 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Decoding: Rapid Pass and Selective Detailed Correction for Sequence Models
Aug 27, 2025Recently, Transformer-based encoder-decoder models have demonstrated strong performance in multilingual speech recognition. However, the decoder's autoregressive nature and large size introduce significant bottlenecks during inference. Additionally, although rare, repetition can occur and negatively affect recognition accuracy. To tackle these challenges, we propose a novel Hybrid Decoding approach that both accelerates inference and alleviates the issue of repetition. Our method extends the transformer encoder-decoder architecture by attaching a lightweight, fast decoder to the pretrained encoder. During inference, the fast decoder rapidly generates an output, which is then verified and, if necessary, selectively corrected by the Transformer decoder. This results in faster decoding and improved robustness against repetitive errors. Experiments on the LibriSpeech and GigaSpeech test sets indicate that, with fine-tuning limited to the added decoder, our method achieves word error rates comparable to or better than the baseline, while more than doubling the inference speed.
CrossSpeech++: Cross-lingual Speech Synthesis with Decoupled Language and Speaker Generation
Dec 28, 2024



The goal of this work is to generate natural speech in multiple languages while maintaining the same speaker identity, a task known as cross-lingual speech synthesis. A key challenge of cross-lingual speech synthesis is the language-speaker entanglement problem, which causes the quality of cross-lingual systems to lag behind that of intra-lingual systems. In this paper, we propose CrossSpeech++, which effectively disentangles language and speaker information and significantly improves the quality of cross-lingual speech synthesis. To this end, we break the complex speech generation pipeline into two simple components: language-dependent and speaker-dependent generators. The language-dependent generator produces linguistic variations that are not biased by specific speaker attributes. The speaker-dependent generator models acoustic variations that characterize speaker identity. By handling each type of information in separate modules, our method can effectively disentangle language and speaker representation. We conduct extensive experiments using various metrics, and demonstrate that CrossSpeech++ achieves significant improvements in cross-lingual speech synthesis, outperforming existing methods by a large margin.
Bridging the Gap between Audio and Text using Parallel-attention for User-defined Keyword Spotting
Aug 07, 2024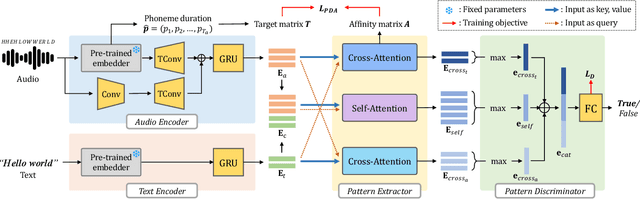
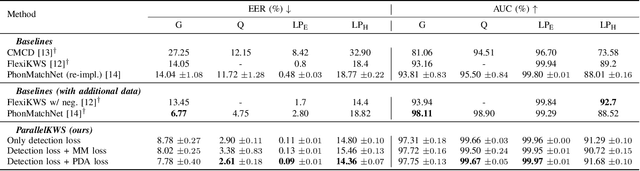

This paper proposes a novel user-defined keyword spotting framework that accurately detects audio keywords based on text enrollment. Since audio data possesses additional acoustic information compared to text, there are discrepancies between these two modalities. To address this challenge, we present ParallelKWS, which utilises self- and cross-attention in a parallel architecture to effectively capture information both within and across the two modalities. We further propose a phoneme duration-based alignment loss that enforces the sequential correspondence between audio and text features. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art performance on several benchmark datasets in both seen and unseen domains, without incorporating extra data beyond the dataset used in previous studies.
Faces that Speak: Jointly Synthesising Talking Face and Speech from Text
May 16, 2024



The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.
Boosting Unknown-number Speaker Separation with Transformer Decoder-based Attractor
Jan 23, 2024We propose a novel speech separation model designed to separate mixtures with an unknown number of speakers. The proposed model stacks 1) a dual-path processing block that can model spectro-temporal patterns, 2) a transformer decoder-based attractor (TDA) calculation module that can deal with an unknown number of speakers, and 3) triple-path processing blocks that can model inter-speaker relations. Given a fixed, small set of learned speaker queries and the mixture embedding produced by the dual-path blocks, TDA infers the relations of these queries and generates an attractor vector for each speaker. The estimated attractors are then combined with the mixture embedding by feature-wise linear modulation conditioning, creating a speaker dimension. The mixture embedding, conditioned with speaker information produced by TDA, is fed to the final triple-path blocks, which augment the dual-path blocks with an additional pathway dedicated to inter-speaker processing. The proposed approach outperforms the previous best reported in the literature, achieving 24.0 and 23.7 dB SI-SDR improvement (SI-SDRi) on WSJ0-2 and 3mix respectively, with a single model trained to separate 2- and 3-speaker mixtures. The proposed model also exhibits strong performance and generalizability at counting sources and separating mixtures with up to 5 speakers.
Neural Speech Enhancement with Very Low Algorithmic Latency and Complexity via Integrated Full- and Sub-Band Modeling
Apr 18, 2023



