 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Steer: Decoupling Separation and Selection in Audio-Visual Target Speaker Extraction
Mar 20, 2026The goal of this paper is to provide a new perspective on audio-visual target speaker extraction (AV-TSE) by decoupling the separation and target selection. Conventional AV-TSE systems typically integrate audio and visual features deeply to re-learn the entire separation process, which can act as a fidelity ceiling due to the noisy nature of in-the-wild audio-visual datasets. To address this, we propose Plug-and-Steer, which assigns high-fidelity separation to a frozen audio-only backbone and limits the role of visual modality strictly to target selection. We introduce the Latent Steering Matrix (LSM), a minimalist linear transformation that re-routes latent features within the backbone to anchor the target speaker to a designated channel. Experiments across four representative architectures show that our method effectively preserves the acoustic priors of diverse backbones, achieving perceptual quality comparable to the original backbones. Audio samples are available at: https://plugandsteer.github.io
UNMIXX: Untangling Highly Correlated Singing Voices Mixtures
Jan 19, 2026We introduce UNMIXX, a novel framework for multiple singing voices separation (MSVS). While related to speech separation, MSVS faces unique challenges: data scarcity and the highly correlated nature of singing voices mixture. To address these issues, we propose UNMIXX with three key components: (1) musically informed mixing strategy to construct highly correlated, music-like mixtures, (2) cross-source attention that drives representations of two singers apart via reverse attention, and (3) magnitude penalty loss penalizing erroneously assigned interfering energy. UNMIXX not only addresses data scarcity by simulating realistic training data, but also excels at separating highly correlated mixtures through cross-source interactions at both the architectural and loss levels. Our extensive experiments demonstrate that UNMIXX greatly enhances performance, with SDRi gains exceeding 2.2 dB over prior work.
LP-CFM: Perceptual Invariance-Aware Conditional Flow Matching for Speech Modeling
Dec 23, 2025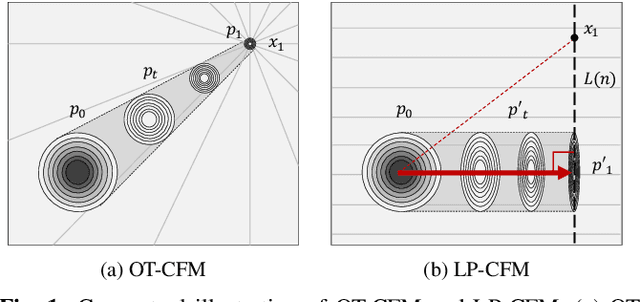
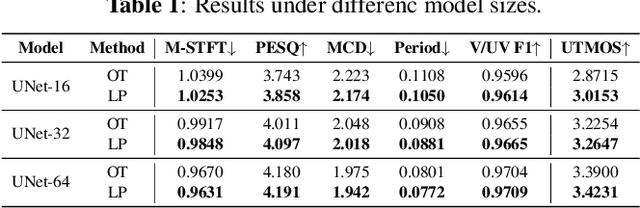
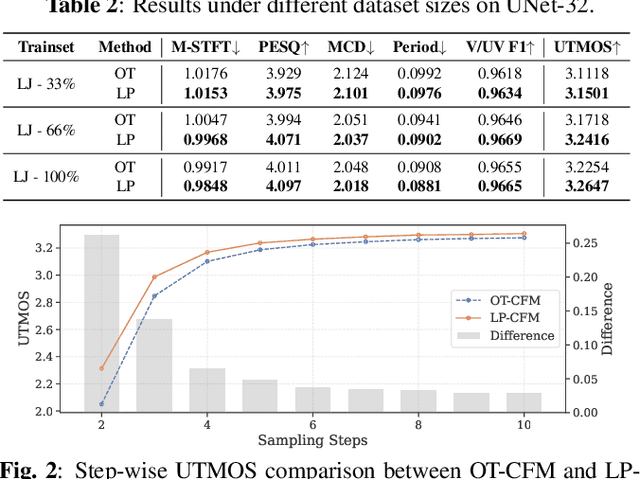

The goal of this paper is to provide a new perspective on speech modeling by incorporating perceptual invariances such as amplitude scaling and temporal shifts. Conventional generative formulations often treat each dataset sample as a fixed representative of the target distribution. From a generative standpoint, however, such samples are only one among many perceptually equivalent variants within the true speech distribution. To address this, we propose Linear Projection Conditional Flow Matching (LP-CFM), which models targets as projection-aligned elongated Gaussians along perceptually equivalent variants. We further introduce Vector Calibrated Sampling (VCS) to keep the sampling process aligned with the line-projection path. In neural vocoding experiments across model sizes, data scales, and sampling steps, the proposed approach consistently improves over the conventional optimal transport CFM, with particularly strong gains in low-resource and few-step scenarios. These results highlight the potential of LP-CFM and VCS to provide more robust and perceptually grounded generative modeling of speech.
TAVID: Text-Driven Audio-Visual Interactive Dialogue Generation
Dec 23, 2025The objective of this paper is to jointly synthesize interactive videos and conversational speech from text and reference images. With the ultimate goal of building human-like conversational systems, recent studies have explored talking or listening head generation as well as conversational speech generation. However, these works are typically studied in isolation, overlooking the multimodal nature of human conversation, which involves tightly coupled audio-visual interactions. In this paper, we introduce TAVID, a unified framework that generates both interactive faces and conversational speech in a synchronized manner. TAVID integrates face and speech generation pipelines through two cross-modal mappers (i.e., a motion mapper and a speaker mapper), which enable bidirectional exchange of complementary information between the audio and visual modalities. We evaluate our system across four dimensions: talking face realism, listening head responsiveness, dyadic interaction fluency, and speech quality. Extensive experiments demonstrate the effectiveness of our approach across all these aspects.
VoxSim: A perceptual voice similarity dataset
Jul 26, 2024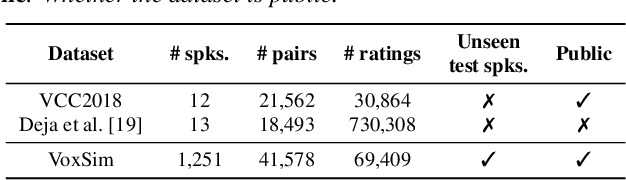
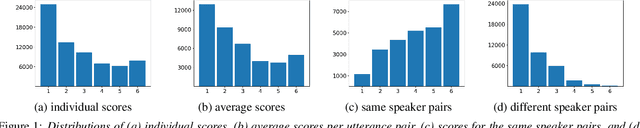


This paper introduces VoxSim, a dataset of perceptual voice similarity ratings. Recent efforts to automate the assessment of speech synthesis technologies have primarily focused on predicting mean opinion score of naturalness, leaving speaker voice similarity relatively unexplored due to a lack of extensive training data. To address this, we generate about 41k utterance pairs from the VoxCeleb dataset, a widely utilised speech dataset for speaker recognition, and collect nearly 70k speaker similarity scores through a listening test. VoxSim offers a valuable resource for the development and benchmarking of speaker similarity prediction models. We provide baseline results of speaker similarity prediction models on the VoxSim test set and further demonstrate that the model trained on our dataset generalises to the out-of-domain VCC2018 dataset.
Faces that Speak: Jointly Synthesising Talking Face and Speech from Text
May 16, 2024



The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.