 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC-BENCH: Evaluating Multi-Agent Collaboration under Privacy Constraints
Apr 13, 2026We are entering an era in which individuals and organizations increasingly deploy dedicated AI agents that interact and collaborate with other agents. However, the dynamics of multi-agent collaboration under privacy constraints remain poorly understood. In this work, we present $PAC\text{-}Bench$, a benchmark for systematic evaluation of multi-agent collaboration under privacy constraints. Experiments on $PAC\text{-}Bench$ show that privacy constraints substantially degrade collaboration performance and make outcomes depend more on the initiating agent than the partner. Further analysis reveals that this degradation is driven by recurring coordination breakdowns, including early-stage privacy violations, overly conservative abstraction, and privacy-induced hallucinations. Together, our findings identify privacy-aware multi-agent collaboration as a distinct and unresolved challenge that requires new coordination mechanisms beyond existing agent capabilities.
CONDESION-BENCH: Conditional Decision-Making of Large Language Models in Compositional Action Space
Apr 10, 2026Large language models have been widely explored as decision-support tools in high-stakes domains due to their contextual understanding and reasoning capabilities. However, existing decision-making benchmarks rely on two simplifying assumptions: actions are selected from a finite set of pre-defined candidates, and explicit conditions restricting action feasibility are not incorporated into the decision-making process. These assumptions fail to capture the compositional structure of real-world actions and the explicit conditions that constrain their validity. To address these limitations, we introduce CONDESION-BENCH, a benchmark designed to evaluate conditional decision-making in compositional action space. In CONDESION-BENCH, actions are defined as allocations to decision variables and are restricted by explicit conditions at the variable, contextual, and allocation levels. By employing oracle-based evaluation of both decision quality and condition adherence, we provide a more rigorous assessment of LLMs as decision-support tools.
AgenticShop: Benchmarking Agentic Product Curation for Personalized Web Shopping
Feb 12, 2026The proliferation of e-commerce has made web shopping platforms key gateways for customers navigating the vast digital marketplace. Yet this rapid expansion has led to a noisy and fragmented information environment, increasing cognitive burden as shoppers explore and purchase products online. With promising potential to alleviate this challenge, agentic systems have garnered growing attention for automating user-side tasks in web shopping. Despite significant advancements, existing benchmarks fail to comprehensively evaluate how well agentic systems can curate products in open-web settings. Specifically, they have limited coverage of shopping scenarios, focusing only on simplified single-platform lookups rather than exploratory search. Moreover, they overlook personalization in evaluation, leaving unclear whether agents can adapt to diverse user preferences in realistic shopping contexts. To address this gap, we present AgenticShop, the first benchmark for evaluating agentic systems on personalized product curation in open-web environment. Crucially, our approach features realistic shopping scenarios, diverse user profiles, and a verifiable, checklist-driven personalization evaluation framework. Through extensive experiments, we demonstrate that current agentic systems remain largely insufficient, emphasizing the need for user-side systems that effectively curate tailored products across the modern web.
Quantifying Self-Awareness of Knowledge in Large Language Models
Sep 18, 2025Hallucination prediction in large language models (LLMs) is often interpreted as a sign of self-awareness. However, we argue that such performance can arise from question-side shortcuts rather than true model-side introspection. To disentangle these factors, we propose the Approximate Question-side Effect (AQE), which quantifies the contribution of question-awareness. Our analysis across multiple datasets reveals that much of the reported success stems from exploiting superficial patterns in questions. We further introduce SCAO (Semantic Compression by Answering in One word), a method that enhances the use of model-side signals. Experiments show that SCAO achieves strong and consistent performance, particularly in settings with reduced question-side cues, highlighting its effectiveness in fostering genuine self-awareness in LLMs.