We propose FSB-LSTM, a novel long short-term memory (LSTM) based architecture that integrates full- and sub-band (FSB) modeling, for single- and multi-channel speech enhancement in the short-time Fourier transform (STFT) domain. The model maintains an information highway to flow an over-complete input representation through multiple FSB-LSTM modules. Each FSB-LSTM module consists of a full-band block to model spectro-temporal patterns at all frequencies and a sub-band block to model patterns within each sub-band, where each of the two blocks takes a down-sampled representation as input and returns an up-sampled discriminative representation to be added to the block input via a residual connection. The model is designed to have a low algorithmic complexity, a small run-time buffer and a very low algorithmic latency, at the same time producing a strong enhancement performance on a noisy-reverberant speech enhancement task even if the hop size is as low as $2$ ms.
Joint unsupervised and supervised learning for context-aware language identification
Apr 14, 2023Language identification (LID) recognizes the language of a spoken utterance automatically. According to recent studies, LID models trained with an automatic speech recognition (ASR) task perform better than those trained with a LID task only. However, we need additional text labels to train the model to recognize speech, and acquiring the text labels is a cost high. In order to overcome this problem, we propose context-aware language identification using a combination of unsupervised and supervised learning without any text labels. The proposed method learns the context of speech through masked language modeling (MLM) loss and simultaneously trains to determine the language of the utterance with supervised learning loss. The proposed joint learning was found to reduce the error rate by 15.6% compared to the same structure model trained by supervised-only learning on a subset of the VoxLingua107 dataset consisting of sub-three-second utterances in 11 languages.
That's What I Said: Fully-Controllable Talking Face Generation
Apr 06, 2023The goal of this paper is to synthesise talking faces with controllable facial motions. To achieve this goal, we propose two key ideas. The first is to establish a canonical space where every face has the same motion patterns but different identities. The second is to navigate a multimodal motion space that only represents motion-related features while eliminating identity information. To disentangle identity and motion, we introduce an orthogonality constraint between the two different latent spaces. From this, our method can generate natural-looking talking faces with fully controllable facial attributes and accurate lip synchronisation. Extensive experiments demonstrate that our method achieves state-of-the-art results in terms of both visual quality and lip-sync score. To the best of our knowledge, we are the first to develop a talking face generation framework that can accurately manifest full target facial motions including lip, head pose, and eye movements in the generated video without any additional supervision beyond RGB video with audio.
CrossSpeech: Speaker-independent Acoustic Representation for Cross-lingual Speech Synthesis
Feb 28, 2023



While recent text-to-speech (TTS) systems have made remarkable strides toward human-level quality, the performance of cross-lingual TTS lags behind that of intra-lingual TTS. This gap is mainly rooted from the speaker-language entanglement problem in cross-lingual TTS. In this paper, we propose CrossSpeech which improves the quality of cross-lingual speech by effectively disentangling speaker and language information in the level of acoustic feature space. Specifically, CrossSpeech decomposes the speech generation pipeline into the speaker-independent generator (SIG) and speaker-dependent generator (SDG). The SIG produces the speaker-independent acoustic representation which is not biased to specific speaker distributions. On the other hand, the SDG models speaker-dependent speech variation that characterizes speaker attributes. By handling each information separately, CrossSpeech can obtain disentangled speaker and language representations. From the experiments, we verify that CrossSpeech achieves significant improvements in cross-lingual TTS, especially in terms of speaker similarity to the target speaker.
TF-GridNet: Integrating Full- and Sub-Band Modeling for Speech Separation
Nov 22, 2022We propose TF-GridNet for speech separation. The model is a novel multi-path deep neural network (DNN) integrating full- and sub-band modeling in the time-frequency (T-F) domain. It stacks several multi-path blocks, each consisting of an intra-frame full-band module, a sub-band temporal module, and a cross-frame self-attention module. It is trained to perform complex spectral mapping, where the real and imaginary (RI) components of input signals are stacked as features to predict target RI components. We first evaluate it on monaural anechoic speaker separation. Without using data augmentation and dynamic mixing, it obtains a state-of-the-art 23.5 dB improvement in scale-invariant signal-to-distortion ratio (SI-SDR) on WSJ0-2mix, a standard dataset for two-speaker separation. To show its robustness to noise and reverberation, we evaluate it on monaural reverberant speaker separation using the SMS-WSJ dataset and on noisy-reverberant speaker separation using WHAMR!, and obtain state-of-the-art performance on both datasets. We then extend TF-GridNet to multi-microphone conditions through multi-microphone complex spectral mapping, and integrate it into a two-DNN system with a beamformer in between (named as MISO-BF-MISO in earlier studies), where the beamformer proposed in this paper is a novel multi-frame Wiener filter computed based on the outputs of the first DNN. State-of-the-art performance is obtained on the multi-channel tasks of SMS-WSJ and WHAMR!. Besides speaker separation, we apply the proposed algorithms to speech dereverberation and noisy-reverberant speech enhancement. State-of-the-art performance is obtained on a dereverberation dataset and on the dataset of the recent L3DAS22 multi-channel speech enhancement challenge.