 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIS-assisted ISAC Systems for Industrial Revolution 6.0: Exploring the Near-field and Far-field Coexistence
Jul 10, 2025



The Industrial Internet of Things (IIoT) has emerged as a key technology for realizing the vision of Industry 6.0, requiring the seamless integration of diverse connected devices. In particular, integrated sensing and communication (ISAC) plays a critical role in supporting real-time control and automation within IIoT systems. In this paper, we explore reconfigurable intelligent surface (RIS)-assisted ISAC systems for IIoT in the coexistence of near-field and far-field regions. The system consists of a full-duplex access point (AP), a RIS and multiple IIoT devices, where the near-field devices simultaneously perform sensing and communication, while the far-field devices rely on a RIS-assisted communication. To enhance spectral efficiency for both sensing and communication functionalities, we consider the use of both traditional sensing-only (SO) and ISAC frequency bands. Moreover, uplink non-orthogonal multiple access (NOMA) is employed to facilitate the sequential decoding of superimposed communication and sensing signals from IIoT devices. To maximize sensing accuracy in terms of Cram${\Grave{\textrm{e}}}$r-Rao bound (CRB), we formulate a joint optimization of RIS phase shift, bandwidth splitting ratio and receive beamforming vector subject to the minimum data rate requirements of IIoT devices and resource budget constraints. The algorithmic solution is developed via the successive convex approximation (SCA)-based alternating optimization (AO) method with the semi-definite relaxation (SDR) technique. Numerical results demonstrate that the proposed method significantly outperforms conventional methods relying solely on either ISAC or SO band by achieving superior performance across RIS and device configurations, while ensuring robust ISAC performance under the near-field and far-field coexistence scenarios.
Test-Time Augmentation for Pose-invariant Face Recognition
May 14, 2025The goal of this paper is to enhance face recognition performance by augmenting head poses during the testing phase. Existing methods often rely on training on frontalised images or learning pose-invariant representations, yet both approaches typically require re-training and testing for each dataset, involving a substantial amount of effort. In contrast, this study proposes Pose-TTA, a novel approach that aligns faces at inference time without additional training. To achieve this, we employ a portrait animator that transfers the source image identity into the pose of a driving image. Instead of frontalising a side-profile face -- which can introduce distortion -- Pose-TTA generates matching side-profile images for comparison, thereby reducing identity information loss. Furthermore, we propose a weighted feature aggregation strategy to address any distortions or biases arising from the synthetic data, thus enhancing the reliability of the augmented images. Extensive experiments on diverse datasets and with various pre-trained face recognition models demonstrate that Pose-TTA consistently improves inference performance. Moreover, our method is straightforward to integrate into existing face recognition pipelines, as it requires no retraining or fine-tuning of the underlying recognition models.
VoiceDiT: Dual-Condition Diffusion Transformer for Environment-Aware Speech Synthesis
Dec 26, 2024We present VoiceDiT, a multi-modal generative model for producing environment-aware speech and audio from text and visual prompts. While aligning speech with text is crucial for intelligible speech, achieving this alignment in noisy conditions remains a significant and underexplored challenge in the field. To address this, we present a novel audio generation pipeline named VoiceDiT. This pipeline includes three key components: (1) the creation of a large-scale synthetic speech dataset for pre-training and a refined real-world speech dataset for fine-tuning, (2) the Dual-DiT, a model designed to efficiently preserve aligned speech information while accurately reflecting environmental conditions, and (3) a diffusion-based Image-to-Audio Translator that allows the model to bridge the gap between audio and image, facilitating the generation of environmental sound that aligns with the multi-modal prompts. Extensive experimental results demonstrate that VoiceDiT outperforms previous models on real-world datasets, showcasing significant improvements in both audio quality and modality integration.
Bridging the Gap between Audio and Text using Parallel-attention for User-defined Keyword Spotting
Aug 07, 2024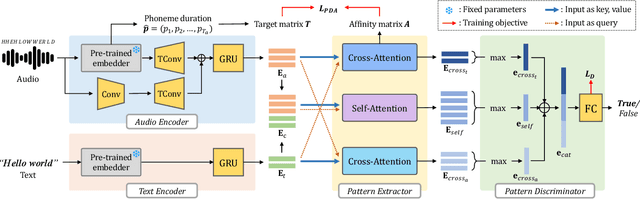
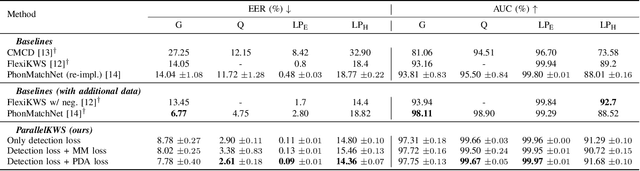

This paper proposes a novel user-defined keyword spotting framework that accurately detects audio keywords based on text enrollment. Since audio data possesses additional acoustic information compared to text, there are discrepancies between these two modalities. To address this challenge, we present ParallelKWS, which utilises self- and cross-attention in a parallel architecture to effectively capture information both within and across the two modalities. We further propose a phoneme duration-based alignment loss that enforces the sequential correspondence between audio and text features. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art performance on several benchmark datasets in both seen and unseen domains, without incorporating extra data beyond the dataset used in previous studies.
Disentangling Structure and Style: Political Bias Detection in News by Inducing Document Hierarchy
Apr 05, 2023



We address an important gap in detection of political bias in news articles. Previous works that perform supervised document classification can be biased towards the writing style of each news outlet, leading to overfitting and limited generalizability. Our approach overcomes this limitation by considering both the sentence-level semantics and the document-level rhetorical structure, resulting in a more robust and style-agnostic approach to detecting political bias in news articles. We introduce a novel multi-head hierarchical attention model that effectively encodes the structure of long documents through a diverse ensemble of attention heads. While journalism follows a formalized rhetorical structure, the writing style may vary by news outlet. We demonstrate that our method overcomes this domain dependency and outperforms previous approaches for robustness and accuracy. Further analysis demonstrates the ability of our model to capture the discourse structures commonly used in the journalism domain.
Metric Learning for User-defined Keyword Spotting
Nov 01, 2022The goal of this work is to detect new spoken terms defined by users. While most previous works address Keyword Spotting (KWS) as a closed-set classification problem, this limits their transferability to unseen terms. The ability to define custom keywords has advantages in terms of user experience. In this paper, we propose a metric learning-based training strategy for user-defined keyword spotting. In particular, we make the following contributions: (1) we construct a large-scale keyword dataset with an existing speech corpus and propose a filtering method to remove data that degrade model training; (2) we propose a metric learning-based two-stage training strategy, and demonstrate that the proposed method improves the performance on the user-defined keyword spotting task by enriching their representations; (3) to facilitate the fair comparison in the user-defined KWS field, we propose unified evaluation protocol and metrics. Our proposed system does not require an incremental training on the user-defined keywords, and outperforms previous works by a significant margin on the Google Speech Commands dataset using the proposed as well as the existing metrics.