Fast and Fluent Diffusion Language Models via Convolutional Decoding and Rejective Fine-tuning
Sep 18, 2025Autoregressive (AR) language models generate text one token at a time, which limits their inference speed. Diffusion-based language models offer a promising alternative, as they can decode multiple tokens in parallel. However, we identify a key bottleneck in current diffusion LMs: the long decoding-window problem, where tokens generated far from the input context often become irrelevant or repetitive. Previous solutions like semi-autoregressive address this issue by splitting windows into blocks, but this sacrifices speed and bidirectionality, eliminating the main advantage of diffusion models. To overcome this, we propose Convolutional decoding (Conv), a normalization-based method that narrows the decoding window without hard segmentation, leading to better fluency and flexibility. Additionally, we introduce Rejecting Rule-based Fine-Tuning (R2FT), a post-hoc training scheme that better aligns tokens at positions far from context. Our methods achieve state-of-the-art results on open-ended generation benchmarks (e.g., AlpacaEval) among diffusion LM baselines, with significantly lower step size than previous works, demonstrating both speed and quality improvements.
Designing Memory-Augmented AR Agents for Spatiotemporal Reasoning in Personalized Task Assistance
Aug 12, 2025Augmented Reality (AR) systems are increasingly integrating foundation models, such as Multimodal Large Language Models (MLLMs), to provide more context-aware and adaptive user experiences. This integration has led to the development of AR agents to support intelligent, goal-directed interactions in real-world environments. While current AR agents effectively support immediate tasks, they struggle with complex multi-step scenarios that require understanding and leveraging user's long-term experiences and preferences. This limitation stems from their inability to capture, retain, and reason over historical user interactions in spatiotemporal contexts. To address these challenges, we propose a conceptual framework for memory-augmented AR agents that can provide personalized task assistance by learning from and adapting to user-specific experiences over time. Our framework consists of four interconnected modules: (1) Perception Module for multimodal sensor processing, (2) Memory Module for persistent spatiotemporal experience storage, (3) Spatiotemporal Reasoning Module for synthesizing past and present contexts, and (4) Actuator Module for effective AR communication. We further present an implementation roadmap, a future evaluation strategy, a potential target application and use cases to demonstrate the practical applicability of our framework across diverse domains. We aim for this work to motivate future research toward developing more intelligent AR systems that can effectively bridge user's interaction history with adaptive, context-aware task assistance.
ToolHaystack: Stress-Testing Tool-Augmented Language Models in Realistic Long-Term Interactions
May 29, 2025Large language models (LLMs) have demonstrated strong capabilities in using external tools to address user inquiries. However, most existing evaluations assume tool use in short contexts, offering limited insight into model behavior during realistic long-term interactions. To fill this gap, we introduce ToolHaystack, a benchmark for testing the tool use capabilities in long-term interactions. Each test instance in ToolHaystack includes multiple tasks execution contexts and realistic noise within a continuous conversation, enabling assessment of how well models maintain context and handle various disruptions. By applying this benchmark to 14 state-of-the-art LLMs, we find that while current models perform well in standard multi-turn settings, they often significantly struggle in ToolHaystack, highlighting critical gaps in their long-term robustness not revealed by previous tool benchmarks.
