 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMO: Multilingual Information Retrieval via Monolingual Objectives
May 29, 2026Multilingual Information Retrieval (MLIR) reflects real-world search environments in which queries and relevant documents may appear in different languages within a mixed-language corpus. However, existing embedding models are primarily optimized for Multi-Monolingual retrieval and their performance often degrades in MLIR settings. Moreover, directly applying conventional contrastive learning to MLIR can exacerbate language clustering and expose a trade-off between cross-lingual alignment and embedding uniformity. To address these limitations, we propose MIMO: Multilingual Information Retrieval via Monolingual Objectives, a two-stage framework that uses a stable English semantic space from a high-performing teacher model as an anchor. MIMO first initializes the student model's cross-lingual alignment through knowledge distillation, and then jointly optimizes distillation and cross-lingual contrastive learning to improve retrieval discrimination while preserving alignment. Extensive experiments show that MIMO consistently outperforms existing cross-lingual training baselines across various MLIR and Multi-Monolingual benchmarks. MIMO also remains competitive with off-the-shelf models of similar or larger parameter scales. Furthermore, our cross-lingual Alignment-Uniformity analysis clarifies the distinct roles of the two loss components and shows that their combination yields a favorable trade-off between alignment and uniformity.
SemBridge: Language Transfer in Sparse Encoders via Multilingual Semantic Bridges
May 25, 2026Sparse encoders offer high-precision retrieval by representing term importance within a vocabulary space, yet their English-centric structures pose a critical impediment to language transfer for non-English languages. To overcome this structural limitation, we propose SemBridge, a novel embedding initialization method designed for cross-lingual adaptation in sparse encoders by leveraging multilingual bridge models. SemBridge establishes semantic alignments between source and target vocabularies using multilingual dense embeddings as a bridge. Rather than directly relying on all source tokens, SemBridge selects a small set of semantically related source-language tokens and uses them to initialize each target-language token, effectively filtering out semantic noise and reconstructing target tokens as precise linear combinations of core synonyms. This accelerates convergence during fine-tuning and improves training efficiency. Extensive experiments across five languages and four sparse architectures demonstrate that SemBridge achieves superior zero-shot retrieval performance and consistently improves retrieval performance after fine-tuning compared to existing baselines. These results validate SemBridge as a practical solution for deploying high-performance sparse retrieval systems in diverse linguistic environments.
LegalMidm: Use-Case-Driven Legal Domain Specialization for Korean Large Language Model
Apr 28, 2026In recent years, the rapid proliferation of open-source large language models (LLMs) has spurred efforts to turn general-purpose models into domain specialists. However, many domain-specialized LLMs are developed using datasets and training protocols that are not aligned with the nuanced requirements of real-world applications. In the legal domain, where precision and reliability are essential, this lack of consideration limits practical utility. In this study, we propose a systematic training framework grounded in the practical needs of the legal domain, with a focus on Korean law. We introduce LegalMidm, a Korean legal-domain LLM, and present a methodology for constructing high-quality, use-case-driven legal datasets and optimized training pipelines. Our approach emphasizes collaboration with legal professionals and rigorous data curation to ensure relevance and factual accuracy, and demonstrates effectiveness in key legal tasks.
Improving Semantic Proximity in Information Retrieval through Cross-Lingual Alignment
Apr 07, 2026With the increasing accessibility and utilization of multilingual documents, Cross-Lingual Information Retrieval (CLIR) has emerged as an important research area. Conventionally, CLIR tasks have been conducted under settings where the language of documents differs from that of queries, and typically, the documents are composed in a single coherent language. In this paper, we highlight that in such a setting, the cross-lingual alignment capability may not be evaluated adequately. Specifically, we observe that, in a document pool where English documents coexist with another language, most multilingual retrievers tend to prioritize unrelated English documents over the related document written in the same language as the query. To rigorously analyze and quantify this phenomenon, we introduce various scenarios and metrics designed to evaluate the cross-lingual alignment performance of multilingual retrieval models. Furthermore, to improve cross-lingual performance under these challenging conditions, we propose a novel training strategy aimed at enhancing cross-lingual alignment. Using only a small dataset consisting of 2.8k samples, our method significantly improves the cross-lingual retrieval performance while simultaneously mitigating the English inclination problem. Extensive analyses demonstrate that the proposed method substantially enhances the cross-lingual alignment capabilities of most multilingual embedding models.
