 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMBGuard: Constructing Hazard-Aware Guardrails for Safe Planning in Embodied Agents
May 29, 2026MLLM-powered embodied agents deployed in real-world environments encounter physical hazards. However, existing approaches lack explicit mechanisms for identifying hazards and reasoning about action-conditioned risks, leading agents to either miss risky interactions or over-identify risks. To address this, we propose EMBGuard, the first MLLM-based safety guardrail for embodied agents designed to decouple physical risk reasoning from agent policy. By evaluating a (visual observation, action) pair, EMBGuard identifies hazardous configurations and provides natural language explanations of potential risks. Alongside EMBGuard, we contribute EMBHazard, a training dataset of 15.1K action-conditioned pairs, and EMBGuardTest, a benchmark of 329 manually curated real-world scenarios spanning seven physical risk categories. Through compositional variation of hazards and actions, we generate diverse risky and benign scenarios that agents may encounter during planning. Despite its compact size (2B, 4B), EMBGuard achieves performance competitive with proprietary MLLMs (e.g., GPT-5.1, Gemini-2.5-Pro) while significantly reducing the false-positive rates that hinder real-time deployment. We make the code, data, and models publicly available at https://github.com/dongwxxkchoi/EMBGuard
Towards Direct Evaluation of Harness Optimizers via Priority Ranking
May 21, 2026Harness optimization enables automated agent creation by having an optimizer agent iteratively update the harness of target agents. Despite its success, current studies evaluate optimizers solely by observing target agents' performance gains. This indirect end-improvement evaluation neglects optimizers' actions at intermediate steps, which are often erroneous and hinder agent performance. Therefore, it is unclear whether harness optimization is driven by optimizers' informed update actions or simply trial-and-error. This necessitates direct evaluation of harness optimizers. However, evaluating harness optimizers directly is non-trivial and costly due to the lack of oracle harnesses. To address this, we present a simple, low-cost design to directly evaluate them, namely priority ranking. By asking harness optimizers to rank components (e.g., tools) in a given harness by their potential to improve/hinder agent performance when updated, our design quantifies optimizer ability at the step level without expensive rollouts or manual examination. More importantly, optimizers' ranking performance correlates with their ability to improve agents in actual multi-step harness optimization, establishing priority ranking as a reliable predictor of optimization ability. Priority ranking is enabled by Shor, a collection of 182 human-verified optimization scenarios spanning across domains, designs, and time stages. Codes and data can be found at https://github.com/k59118/Harness_Optimizer_Evaluation.
On Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length
May 04, 2026Large language models (LLMs) have shown promise as interactive agents that solve tasks through extended sequences of environment interactions. While prior work has primarily focused on system-level optimizations or algorithmic improvements, the role of task horizon length in shaping training dynamics remains poorly understood. In this work, we present a systematic empirical study that examines horizon length through controlled task constructions. Specifically, we construct controlled tasks in which agents face identical decision rules and reasoning structures, but differ only in the length of action sequences required for successful completion. Our results reveal that increasing horizon length alone constitutes a training bottleneck, inducing severe training instability driven by exploration difficulties and credit assignment challenges. We demonstrate that horizon reduction is a key principle to address this limitation, stabilizing training and achieving better performance in long-horizon tasks. Moreover, we find that horizon reduction is related to stronger generalization across horizon lengths: models trained under reduced horizons generalize more effectively to longer-horizon variants at inference time, a phenomenon we refer to as horizon generalization.
PAC-BENCH: Evaluating Multi-Agent Collaboration under Privacy Constraints
Apr 13, 2026We are entering an era in which individuals and organizations increasingly deploy dedicated AI agents that interact and collaborate with other agents. However, the dynamics of multi-agent collaboration under privacy constraints remain poorly understood. In this work, we present $PAC\text{-}Bench$, a benchmark for systematic evaluation of multi-agent collaboration under privacy constraints. Experiments on $PAC\text{-}Bench$ show that privacy constraints substantially degrade collaboration performance and make outcomes depend more on the initiating agent than the partner. Further analysis reveals that this degradation is driven by recurring coordination breakdowns, including early-stage privacy violations, overly conservative abstraction, and privacy-induced hallucinations. Together, our findings identify privacy-aware multi-agent collaboration as a distinct and unresolved challenge that requires new coordination mechanisms beyond existing agent capabilities.
