 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Decoding: Rapid Pass and Selective Detailed Correction for Sequence Models
Aug 27, 2025Recently, Transformer-based encoder-decoder models have demonstrated strong performance in multilingual speech recognition. However, the decoder's autoregressive nature and large size introduce significant bottlenecks during inference. Additionally, although rare, repetition can occur and negatively affect recognition accuracy. To tackle these challenges, we propose a novel Hybrid Decoding approach that both accelerates inference and alleviates the issue of repetition. Our method extends the transformer encoder-decoder architecture by attaching a lightweight, fast decoder to the pretrained encoder. During inference, the fast decoder rapidly generates an output, which is then verified and, if necessary, selectively corrected by the Transformer decoder. This results in faster decoding and improved robustness against repetitive errors. Experiments on the LibriSpeech and GigaSpeech test sets indicate that, with fine-tuning limited to the added decoder, our method achieves word error rates comparable to or better than the baseline, while more than doubling the inference speed.
Joint unsupervised and supervised learning for context-aware language identification
Apr 14, 2023Language identification (LID) recognizes the language of a spoken utterance automatically. According to recent studies, LID models trained with an automatic speech recognition (ASR) task perform better than those trained with a LID task only. However, we need additional text labels to train the model to recognize speech, and acquiring the text labels is a cost high. In order to overcome this problem, we propose context-aware language identification using a combination of unsupervised and supervised learning without any text labels. The proposed method learns the context of speech through masked language modeling (MLM) loss and simultaneously trains to determine the language of the utterance with supervised learning loss. The proposed joint learning was found to reduce the error rate by 15.6% compared to the same structure model trained by supervised-only learning on a subset of the VoxLingua107 dataset consisting of sub-three-second utterances in 11 languages.
Oracle Teacher: Towards Better Knowledge Distillation
Nov 05, 2021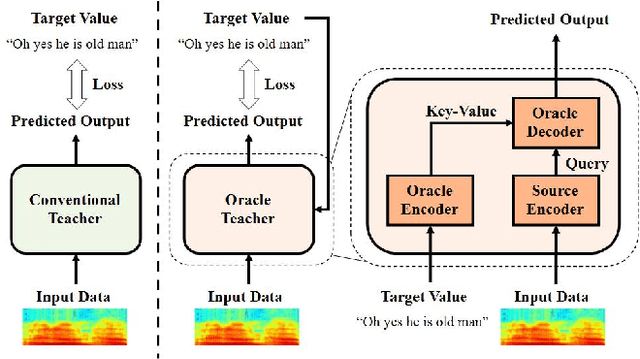
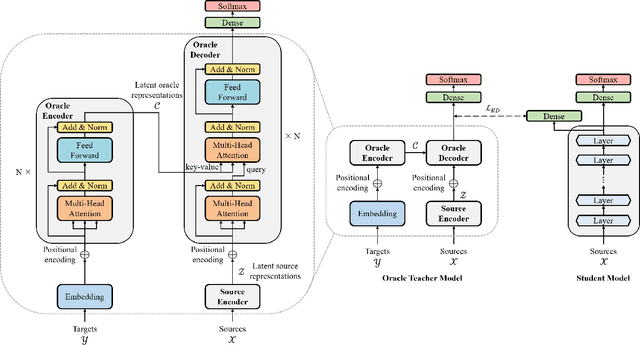
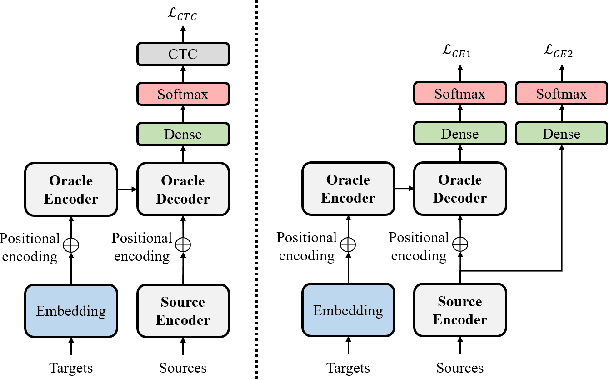

Knowledge distillation (KD), best known as an effective method for model compression, aims at transferring the knowledge of a bigger network (teacher) to a much smaller network (student). Conventional KD methods usually employ the teacher model trained in a supervised manner, where output labels are treated only as targets. Extending this supervised scheme further, we introduce a new type of teacher model for KD, namely Oracle Teacher, that utilizes the embeddings of both the source inputs and the output labels to extract a more accurate knowledge to be transferred to the student. The proposed model follows the encoder-decoder attention structure of the Transformer network, which allows the model to attend to related information from the output labels. Extensive experiments are conducted on three different sequence learning tasks: speech recognition, scene text recognition, and machine translation. From the experimental results, we empirically show that the proposed model improves the students across these tasks while achieving a considerable speed-up in the teacher model's training time.