 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Forecasting of Retaining Wall Deformation: Mitigating Error Accumulation via Multi-Resolution ConvLSTM Stacking Ensemble
Mar 11, 2026This study proposes a multi-resolution Convolutional Long Short-Term Memory (ConvLSTM) ensemble framework that leverages diverse temporal input resolutions to mitigate error accumulation and improve long-horizon forecasting of retaining-structure behavior during staged excavation. An extensive database of lateral wall displacement responses was generated through PLAXIS2D simulations incorporating five-layered soil stratigraphy, two excavation depths (14 and 20 m), and stochastically varied geotechnical and structural parameters, yielding 2,000 time-series deflection profiles. Three ConvLSTM models trained at different input resolutions were integrated using a fully connected neural network meta-learner to construct the ensemble model. Validation using both numerical results and field measurements demonstrated that the ensemble approach consistently outperformed the standalone ConvLSTM models, particularly in long-term multi-step prediction, exhibiting reduced error propagation and improved generalization. These findings underscore the potential of multi-resolution ensemble strategies that jointly exploit diverse temporal input scales to enhance predictive stability and accuracy in AI-driven geotechnical forecasting.
MEGA-GUI: Multi-stage Enhanced Grounding Agents for GUI Elements
Nov 17, 2025Graphical User Interface (GUI) grounding - the task of mapping natural language instructions to screen coordinates - is essential for autonomous agents and accessibility technologies. Existing systems rely on monolithic models or one-shot pipelines that lack modularity and fail under visual clutter and ambiguous instructions. We introduce MEGA-GUI, a multi-stage framework that separates grounding into coarse Region-of-Interest (ROI) selection and fine-grained element grounding, orchestrated by specialized vision-language agents. MEGA-GUI features a bidirectional ROI zoom algorithm that mitigates spatial dilution and a context-aware rewriting agent that reduces semantic ambiguity. Our analysis reveals complementary strengths and weaknesses across vision-language models at different visual scales, and we show that leveraging this modular structure achieves consistently higher accuracy than monolithic approaches. On the visually dense ScreenSpot-Pro benchmark, MEGA-GUI attains 73.18% accuracy, and on the semantically complex OSWorld-G benchmark it reaches 68.63%, surpassing previously reported results. Code and the Grounding Benchmark Toolkit (GBT) are available at https://github.com/samsungsds-research-papers/mega-gui.
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
Jul 15, 2025This technical report introduces EXAONE 4.0, which integrates a Non-reasoning mode and a Reasoning mode to achieve both the excellent usability of EXAONE 3.5 and the advanced reasoning abilities of EXAONE Deep. To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended to support Spanish in addition to English and Korean. The EXAONE 4.0 model series consists of two sizes: a mid-size 32B model optimized for high performance, and a small-size 1.2B model designed for on-device applications. The EXAONE 4.0 demonstrates superior performance compared to open-weight models in its class and remains competitive even against frontier-class models. The models are publicly available for research purposes and can be easily downloaded via https://huggingface.co/LGAI-EXAONE.
Hierarchical Retrieval with Evidence Curation for Open-Domain Financial Question Answering on Standardized Documents
May 26, 2025


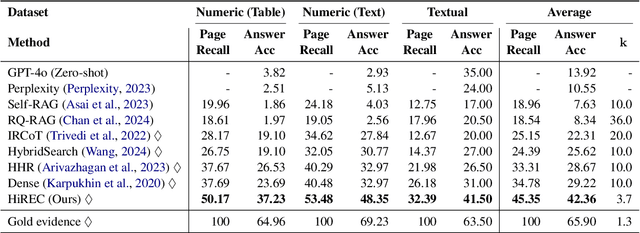
Retrieval-augmented generation (RAG) based large language models (LLMs) are widely used in finance for their excellent performance on knowledge-intensive tasks. However, standardized documents (e.g., SEC filing) share similar formats such as repetitive boilerplate texts, and similar table structures. This similarity forces traditional RAG methods to misidentify near-duplicate text, leading to duplicate retrieval that undermines accuracy and completeness. To address these issues, we propose the Hierarchical Retrieval with Evidence Curation (HiREC) framework. Our approach first performs hierarchical retrieval to reduce confusion among similar texts. It first retrieve related documents and then selects the most relevant passages from the documents. The evidence curation process removes irrelevant passages. When necessary, it automatically generates complementary queries to collect missing information. To evaluate our approach, we construct and release a Large-scale Open-domain Financial (LOFin) question answering benchmark that includes 145,897 SEC documents and 1,595 question-answer pairs. Our code and data are available at https://github.com/deep-over/LOFin-bench-HiREC.
