 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap between Audio and Text using Parallel-attention for User-defined Keyword Spotting
Paper and Code
Aug 07, 2024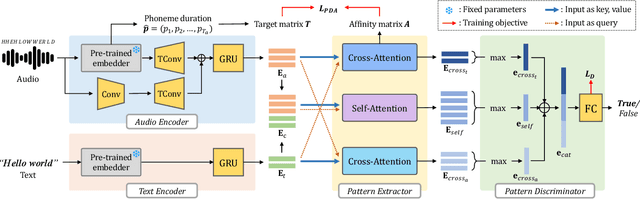
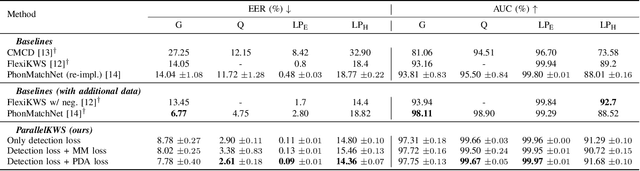

This paper proposes a novel user-defined keyword spotting framework that accurately detects audio keywords based on text enrollment. Since audio data possesses additional acoustic information compared to text, there are discrepancies between these two modalities. To address this challenge, we present ParallelKWS, which utilises self- and cross-attention in a parallel architecture to effectively capture information both within and across the two modalities. We further propose a phoneme duration-based alignment loss that enforces the sequential correspondence between audio and text features. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art performance on several benchmark datasets in both seen and unseen domains, without incorporating extra data beyond the dataset used in previous studies.