 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation
Oct 17, 2024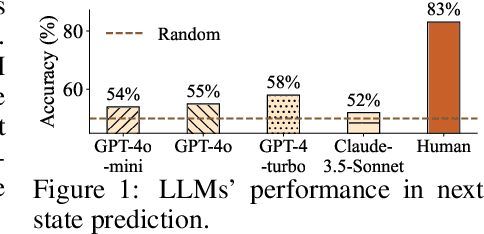
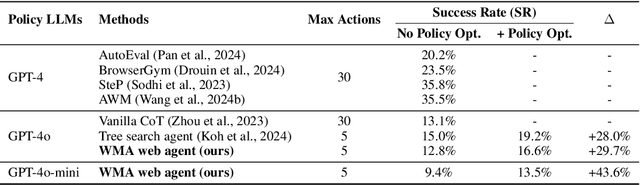
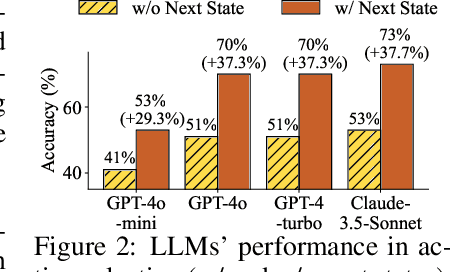

Large language models (LLMs) have recently gained much attention in building autonomous agents. However, the performance of current LLM-based web agents in long-horizon tasks is far from optimal, often yielding errors such as repeatedly buying a non-refundable flight ticket. By contrast, humans can avoid such an irreversible mistake, as we have an awareness of the potential outcomes (e.g., losing money) of our actions, also known as the "world model". Motivated by this, our study first starts with preliminary analyses, confirming the absence of world models in current LLMs (e.g., GPT-4o, Claude-3.5-Sonnet, etc.). Then, we present a World-model-augmented (WMA) web agent, which simulates the outcomes of its actions for better decision-making. To overcome the challenges in training LLMs as world models predicting next observations, such as repeated elements across observations and long HTML inputs, we propose a transition-focused observation abstraction, where the prediction objectives are free-form natural language descriptions exclusively highlighting important state differences between time steps. Experiments on WebArena and Mind2Web show that our world models improve agents' policy selection without training and demonstrate our agents' cost- and time-efficiency compared to recent tree-search-based agents.
YA-TA: Towards Personalized Question-Answering Teaching Assistants using Instructor-Student Dual Retrieval-augmented Knowledge Fusion
Aug 31, 2024



Engagement between instructors and students plays a crucial role in enhancing students'academic performance. However, instructors often struggle to provide timely and personalized support in large classes. To address this challenge, we propose a novel Virtual Teaching Assistant (VTA) named YA-TA, designed to offer responses to students that are grounded in lectures and are easy to understand. To facilitate YA-TA, we introduce the Dual Retrieval-augmented Knowledge Fusion (DRAKE) framework, which incorporates dual retrieval of instructor and student knowledge and knowledge fusion for tailored response generation. Experiments conducted in real-world classroom settings demonstrate that the DRAKE framework excels in aligning responses with knowledge retrieved from both instructor and student sides. Furthermore, we offer additional extensions of YA-TA, such as a Q&A board and self-practice tools to enhance the overall learning experience. Our video is publicly available.
THEANINE: Revisiting Memory Management in Long-term Conversations with Timeline-augmented Response Generation
Jun 16, 2024



Large language models (LLMs) are capable of processing lengthy dialogue histories during prolonged interaction with users without additional memory modules; however, their responses tend to overlook or incorrectly recall information from the past. In this paper, we revisit memory-augmented response generation in the era of LLMs. While prior work focuses on getting rid of outdated memories, we argue that such memories can provide contextual cues that help dialogue systems understand the development of past events and, therefore, benefit response generation. We present Theanine, a framework that augments LLMs' response generation with memory timelines -- series of memories that demonstrate the development and causality of relevant past events. Along with Theanine, we introduce TeaFarm, a counterfactual-driven question-answering pipeline addressing the limitation of G-Eval in long-term conversations. Supplementary videos of our methods and the TeaBag dataset for TeaFarm evaluation are in https://theanine-693b0.web.app/.