Designing Memory-Augmented AR Agents for Spatiotemporal Reasoning in Personalized Task Assistance
Aug 12, 2025Augmented Reality (AR) systems are increasingly integrating foundation models, such as Multimodal Large Language Models (MLLMs), to provide more context-aware and adaptive user experiences. This integration has led to the development of AR agents to support intelligent, goal-directed interactions in real-world environments. While current AR agents effectively support immediate tasks, they struggle with complex multi-step scenarios that require understanding and leveraging user's long-term experiences and preferences. This limitation stems from their inability to capture, retain, and reason over historical user interactions in spatiotemporal contexts. To address these challenges, we propose a conceptual framework for memory-augmented AR agents that can provide personalized task assistance by learning from and adapting to user-specific experiences over time. Our framework consists of four interconnected modules: (1) Perception Module for multimodal sensor processing, (2) Memory Module for persistent spatiotemporal experience storage, (3) Spatiotemporal Reasoning Module for synthesizing past and present contexts, and (4) Actuator Module for effective AR communication. We further present an implementation roadmap, a future evaluation strategy, a potential target application and use cases to demonstrate the practical applicability of our framework across diverse domains. We aim for this work to motivate future research toward developing more intelligent AR systems that can effectively bridge user's interaction history with adaptive, context-aware task assistance.
Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance
May 22, 2025Embodied agents empowered by large language models (LLMs) have shown strong performance in household object rearrangement tasks. However, these tasks primarily focus on single-turn interactions with simplified instructions, which do not truly reflect the challenges of providing meaningful assistance to users. To provide personalized assistance, embodied agents must understand the unique semantics that users assign to the physical world (e.g., favorite cup, breakfast routine) by leveraging prior interaction history to interpret dynamic, real-world instructions. Yet, the effectiveness of embodied agents in utilizing memory for personalized assistance remains largely underexplored. To address this gap, we present MEMENTO, a personalized embodied agent evaluation framework designed to comprehensively assess memory utilization capabilities to provide personalized assistance. Our framework consists of a two-stage memory evaluation process design that enables quantifying the impact of memory utilization on task performance. This process enables the evaluation of agents' understanding of personalized knowledge in object rearrangement tasks by focusing on its role in goal interpretation: (1) the ability to identify target objects based on personal meaning (object semantics), and (2) the ability to infer object-location configurations from consistent user patterns, such as routines (user patterns). Our experiments across various LLMs reveal significant limitations in memory utilization, with even frontier models like GPT-4o experiencing a 30.5% performance drop when required to reference multiple memories, particularly in tasks involving user patterns. These findings, along with our detailed analyses and case studies, provide valuable insights for future research in developing more effective personalized embodied agents. Project website: https://connoriginal.github.io/MEMENTO
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025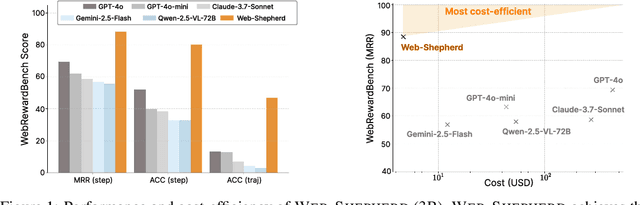


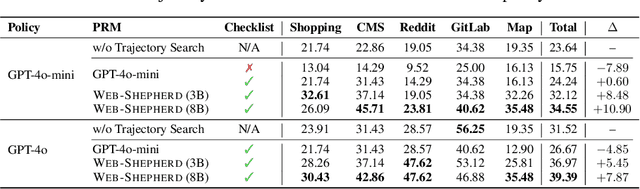
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
Rethinking Reward Model Evaluation Through the Lens of Reward Overoptimization
May 19, 2025Reward models (RMs) play a crucial role in reinforcement learning from human feedback (RLHF), aligning model behavior with human preferences. However, existing benchmarks for reward models show a weak correlation with the performance of optimized policies, suggesting that they fail to accurately assess the true capabilities of RMs. To bridge this gap, we explore several evaluation designs through the lens of reward overoptimization\textemdash a phenomenon that captures both how well the reward model aligns with human preferences and the dynamics of the learning signal it provides to the policy. The results highlight three key findings on how to construct a reliable benchmark: (i) it is important to minimize differences between chosen and rejected responses beyond correctness, (ii) evaluating reward models requires multiple comparisons across a wide range of chosen and rejected responses, and (iii) given that reward models encounter responses with diverse representations, responses should be sourced from a variety of models. However, we also observe that a extremely high correlation with degree of overoptimization leads to comparatively lower correlation with certain downstream performance. Thus, when designing a benchmark, it is desirable to use the degree of overoptimization as a useful tool, rather than the end goal.
