 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAVID: Text-Driven Audio-Visual Interactive Dialogue Generation
Dec 23, 2025The objective of this paper is to jointly synthesize interactive videos and conversational speech from text and reference images. With the ultimate goal of building human-like conversational systems, recent studies have explored talking or listening head generation as well as conversational speech generation. However, these works are typically studied in isolation, overlooking the multimodal nature of human conversation, which involves tightly coupled audio-visual interactions. In this paper, we introduce TAVID, a unified framework that generates both interactive faces and conversational speech in a synchronized manner. TAVID integrates face and speech generation pipelines through two cross-modal mappers (i.e., a motion mapper and a speaker mapper), which enable bidirectional exchange of complementary information between the audio and visual modalities. We evaluate our system across four dimensions: talking face realism, listening head responsiveness, dyadic interaction fluency, and speech quality. Extensive experiments demonstrate the effectiveness of our approach across all these aspects.
Deep Understanding of Sign Language for Sign to Subtitle Alignment
Mar 05, 2025The objective of this work is to align asynchronous subtitles in sign language videos with limited labelled data. To achieve this goal, we propose a novel framework with the following contributions: (1) we leverage fundamental grammatical rules of British Sign Language (BSL) to pre-process the input subtitles, (2) we design a selective alignment loss to optimise the model for predicting the temporal location of signs only when the queried sign actually occurs in a scene, and (3) we conduct self-training with refined pseudo-labels which are more accurate than the heuristic audio-aligned labels. From this, our model not only better understands the correlation between the text and the signs, but also holds potential for application in the translation of sign languages, particularly in scenarios where manual labelling of large-scale sign data is impractical or challenging. Extensive experimental results demonstrate that our approach achieves state-of-the-art results, surpassing previous baselines by substantial margins in terms of both frame-level accuracy and F1-score. This highlights the effectiveness and practicality of our framework in advancing the field of sign language video alignment and translation.
VoiceDiT: Dual-Condition Diffusion Transformer for Environment-Aware Speech Synthesis
Dec 26, 2024We present VoiceDiT, a multi-modal generative model for producing environment-aware speech and audio from text and visual prompts. While aligning speech with text is crucial for intelligible speech, achieving this alignment in noisy conditions remains a significant and underexplored challenge in the field. To address this, we present a novel audio generation pipeline named VoiceDiT. This pipeline includes three key components: (1) the creation of a large-scale synthetic speech dataset for pre-training and a refined real-world speech dataset for fine-tuning, (2) the Dual-DiT, a model designed to efficiently preserve aligned speech information while accurately reflecting environmental conditions, and (3) a diffusion-based Image-to-Audio Translator that allows the model to bridge the gap between audio and image, facilitating the generation of environmental sound that aligns with the multi-modal prompts. Extensive experimental results demonstrate that VoiceDiT outperforms previous models on real-world datasets, showcasing significant improvements in both audio quality and modality integration.
VoxSim: A perceptual voice similarity dataset
Jul 26, 2024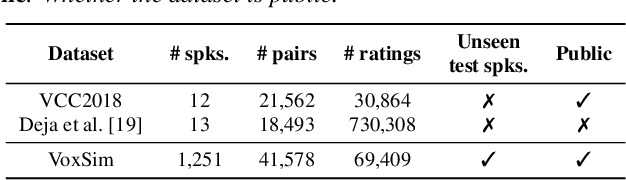
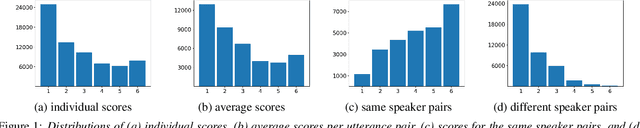


This paper introduces VoxSim, a dataset of perceptual voice similarity ratings. Recent efforts to automate the assessment of speech synthesis technologies have primarily focused on predicting mean opinion score of naturalness, leaving speaker voice similarity relatively unexplored due to a lack of extensive training data. To address this, we generate about 41k utterance pairs from the VoxCeleb dataset, a widely utilised speech dataset for speaker recognition, and collect nearly 70k speaker similarity scores through a listening test. VoxSim offers a valuable resource for the development and benchmarking of speaker similarity prediction models. We provide baseline results of speaker similarity prediction models on the VoxSim test set and further demonstrate that the model trained on our dataset generalises to the out-of-domain VCC2018 dataset.
Faces that Speak: Jointly Synthesising Talking Face and Speech from Text
May 16, 2024



The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.
SlowFast Network for Continuous Sign Language Recognition
Sep 21, 2023The objective of this work is the effective extraction of spatial and dynamic features for Continuous Sign Language Recognition (CSLR). To accomplish this, we utilise a two-pathway SlowFast network, where each pathway operates at distinct temporal resolutions to separately capture spatial (hand shapes, facial expressions) and dynamic (movements) information. In addition, we introduce two distinct feature fusion methods, carefully designed for the characteristics of CSLR: (1) Bi-directional Feature Fusion (BFF), which facilitates the transfer of dynamic semantics into spatial semantics and vice versa; and (2) Pathway Feature Enhancement (PFE), which enriches dynamic and spatial representations through auxiliary subnetworks, while avoiding the need for extra inference time. As a result, our model further strengthens spatial and dynamic representations in parallel. We demonstrate that the proposed framework outperforms the current state-of-the-art performance on popular CSLR datasets, including PHOENIX14, PHOENIX14-T, and CSL-Daily.