 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHILCodec: High Fidelity and Lightweight Neural Audio Codec
May 08, 2024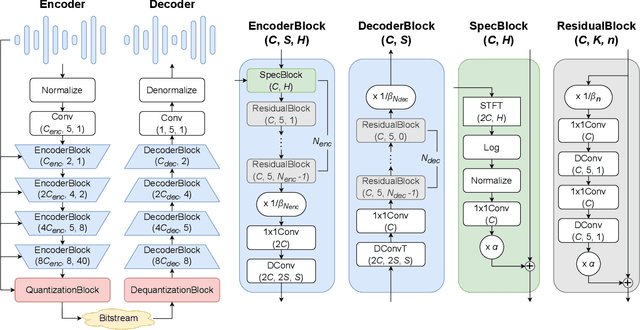
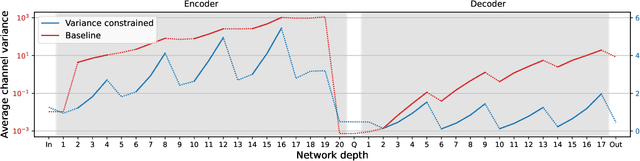
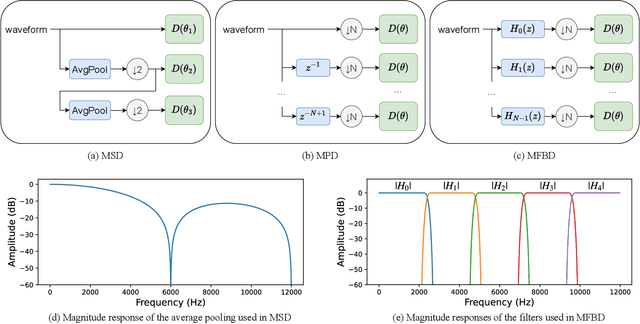
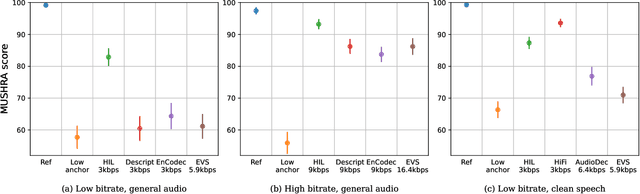
The recent advancement of end-to-end neural audio codecs enables compressing audio at very low bitrates while reconstructing the output audio with high fidelity. Nonetheless, such improvements often come at the cost of increased model complexity. In this paper, we identify and address the problems of existing neural audio codecs. We show that the performance of Wave-U-Net does not increase consistently as the network depth increases. We analyze the root cause of such a phenomenon and suggest a variance-constrained design. Also, we reveal various distortions in previous waveform domain discriminators and propose a novel distortion-free discriminator. The resulting model, \textit{HILCodec}, is a real-time streaming audio codec that demonstrates state-of-the-art quality across various bitrates and audio types.
EM-Network: Oracle Guided Self-distillation for Sequence Learning
Jun 14, 2023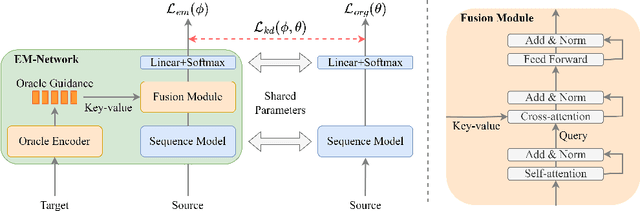
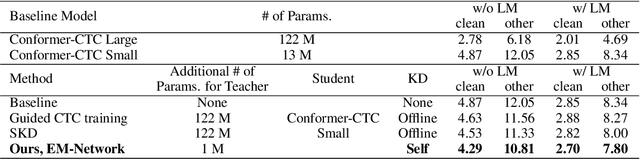
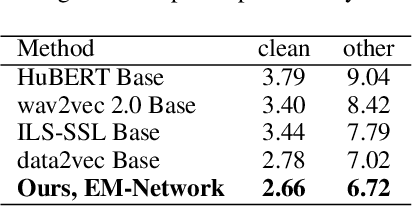
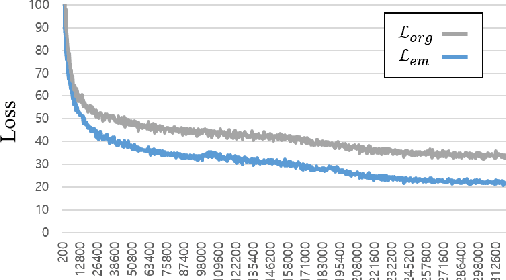
We introduce EM-Network, a novel self-distillation approach that effectively leverages target information for supervised sequence-to-sequence (seq2seq) learning. In contrast to conventional methods, it is trained with oracle guidance, which is derived from the target sequence. Since the oracle guidance compactly represents the target-side context that can assist the sequence model in solving the task, the EM-Network achieves a better prediction compared to using only the source input. To allow the sequence model to inherit the promising capability of the EM-Network, we propose a new self-distillation strategy, where the original sequence model can benefit from the knowledge of the EM-Network in a one-stage manner. We conduct comprehensive experiments on two types of seq2seq models: connectionist temporal classification (CTC) for speech recognition and attention-based encoder-decoder (AED) for machine translation. Experimental results demonstrate that the EM-Network significantly advances the current state-of-the-art approaches, improving over the best prior work on speech recognition and establishing state-of-the-art performance on WMT'14 and IWSLT'14.
