 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCinematic Audio Source Separation Using Visual Cues
Mar 27, 2026Cinematic Audio Source Separation (CASS) aims to decompose mixed film audio into speech, music, and sound effects, enabling applications like dubbing and remastering. Existing CASS approaches are audio-only, overlooking the inherent audio-visual nature of films, where sounds often align with visual cues. We present the first framework for audio-visual CASS (AV-CASS), leveraging visual context to enhance separation quality. Our method formulates CASS as a conditional generative modeling problem using conditional flow matching, enabling multimodal audio source separation. To address the lack of cinematic datasets with isolated sound tracks, we introduce a training data synthesis pipeline that pairs in-the-wild audio and video streams (e.g., facial videos for speech, scene videos for effects) and design a dedicated visual encoder for this dual-stream setup. Trained entirely on synthetic data, our model generalizes effectively to real-world cinematic content and achieves strong performance on synthetic, real-world, and audio-only CASS benchmarks. Code and demo are available at \url{https://cass-flowmatching.github.io}.
Plug-and-Steer: Decoupling Separation and Selection in Audio-Visual Target Speaker Extraction
Mar 20, 2026The goal of this paper is to provide a new perspective on audio-visual target speaker extraction (AV-TSE) by decoupling the separation and target selection. Conventional AV-TSE systems typically integrate audio and visual features deeply to re-learn the entire separation process, which can act as a fidelity ceiling due to the noisy nature of in-the-wild audio-visual datasets. To address this, we propose Plug-and-Steer, which assigns high-fidelity separation to a frozen audio-only backbone and limits the role of visual modality strictly to target selection. We introduce the Latent Steering Matrix (LSM), a minimalist linear transformation that re-routes latent features within the backbone to anchor the target speaker to a designated channel. Experiments across four representative architectures show that our method effectively preserves the acoustic priors of diverse backbones, achieving perceptual quality comparable to the original backbones. Audio samples are available at: https://plugandsteer.github.io
KMI: A Dataset of Korean Motivational Interviewing Dialogues for Psychotherapy
Feb 08, 2025



The increasing demand for mental health services has led to the rise of AI-driven mental health chatbots, though challenges related to privacy, data collection, and expertise persist. Motivational Interviewing (MI) is gaining attention as a theoretical basis for boosting expertise in the development of these chatbots. However, existing datasets are showing limitations for training chatbots, leading to a substantial demand for publicly available resources in the field of MI and psychotherapy. These challenges are even more pronounced in non-English languages, where they receive less attention. In this paper, we propose a novel framework that simulates MI sessions enriched with the expertise of professional therapists. We train an MI forecaster model that mimics the behavioral choices of professional therapists and employ Large Language Models (LLMs) to generate utterances through prompt engineering. Then, we present KMI, the first synthetic dataset theoretically grounded in MI, containing 1,000 high-quality Korean Motivational Interviewing dialogues. Through an extensive expert evaluation of the generated dataset and the dialogue model trained on it, we demonstrate the quality, expertise, and practicality of KMI. We also introduce novel metrics derived from MI theory in order to evaluate dialogues from the perspective of MI.
YA-TA: Towards Personalized Question-Answering Teaching Assistants using Instructor-Student Dual Retrieval-augmented Knowledge Fusion
Aug 31, 2024



Engagement between instructors and students plays a crucial role in enhancing students'academic performance. However, instructors often struggle to provide timely and personalized support in large classes. To address this challenge, we propose a novel Virtual Teaching Assistant (VTA) named YA-TA, designed to offer responses to students that are grounded in lectures and are easy to understand. To facilitate YA-TA, we introduce the Dual Retrieval-augmented Knowledge Fusion (DRAKE) framework, which incorporates dual retrieval of instructor and student knowledge and knowledge fusion for tailored response generation. Experiments conducted in real-world classroom settings demonstrate that the DRAKE framework excels in aligning responses with knowledge retrieved from both instructor and student sides. Furthermore, we offer additional extensions of YA-TA, such as a Q&A board and self-practice tools to enhance the overall learning experience. Our video is publicly available.
Cactus: Towards Psychological Counseling Conversations using Cognitive Behavioral Theory
Jul 03, 2024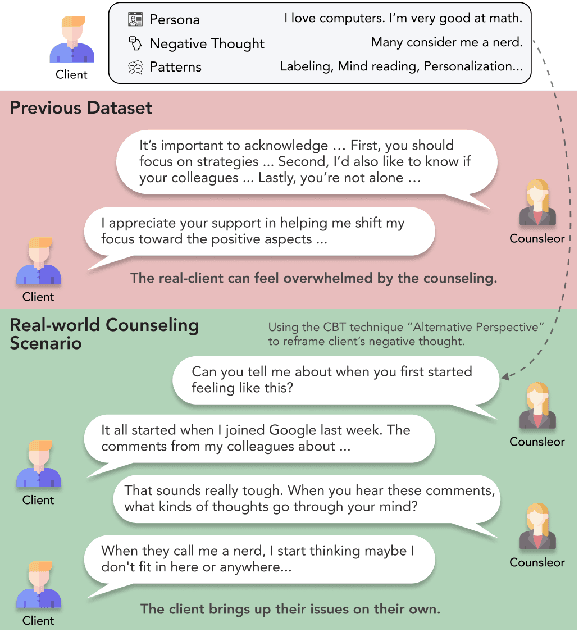



