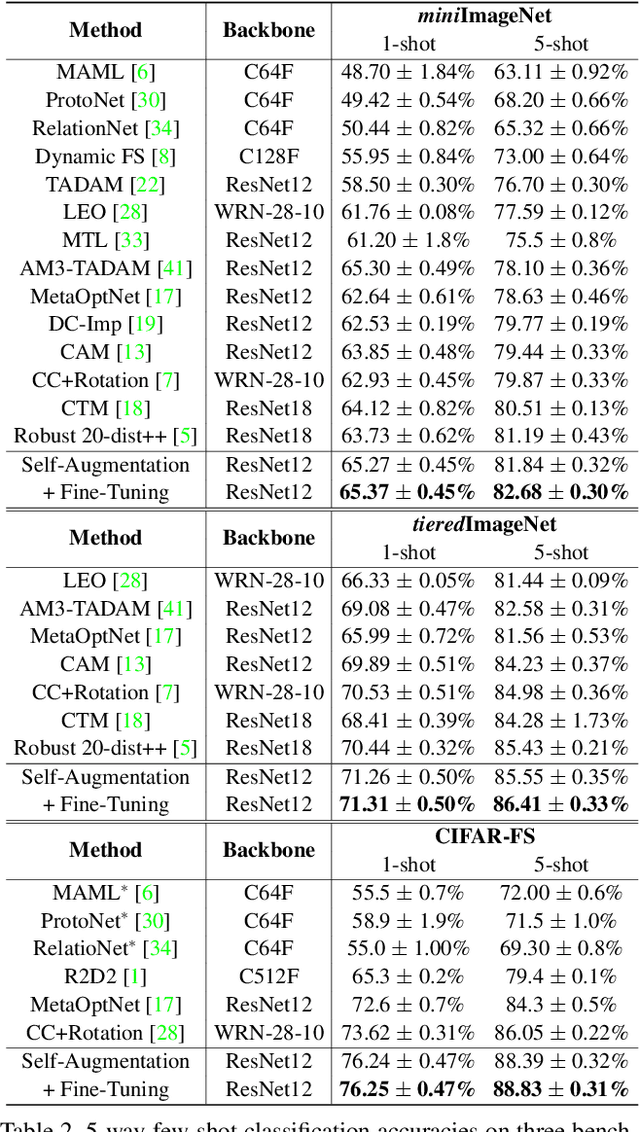
Few-shot learning aims to classify unseen classes with a few training examples. While recent works have shown that standard mini-batch training with a carefully designed training strategy can improve generalization ability for unseen classes, well-known problems in deep networks such as memorizing training statistics have been less explored for few-shot learning. To tackle this issue, we propose self-augmentation that consolidates regional dropout and self-distillation. Specifically, we exploit a data augmentation technique called regional dropout, in which a patch of an image is substituted into other values. Then, we employ a backbone network that has auxiliary branches with its own classifier to enforce knowledge sharing. Lastly, we present a fine-tuning method to further exploit a few training examples for unseen classes. Experimental results show that the proposed method outperforms the state-of-the-art methods for prevalent few-shot benchmarks and improves the generalization ability.