Inter-KD: Intermediate Knowledge Distillation for CTC-Based Automatic Speech Recognition
Nov 28, 2022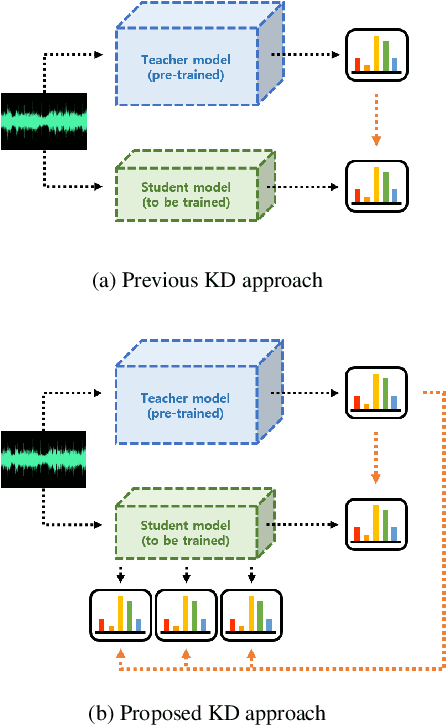
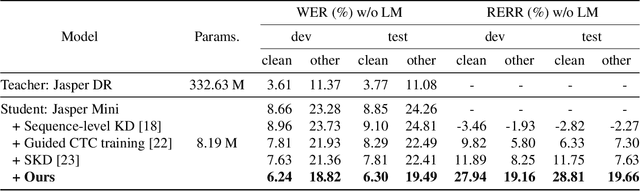
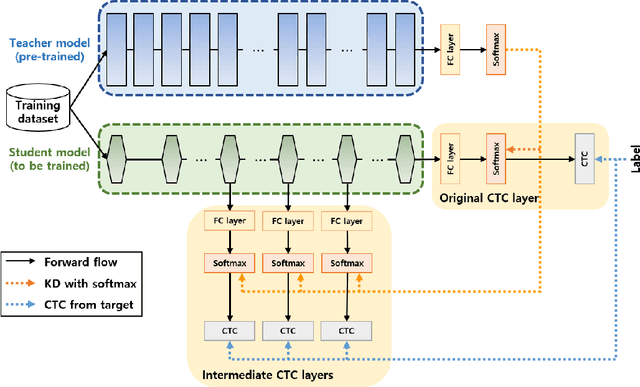

Recently, the advance in deep learning has brought a considerable improvement in the end-to-end speech recognition field, simplifying the traditional pipeline while producing promising results. Among the end-to-end models, the connectionist temporal classification (CTC)-based model has attracted research interest due to its non-autoregressive nature. However, such CTC models require a heavy computational cost to achieve outstanding performance. To mitigate the computational burden, we propose a simple yet effective knowledge distillation (KD) for the CTC framework, namely Inter-KD, that additionally transfers the teacher's knowledge to the intermediate CTC layers of the student network. From the experimental results on the LibriSpeech, we verify that the Inter-KD shows better achievements compared to the conventional KD methods. Without using any language model (LM) and data augmentation, Inter-KD improves the word error rate (WER) performance from 8.85 % to 6.30 % on the test-clean.