CLEAR: Cross-Lingual Enhancement in Alignment via Reverse-training
Apr 07, 2026Existing multilingual embedding models often encounter challenges in cross-lingual scenarios due to imbalanced linguistic resources and less consideration of cross-lingual alignment during training. Although standardized contrastive learning approaches for cross-lingual adaptation are widely adopted, they may struggle to capture fundamental alignment between languages and degrade performance in well-aligned languages such as English. To address these challenges, we propose Cross-Lingual Enhancement in Retrieval via Reverse-training (CLEAR), a novel loss function utilizing a reverse training scheme to improve retrieval performance across diverse cross-lingual retrieval scenarios. CLEAR leverages an English passage as a bridge to strengthen alignments between the target language and English, ensuring robust performance in the cross-lingual retrieval task. Our extensive experiments demonstrate that CLEAR achieves notable improvements in cross-lingual scenarios, with gains up to 15%, particularly in low-resource languages, while minimizing performance degradation in English. Furthermore, our findings highlight that CLEAR offers promising effectiveness even in multilingual training, suggesting its potential for broad application and scalability. We release the code at https://github.com/dltmddbs100/CLEAR.
Beyond Hard Negatives: The Importance of Score Distribution in Knowledge Distillation for Dense Retrieval
Apr 06, 2026Transferring knowledge from a cross-encoder teacher via Knowledge Distillation (KD) has become a standard paradigm for training retrieval models. While existing studies have largely focused on mining hard negatives to improve discrimination, the systematic composition of training data and the resulting teacher score distribution have received relatively less attention. In this work, we highlight that focusing solely on hard negatives prevents the student from learning the comprehensive preference structure of the teacher, potentially hampering generalization. To effectively emulate the teacher score distribution, we propose a Stratified Sampling strategy that uniformly covers the entire score spectrum. Experiments on in-domain and out-of-domain benchmarks confirm that Stratified Sampling, which preserves the variance and entropy of teacher scores, serves as a robust baseline, significantly outperforming top-K and random sampling in diverse settings. These findings suggest that the essence of distillation lies in preserving the diverse range of relative scores perceived by the teacher.
On the Nature of Attention Sink that Shapes Decoding Strategy in MLLMs
Mar 15, 2026Large language models and their multimodal extensions have achieved remarkable success across diverse tasks, yet the internal mechanisms that govern their reasoning behaviour remain partially understood. In particular, the attention sink, a token that attracts disproportionate attention mass, has been observed in transformer architectures, but its role is still unclear. Our goal is to understand what attention sinks represent and how they shape model behaviour during inference, rather than considering them as incidental artifacts. Through our analysis, we find that attention sink representations encode structured global information that influences the decoding process. Building on our findings, we introduce OutRo, a lightweight inference-time strategy that leverages the sink token to enhance contextual representations: (i) non-sink token representations are aligned with the sink representation in the feature space; and (ii) the sink token is allowed to attend beyond the causal constraint, facilitating information exchange with non-sink tokens. This design enhances the reasoning process without requiring additional forward passes or access to attention maps. Based on extensive experiments, OutRo consistently improves performance across representative MLLMs on seven video QA benchmarks and demonstrates strong generalisation, while incurring only a 1.1x decoding overhead.
FastAV: Efficient Token Pruning for Audio-Visual Large Language Model Inference
Jan 19, 2026In this work, we present FastAV, the first token pruning framework tailored for audio-visual large language models (AV-LLMs). While token pruning has been actively explored in standard large language models (LLMs) and vision-language models (LVLMs), its application to AV-LLMs has received little attention, even though multimodal integration substantially increases their token demands. To address this gap, we introduce a pruning strategy that utilizes attention weights to identify tokens emphasized at different stages and estimates their importance. Building on this analysis, FastAV applies a two-stage pruning strategy: (1) global pruning in intermediate layers to remove broadly less influential tokens, and (2) fine pruning in later layers considering the impact on next token generation. Notably, our method does not rely on full attention maps, which makes it fully compatible with efficient attention mechanisms such as FlashAttention. Extensive experiments demonstrate that FastAV reduces FLOPs by more than 40% on two representative AV-LLMs, while preserving or even improving model performance.
