 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADEL: Uncertainty-aware Fake Audio Detection with Evidential Deep Learning
Apr 22, 2025Recently, fake audio detection has gained significant attention, as advancements in speech synthesis and voice conversion have increased the vulnerability of automatic speaker verification (ASV) systems to spoofing attacks. A key challenge in this task is generalizing models to detect unseen, out-of-distribution (OOD) attacks. Although existing approaches have shown promising results, they inherently suffer from overconfidence issues due to the usage of softmax for classification, which can produce unreliable predictions when encountering unpredictable spoofing attempts. To deal with this limitation, we propose a novel framework called fake audio detection with evidential learning (FADEL). By modeling class probabilities with a Dirichlet distribution, FADEL incorporates model uncertainty into its predictions, thereby leading to more robust performance in OOD scenarios. Experimental results on the ASVspoof2019 Logical Access (LA) and ASVspoof2021 LA datasets indicate that the proposed method significantly improves the performance of baseline models. Furthermore, we demonstrate the validity of uncertainty estimation by analyzing a strong correlation between average uncertainty and equal error rate (EER) across different spoofing algorithms.
Towards Maximum Likelihood Training for Transducer-based Streaming Speech Recognition
Nov 26, 2024

Transducer neural networks have emerged as the mainstream approach for streaming automatic speech recognition (ASR), offering state-of-the-art performance in balancing accuracy and latency. In the conventional framework, streaming transducer models are trained to maximize the likelihood function based on non-streaming recursion rules. However, this approach leads to a mismatch between training and inference, resulting in the issue of deformed likelihood and consequently suboptimal ASR accuracy. We introduce a mathematical quantification of the gap between the actual likelihood and the deformed likelihood, namely forward variable causal compensation (FoCC). We also present its estimator, FoCCE, as a solution to estimate the exact likelihood. Through experiments on the LibriSpeech dataset, we show that FoCCE training improves the accuracy of the streaming transducers.
SegINR: Segment-wise Implicit Neural Representation for Sequence Alignment in Neural Text-to-Speech
Oct 07, 2024We present SegINR, a novel approach to neural Text-to-Speech (TTS) that addresses sequence alignment without relying on an auxiliary duration predictor and complex autoregressive (AR) or non-autoregressive (NAR) frame-level sequence modeling. SegINR simplifies the process by converting text sequences directly into frame-level features. It leverages an optimal text encoder to extract embeddings, transforming each into a segment of frame-level features using a conditional implicit neural representation (INR). This method, named segment-wise INR (SegINR), models temporal dynamics within each segment and autonomously defines segment boundaries, reducing computational costs. We integrate SegINR into a two-stage TTS framework, using it for semantic token prediction. Our experiments in zero-shot adaptive TTS scenarios demonstrate that SegINR outperforms conventional methods in speech quality with computational efficiency.
High Fidelity Text-to-Speech Via Discrete Tokens Using Token Transducer and Group Masked Language Model
Jun 25, 2024
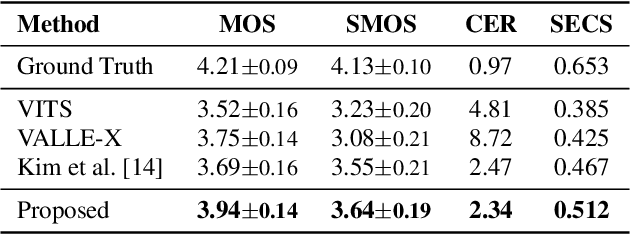
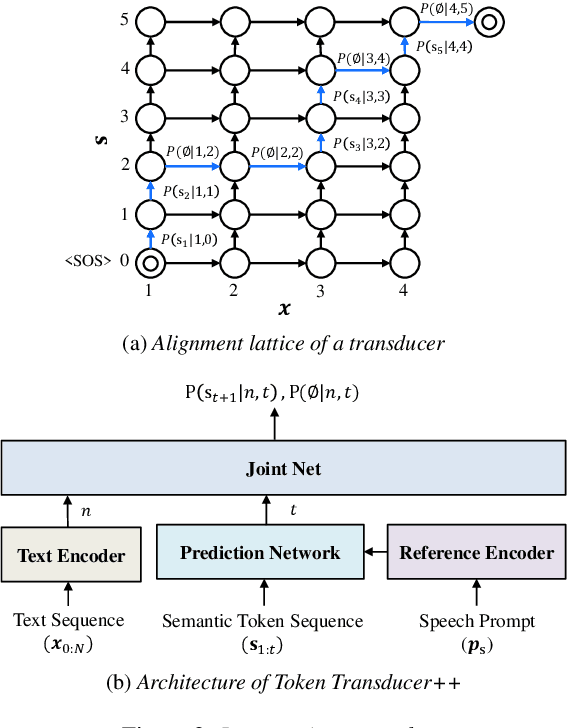

We propose a novel two-stage text-to-speech (TTS) framework with two types of discrete tokens, i.e., semantic and acoustic tokens, for high-fidelity speech synthesis. It features two core components: the Interpreting module, which processes text and a speech prompt into semantic tokens focusing on linguistic contents and alignment, and the Speaking module, which captures the timbre of the target voice to generate acoustic tokens from semantic tokens, enriching speech reconstruction. The Interpreting stage employs a transducer for its robustness in aligning text to speech. In contrast, the Speaking stage utilizes a Conformer-based architecture integrated with a Grouped Masked Language Model (G-MLM) to boost computational efficiency. Our experiments verify that this innovative structure surpasses the conventional models in the zero-shot scenario in terms of speech quality and speaker similarity.
MakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
Jun 10, 2024In this paper, we propose MakeSinger, a semi-supervised training method for singing voice synthesis (SVS) via classifier-free diffusion guidance. The challenge in SVS lies in the costly process of gathering aligned sets of text, pitch, and audio data. MakeSinger enables the training of the diffusion-based SVS model from any speech and singing voice data regardless of its labeling, thereby enhancing the quality of generated voices with large amount of unlabeled data. At inference, our novel dual guiding mechanism gives text and pitch guidance on the reverse diffusion step by estimating the score of masked input. Experimental results show that the model trained in a semi-supervised manner outperforms other baselines trained only on the labeled data in terms of pronunciation, pitch accuracy and overall quality. Furthermore, we demonstrate that by adding Text-to-Speech (TTS) data in training, the model can synthesize the singing voices of TTS speakers even without their singing voices.
HILCodec: High Fidelity and Lightweight Neural Audio Codec
May 08, 2024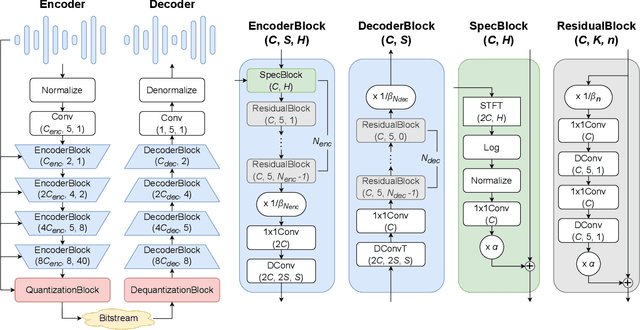
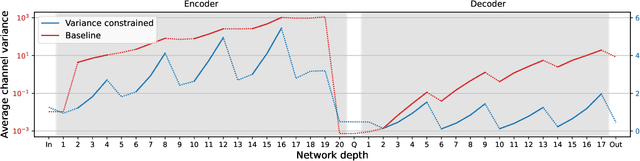
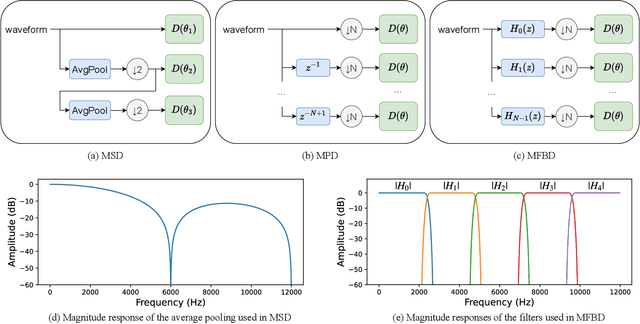
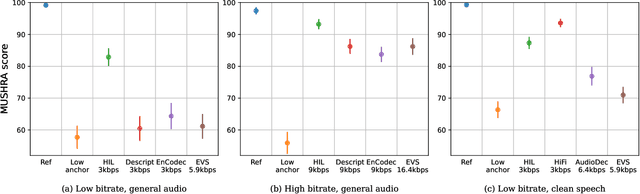
The recent advancement of end-to-end neural audio codecs enables compressing audio at very low bitrates while reconstructing the output audio with high fidelity. Nonetheless, such improvements often come at the cost of increased model complexity. In this paper, we identify and address the problems of existing neural audio codecs. We show that the performance of Wave-U-Net does not increase consistently as the network depth increases. We analyze the root cause of such a phenomenon and suggest a variance-constrained design. Also, we reveal various distortions in previous waveform domain discriminators and propose a novel distortion-free discriminator. The resulting model, \textit{HILCodec}, is a real-time streaming audio codec that demonstrates state-of-the-art quality across various bitrates and audio types.