LLM Meets Scene Graph: Can Large Language Models Understand and Generate Scene Graphs? A Benchmark and Empirical Study
May 26, 2025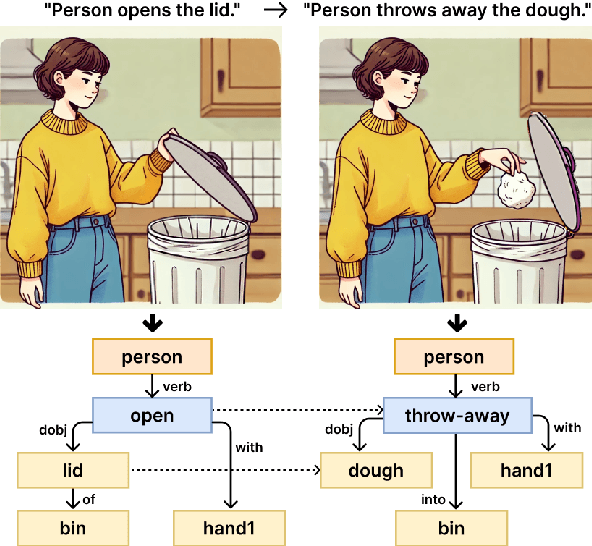

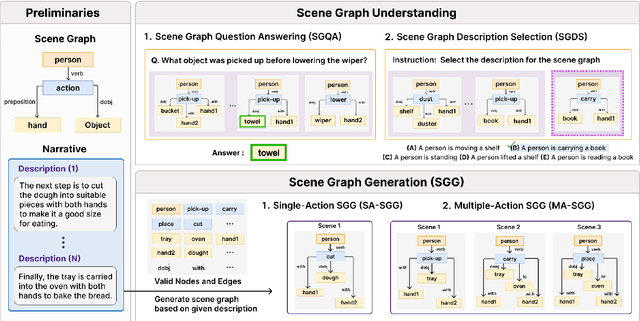

The remarkable reasoning and generalization capabilities of Large Language Models (LLMs) have paved the way for their expanding applications in embodied AI, robotics, and other real-world tasks. To effectively support these applications, grounding in spatial and temporal understanding in multimodal environments is essential. To this end, recent works have leveraged scene graphs, a structured representation that encodes entities, attributes, and their relationships in a scene. However, a comprehensive evaluation of LLMs' ability to utilize scene graphs remains limited. In this work, we introduce Text-Scene Graph (TSG) Bench, a benchmark designed to systematically assess LLMs' ability to (1) understand scene graphs and (2) generate them from textual narratives. With TSG Bench we evaluate 11 LLMs and reveal that, while models perform well on scene graph understanding, they struggle with scene graph generation, particularly for complex narratives. Our analysis indicates that these models fail to effectively decompose discrete scenes from a complex narrative, leading to a bottleneck when generating scene graphs. These findings underscore the need for improved methodologies in scene graph generation and provide valuable insights for future research. The demonstration of our benchmark is available at https://tsg-bench.netlify.app. Additionally, our code and evaluation data are publicly available at https://anonymous.4open.science/r/TSG-Bench.
Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance
May 22, 2025Embodied agents empowered by large language models (LLMs) have shown strong performance in household object rearrangement tasks. However, these tasks primarily focus on single-turn interactions with simplified instructions, which do not truly reflect the challenges of providing meaningful assistance to users. To provide personalized assistance, embodied agents must understand the unique semantics that users assign to the physical world (e.g., favorite cup, breakfast routine) by leveraging prior interaction history to interpret dynamic, real-world instructions. Yet, the effectiveness of embodied agents in utilizing memory for personalized assistance remains largely underexplored. To address this gap, we present MEMENTO, a personalized embodied agent evaluation framework designed to comprehensively assess memory utilization capabilities to provide personalized assistance. Our framework consists of a two-stage memory evaluation process design that enables quantifying the impact of memory utilization on task performance. This process enables the evaluation of agents' understanding of personalized knowledge in object rearrangement tasks by focusing on its role in goal interpretation: (1) the ability to identify target objects based on personal meaning (object semantics), and (2) the ability to infer object-location configurations from consistent user patterns, such as routines (user patterns). Our experiments across various LLMs reveal significant limitations in memory utilization, with even frontier models like GPT-4o experiencing a 30.5% performance drop when required to reference multiple memories, particularly in tasks involving user patterns. These findings, along with our detailed analyses and case studies, provide valuable insights for future research in developing more effective personalized embodied agents. Project website: https://connoriginal.github.io/MEMENTO
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025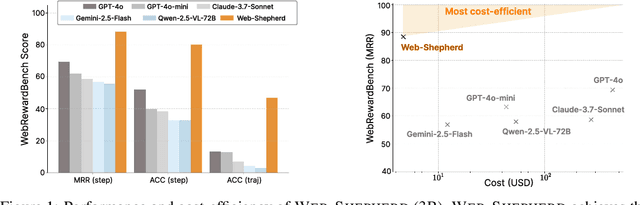


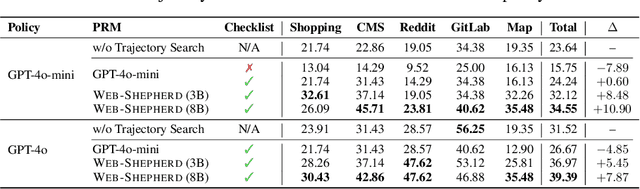
Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.