LP-CFM: Perceptual Invariance-Aware Conditional Flow Matching for Speech Modeling
Dec 23, 2025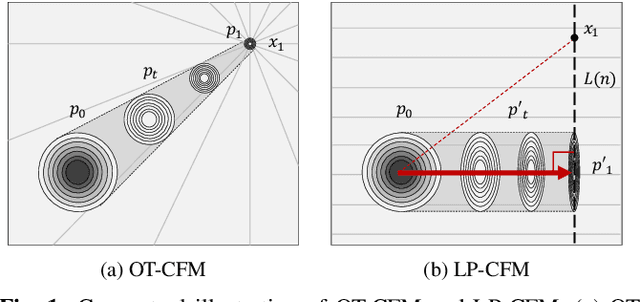
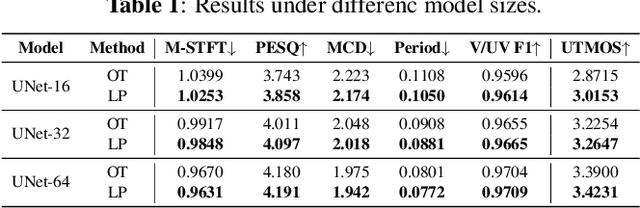
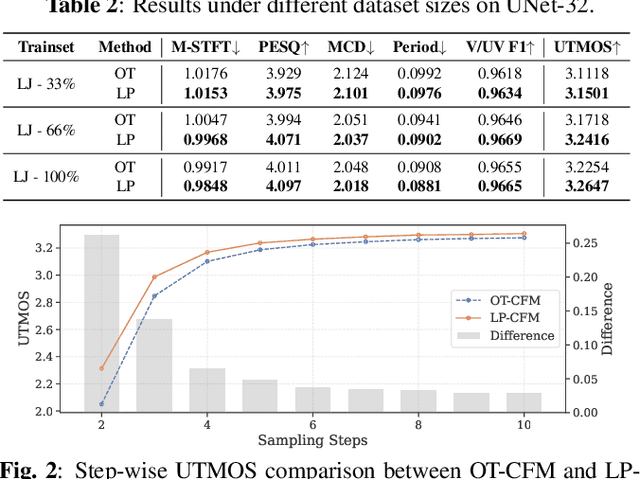

The goal of this paper is to provide a new perspective on speech modeling by incorporating perceptual invariances such as amplitude scaling and temporal shifts. Conventional generative formulations often treat each dataset sample as a fixed representative of the target distribution. From a generative standpoint, however, such samples are only one among many perceptually equivalent variants within the true speech distribution. To address this, we propose Linear Projection Conditional Flow Matching (LP-CFM), which models targets as projection-aligned elongated Gaussians along perceptually equivalent variants. We further introduce Vector Calibrated Sampling (VCS) to keep the sampling process aligned with the line-projection path. In neural vocoding experiments across model sizes, data scales, and sampling steps, the proposed approach consistently improves over the conventional optimal transport CFM, with particularly strong gains in low-resource and few-step scenarios. These results highlight the potential of LP-CFM and VCS to provide more robust and perceptually grounded generative modeling of speech.
Segment, Embed, and Align: A Universal Recipe for Aligning Subtitles to Signing
Dec 08, 2025The goal of this work is to develop a universal approach for aligning subtitles (i.e., spoken language text with corresponding timestamps) to continuous sign language videos. Prior approaches typically rely on end-to-end training tied to a specific language or dataset, which limits their generality. In contrast, our method Segment, Embed, and Align (SEA) provides a single framework that works across multiple languages and domains. SEA leverages two pretrained models: the first to segment a video frame sequence into individual signs and the second to embed the video clip of each sign into a shared latent space with text. Alignment is subsequently performed with a lightweight dynamic programming procedure that runs efficiently on CPUs within a minute, even for hour-long episodes. SEA is flexible and can adapt to a wide range of scenarios, utilizing resources from small lexicons to large continuous corpora. Experiments on four sign language datasets demonstrate state-of-the-art alignment performance, highlighting the potential of SEA to generate high-quality parallel data for advancing sign language processing. SEA's code and models are openly available.