Utilizing Neural Transducers for Two-Stage Text-to-Speech via Semantic Token Prediction
Jan 03, 2024We propose a novel text-to-speech (TTS) framework centered around a neural transducer. Our approach divides the whole TTS pipeline into semantic-level sequence-to-sequence (seq2seq) modeling and fine-grained acoustic modeling stages, utilizing discrete semantic tokens obtained from wav2vec2.0 embeddings. For a robust and efficient alignment modeling, we employ a neural transducer named token transducer for the semantic token prediction, benefiting from its hard monotonic alignment constraints. Subsequently, a non-autoregressive (NAR) speech generator efficiently synthesizes waveforms from these semantic tokens. Additionally, a reference speech controls temporal dynamics and acoustic conditions at each stage. This decoupled framework reduces the training complexity of TTS while allowing each stage to focus on semantic and acoustic modeling. Our experimental results on zero-shot adaptive TTS demonstrate that our model surpasses the baseline in terms of speech quality and speaker similarity, both objectively and subjectively. We also delve into the inference speed and prosody control capabilities of our approach, highlighting the potential of neural transducers in TTS frameworks.
Efficient Parallel Audio Generation using Group Masked Language Modeling
Jan 02, 2024We present a fast and high-quality codec language model for parallel audio generation. While SoundStorm, a state-of-the-art parallel audio generation model, accelerates inference speed compared to autoregressive models, it still suffers from slow inference due to iterative sampling. To resolve this problem, we propose Group-Masked Language Modeling~(G-MLM) and Group Iterative Parallel Decoding~(G-IPD) for efficient parallel audio generation. Both the training and sampling schemes enable the model to synthesize high-quality audio with a small number of iterations by effectively modeling the group-wise conditional dependencies. In addition, our model employs a cross-attention-based architecture to capture the speaker style of the prompt voice and improves computational efficiency. Experimental results demonstrate that our proposed model outperforms the baselines in prompt-based audio generation.
EEND-DEMUX: End-to-End Neural Speaker Diarization via Demultiplexed Speaker Embeddings
Dec 11, 2023In recent years, there have been studies to further improve the end-to-end neural speaker diarization (EEND) systems. This letter proposes the EEND-DEMUX model, a novel framework utilizing demultiplexed speaker embeddings. In this work, we focus on disentangling speaker-relevant information in the latent space and then transform each separated latent variable into its corresponding speech activity. EEND-DEMUX can directly obtain separated speaker embeddings through the demultiplexing operation in the inference phase without an external speaker diarization system, an embedding extractor, or a heuristic decoding technique. Furthermore, we employ a multi-head cross-attention mechanism to capture the correlation between mixture and separated speaker embeddings effectively. We formulate three loss functions based on matching, orthogonality, and sparsity constraints to learn robust demultiplexed speaker embeddings. The experimental results on the LibriMix dataset show consistently improved performance in both a fixed and flexible number of speakers scenarios.
Transduce and Speak: Neural Transducer for Text-to-Speech with Semantic Token Prediction
Nov 08, 2023We introduce a text-to-speech(TTS) framework based on a neural transducer. We use discretized semantic tokens acquired from wav2vec2.0 embeddings, which makes it easy to adopt a neural transducer for the TTS framework enjoying its monotonic alignment constraints. The proposed model first generates aligned semantic tokens using the neural transducer, then synthesizes a speech sample from the semantic tokens using a non-autoregressive(NAR) speech generator. This decoupled framework alleviates the training complexity of TTS and allows each stage to focus on 1) linguistic and alignment modeling and 2) fine-grained acoustic modeling, respectively. Experimental results on the zero-shot adaptive TTS show that the proposed model exceeds the baselines in speech quality and speaker similarity via objective and subjective measures. We also investigate the inference speed and prosody controllability of our proposed model, showing the potential of the neural transducer for TTS frameworks.