Evaluating Robustness of Reward Models for Mathematical Reasoning
Oct 02, 2024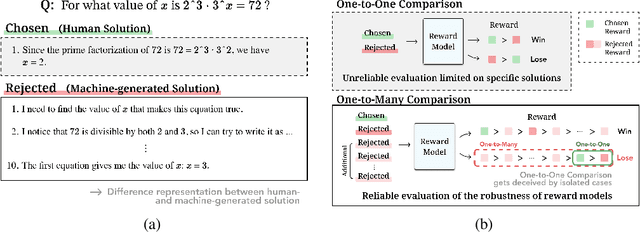
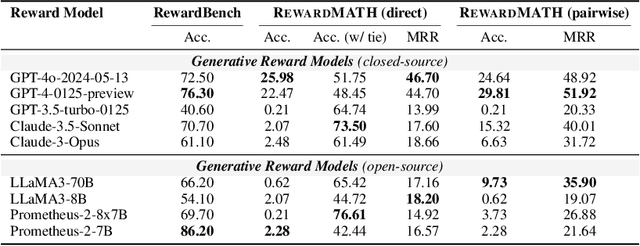
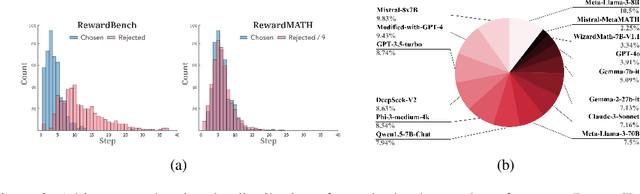
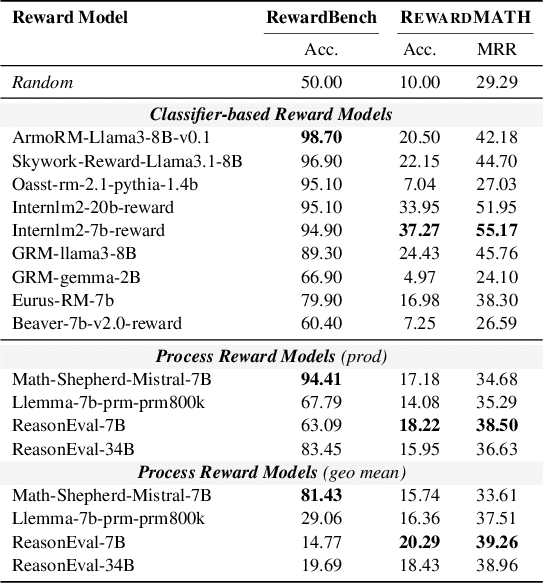
Reward models are key in reinforcement learning from human feedback (RLHF) systems, aligning the model behavior with human preferences. Particularly in the math domain, there have been plenty of studies using reward models to align policies for improving reasoning capabilities. Recently, as the importance of reward models has been emphasized, RewardBench is proposed to understand their behavior. However, we figure out that the math subset of RewardBench has different representations between chosen and rejected completions, and relies on a single comparison, which may lead to unreliable results as it only see an isolated case. Therefore, it fails to accurately present the robustness of reward models, leading to a misunderstanding of its performance and potentially resulting in reward hacking. In this work, we introduce a new design for reliable evaluation of reward models, and to validate this, we construct RewardMATH, a benchmark that effectively represents the robustness of reward models in mathematical reasoning tasks. We demonstrate that the scores on RewardMATH strongly correlate with the results of optimized policy and effectively estimate reward overoptimization, whereas the existing benchmark shows almost no correlation. The results underscore the potential of our design to enhance the reliability of evaluation, and represent the robustness of reward model. We make our code and data publicly available.
Coffee-Gym: An Environment for Evaluating and Improving Natural Language Feedback on Erroneous Code
Sep 29, 2024



This paper presents Coffee-Gym, a comprehensive RL environment for training models that provide feedback on code editing. Coffee-Gym includes two major components: (1) Coffee, a dataset containing humans' code edit traces for coding questions and machine-written feedback for editing erroneous code; (2) CoffeeEval, a reward function that faithfully reflects the helpfulness of feedback by assessing the performance of the revised code in unit tests. With them, Coffee-Gym addresses the unavailability of high-quality datasets for training feedback models with RL, and provides more accurate rewards than the SOTA reward model (i.e., GPT-4). By applying Coffee-Gym, we elicit feedback models that outperform baselines in enhancing open-source code LLMs' code editing, making them comparable with closed-source LLMs. We make the dataset and the model checkpoint publicly available.