Transfer Learning Framework for Low-Resource Text-to-Speech using a Large-Scale Unlabeled Speech Corpus
Mar 29, 2022
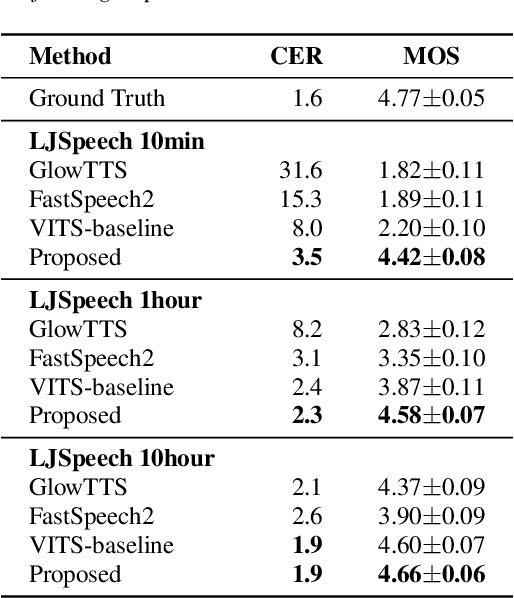
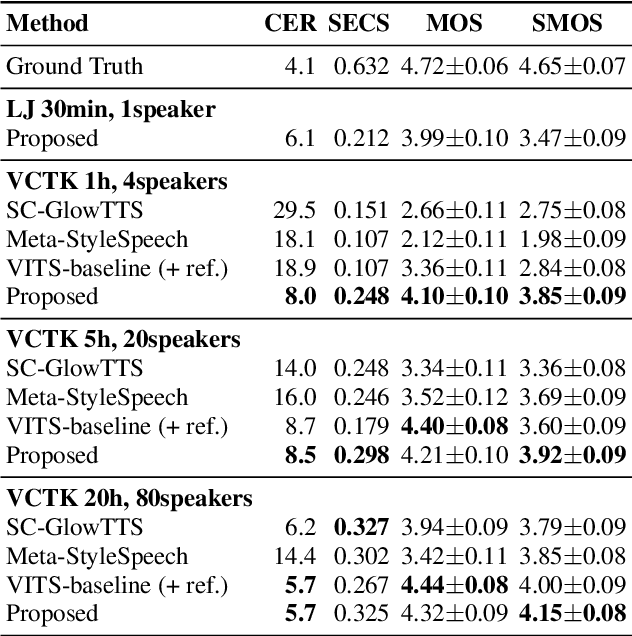
Training a text-to-speech (TTS) model requires a large scale text labeled speech corpus, which is troublesome to collect. In this paper, we propose a transfer learning framework for TTS that utilizes a large amount of unlabeled speech dataset for pre-training. By leveraging wav2vec2.0 representation, unlabeled speech can highly improve performance, especially in the lack of labeled speech. We also extend the proposed method to zero-shot multi-speaker TTS (ZS-TTS). The experimental results verify the effectiveness of the proposed method in terms of naturalness, intelligibility, and speaker generalization. We highlight that the single speaker TTS model fine-tuned on the only 10 minutes of labeled dataset outperforms the other baselines, and the ZS-TTS model fine-tuned on the only 30 minutes of single speaker dataset can generate the voice of the arbitrary speaker, by pre-training on unlabeled multi-speaker speech corpus.
Oracle Teacher: Towards Better Knowledge Distillation
Nov 05, 2021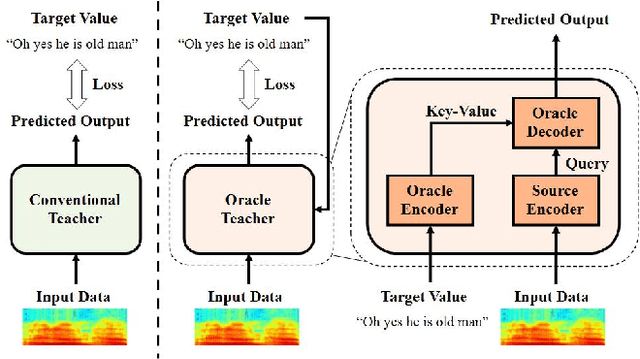
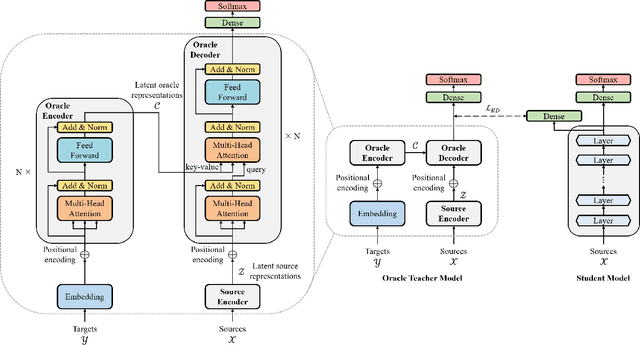
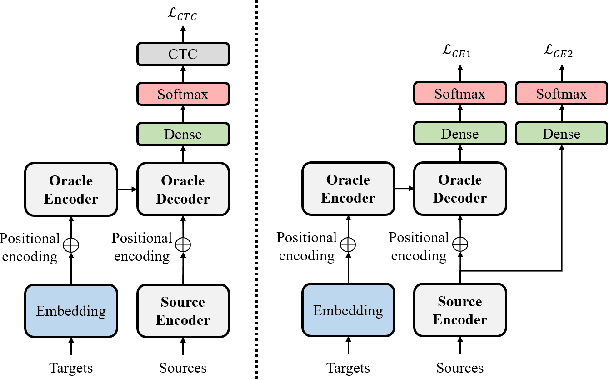

Knowledge distillation (KD), best known as an effective method for model compression, aims at transferring the knowledge of a bigger network (teacher) to a much smaller network (student). Conventional KD methods usually employ the teacher model trained in a supervised manner, where output labels are treated only as targets. Extending this supervised scheme further, we introduce a new type of teacher model for KD, namely Oracle Teacher, that utilizes the embeddings of both the source inputs and the output labels to extract a more accurate knowledge to be transferred to the student. The proposed model follows the encoder-decoder attention structure of the Transformer network, which allows the model to attend to related information from the output labels. Extensive experiments are conducted on three different sequence learning tasks: speech recognition, scene text recognition, and machine translation. From the experimental results, we empirically show that the proposed model improves the students across these tasks while achieving a considerable speed-up in the teacher model's training time.