 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSToRM: Supervised Token Reduction for Multi-modal LLMs toward efficient end-to-end autonomous driving
Feb 12, 2026In autonomous driving, end-to-end (E2E) driving systems that predict control commands directly from sensor data have achieved significant advancements. For safe driving in unexpected scenarios, these systems may additionally rely on human interventions such as natural language instructions. Using a multi-modal large language model (MLLM) facilitates human-vehicle interaction and can improve performance in such scenarios. However, this approach requires substantial computational resources due to its reliance on an LLM and numerous visual tokens from sensor inputs, which are limited in autonomous vehicles. Many MLLM studies have explored reducing visual tokens, but often suffer end-task performance degradation compared to using all tokens. To enable efficient E2E driving while maintaining performance comparable to using all tokens, this paper proposes the first Supervised Token Reduction framework for multi-modal LLMs (SToRM). The proposed framework consists of three key elements. First, a lightweight importance predictor with short-term sliding windows estimates token importance scores. Second, a supervised training approach uses an auxiliary path to obtain pseudo-supervision signals from an all-token LLM pass. Third, an anchor-context merging module partitions tokens into anchors and context tokens, and merges context tokens into relevant anchors to reduce redundancy while minimizing information loss. Experiments on the LangAuto benchmark show that SToRM outperforms state-of-the-art E2E driving MLLMs under the same reduced-token budget, maintaining all-token performance while reducing computational cost by up to 30x.
KLASS: KL-Guided Fast Inference in Masked Diffusion Models
Nov 07, 2025Masked diffusion models have demonstrated competitive results on various tasks including language generation. However, due to its iterative refinement process, the inference is often bottlenecked by slow and static sampling speed. To overcome this problem, we introduce `KL-Adaptive Stability Sampling' (KLASS), a fast yet effective sampling method that exploits token-level KL divergence to identify stable, high-confidence predictions. By unmasking multiple tokens in each iteration without any additional model training, our approach speeds up generation significantly while maintaining sample quality. On reasoning benchmarks, KLASS achieves up to $2.78\times$ wall-clock speedups while improving performance over standard greedy decoding, attaining state-of-the-art results among diffusion-based samplers. We further validate KLASS across diverse domains, including text, image, and molecular generation, showing its effectiveness as a broadly applicable sampler across different models.
Self-Training Elicits Concise Reasoning in Large Language Models
Feb 28, 2025Chain-of-thought (CoT) reasoning has enabled large language models (LLMs) to utilize additional computation through intermediate tokens to solve complex tasks. However, we posit that typical reasoning traces contain many redundant tokens, incurring extraneous inference costs. Upon examination of the output distribution of current LLMs, we find evidence on their latent ability to reason more concisely, relative to their default behavior. To elicit this capability, we propose simple fine-tuning methods which leverage self-generated concise reasoning paths obtained by best-of-N sampling and few-shot conditioning, in task-specific settings. Our combined method achieves a 30% reduction in output tokens on average, across five model families on GSM8K and MATH, while maintaining average accuracy. By exploiting the fundamental stochasticity and in-context learning capabilities of LLMs, our self-training approach robustly elicits concise reasoning on a wide range of models, including those with extensive post-training. Code is available at https://github.com/TergelMunkhbat/concise-reasoning
THEANINE: Revisiting Memory Management in Long-term Conversations with Timeline-augmented Response Generation
Jun 16, 2024



Large language models (LLMs) are capable of processing lengthy dialogue histories during prolonged interaction with users without additional memory modules; however, their responses tend to overlook or incorrectly recall information from the past. In this paper, we revisit memory-augmented response generation in the era of LLMs. While prior work focuses on getting rid of outdated memories, we argue that such memories can provide contextual cues that help dialogue systems understand the development of past events and, therefore, benefit response generation. We present Theanine, a framework that augments LLMs' response generation with memory timelines -- series of memories that demonstrate the development and causality of relevant past events. Along with Theanine, we introduce TeaFarm, a counterfactual-driven question-answering pipeline addressing the limitation of G-Eval in long-term conversations. Supplementary videos of our methods and the TeaBag dataset for TeaFarm evaluation are in https://theanine-693b0.web.app/.
Ever-Evolving Memory by Blending and Refining the Past
Mar 03, 2024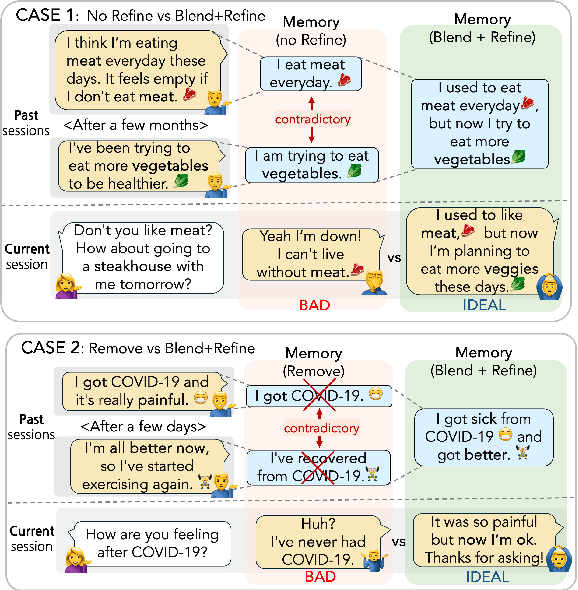
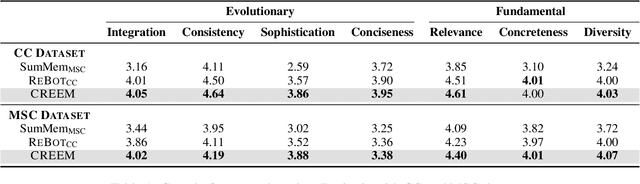
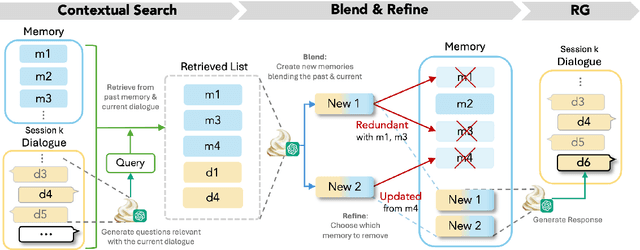
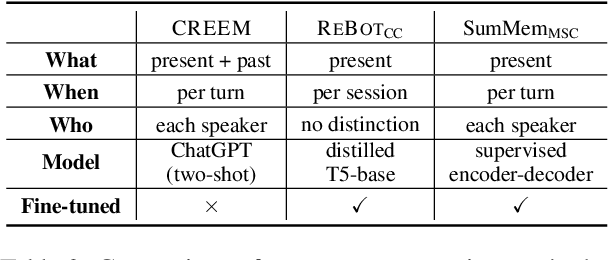
For a human-like chatbot, constructing a long-term memory is crucial. A naive approach for making a memory could be simply listing the summarized dialogue. However, this can lead to problems when the speaker's status change over time and contradictory information gets accumulated. It is important that the memory stays organized to lower the confusion for the response generator. In this paper, we propose a novel memory scheme for long-term conversation, CREEM. Unlike existing approaches that construct memory based solely on current sessions, our proposed model blending past memories during memory formation. Additionally, we introduce refining process to handle redundant or outdated information. This innovative approach seeks for overall improvement and coherence of chatbot responses by ensuring a more informed and dynamically evolving long-term memory.