Recently, the demand for psychological counseling has significantly increased as more individuals express concerns about their mental health. This surge has accelerated efforts to improve the accessibility of counseling by using large language models (LLMs) as counselors. To ensure client privacy, training open-source LLMs faces a key challenge: the absence of realistic counseling datasets. To address this, we introduce Cactus, a multi-turn dialogue dataset that emulates real-life interactions using the goal-oriented and structured approach of Cognitive Behavioral Therapy (CBT). We create a diverse and realistic dataset by designing clients with varied, specific personas, and having counselors systematically apply CBT techniques in their interactions. To assess the quality of our data, we benchmark against established psychological criteria used to evaluate real counseling sessions, ensuring alignment with expert evaluations. Experimental results demonstrate that Camel, a model trained with Cactus, outperforms other models in counseling skills, highlighting its effectiveness and potential as a counseling agent. We make our data, model, and code publicly available.
FlowAVSE: Efficient Audio-Visual Speech Enhancement with Conditional Flow Matching
Jun 13, 2024This work proposes an efficient method to enhance the quality of corrupted speech signals by leveraging both acoustic and visual cues. While existing diffusion-based approaches have demonstrated remarkable quality, their applicability is limited by slow inference speeds and computational complexity. To address this issue, we present FlowAVSE which enhances the inference speed and reduces the number of learnable parameters without degrading the output quality. In particular, we employ a conditional flow matching algorithm that enables the generation of high-quality speech in a single sampling step. Moreover, we increase efficiency by optimizing the underlying U-net architecture of diffusion-based systems. Our experiments demonstrate that FlowAVSE achieves 22 times faster inference speed and reduces the model size by half while maintaining the output quality. The demo page is available at: https://cyongong.github.io/FlowAVSE.github.io/
COCOA: CBT-based Conversational Counseling Agent using Memory Specialized in Cognitive Distortions and Dynamic Prompt
Feb 27, 2024

The demand for conversational agents that provide mental health care is consistently increasing. In this work, we develop a psychological counseling agent, referred to as CoCoA, that applies Cognitive Behavioral Therapy (CBT) techniques to identify and address cognitive distortions inherent in the client's statements. Specifically, we construct a memory system to efficiently manage information necessary for counseling while extracting high-level insights about the client from their utterances. Additionally, to ensure that the counseling agent generates appropriate responses, we introduce dynamic prompting to flexibly apply CBT techniques and facilitate the appropriate retrieval of information. We conducted dialogues between CoCoA and characters from Character.ai, creating a dataset for evaluation. Then, we asked GPT to evaluate the constructed counseling dataset, and our model demonstrated a statistically significant difference from other models.
Seeing Through the Conversation: Audio-Visual Speech Separation based on Diffusion Model
Oct 30, 2023The objective of this work is to extract target speaker's voice from a mixture of voices using visual cues. Existing works on audio-visual speech separation have demonstrated their performance with promising intelligibility, but maintaining naturalness remains a challenge. To address this issue, we propose AVDiffuSS, an audio-visual speech separation model based on a diffusion mechanism known for its capability in generating natural samples. For an effective fusion of the two modalities for diffusion, we also propose a cross-attention-based feature fusion mechanism. This mechanism is specifically tailored for the speech domain to integrate the phonetic information from audio-visual correspondence in speech generation. In this way, the fusion process maintains the high temporal resolution of the features, without excessive computational requirements. We demonstrate that the proposed framework achieves state-of-the-art results on two benchmarks, including VoxCeleb2 and LRS3, producing speech with notably better naturalness.
TalkNCE: Improving Active Speaker Detection with Talk-Aware Contrastive Learning
Sep 21, 2023



The goal of this work is Active Speaker Detection (ASD), a task to determine whether a person is speaking or not in a series of video frames. Previous works have dealt with the task by exploring network architectures while learning effective representations has been less explored. In this work, we propose TalkNCE, a novel talk-aware contrastive loss. The loss is only applied to part of the full segments where a person on the screen is actually speaking. This encourages the model to learn effective representations through the natural correspondence of speech and facial movements. Our loss can be jointly optimized with the existing objectives for training ASD models without the need for additional supervision or training data. The experiments demonstrate that our loss can be easily integrated into the existing ASD frameworks, improving their performance. Our method achieves state-of-the-art performances on AVA-ActiveSpeaker and ASW datasets.