PyTopo3D: A Python Framework for 3D SIMP-based Topology Optimization
Apr 08, 2025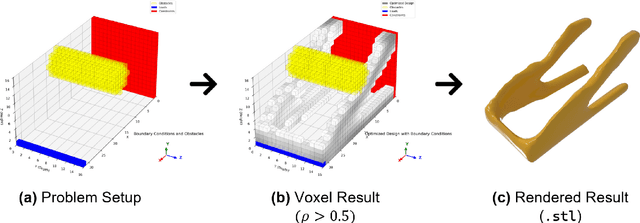
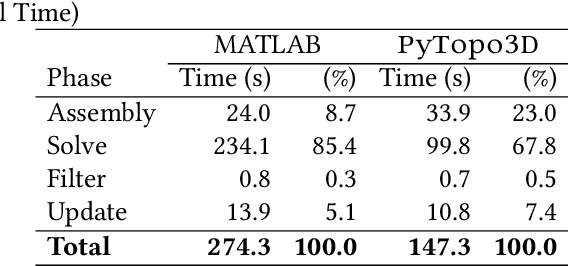
Three-dimensional topology optimization (TO) is a powerful technique in engineering design, but readily usable, open-source implementations remain limited within the popular Python scientific environment. This paper introduces PyTopo3D, a software framework developed to address this gap. PyTopo3D provides a feature-rich tool for 3D TO by implementing the well-established Solid Isotropic Material with Penalization (SIMP) method and an Optimality Criteria (OC) update scheme, adapted and significantly enhanced from the efficient MATLAB code by Liu and Tovar (2014). While building on proven methodology, PyTopo3D's primary contribution is its integration and extension within Python, leveraging sparse matrix operations, optional parallel solvers, and accelerated KD-Tree sensitivity filtering for performance. Crucially, it incorporates functionalities vital for practical engineering workflows, including the direct import of complex design domains and non-design obstacles via STL files, integrated 3D visualization of the optimization process, and direct STL export of optimized geometries for manufacturing or further analysis. PyTopo3D is presented as an accessible, performance-aware tool and citable reference designed to empower engineers, students, and researchers to more easily utilize 3D TO within their existing Python-based workflows.
Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation
Oct 17, 2024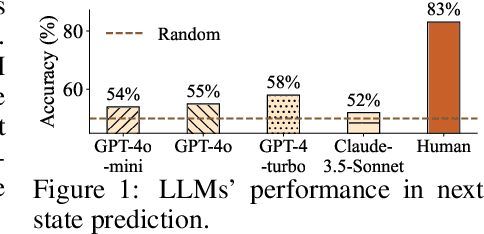
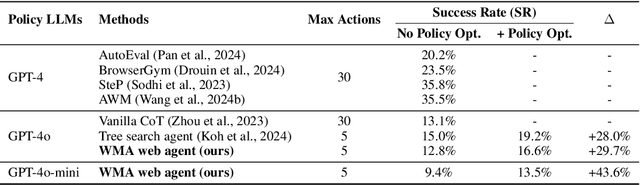
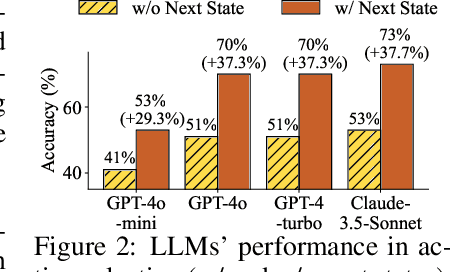

Large language models (LLMs) have recently gained much attention in building autonomous agents. However, the performance of current LLM-based web agents in long-horizon tasks is far from optimal, often yielding errors such as repeatedly buying a non-refundable flight ticket. By contrast, humans can avoid such an irreversible mistake, as we have an awareness of the potential outcomes (e.g., losing money) of our actions, also known as the "world model". Motivated by this, our study first starts with preliminary analyses, confirming the absence of world models in current LLMs (e.g., GPT-4o, Claude-3.5-Sonnet, etc.). Then, we present a World-model-augmented (WMA) web agent, which simulates the outcomes of its actions for better decision-making. To overcome the challenges in training LLMs as world models predicting next observations, such as repeated elements across observations and long HTML inputs, we propose a transition-focused observation abstraction, where the prediction objectives are free-form natural language descriptions exclusively highlighting important state differences between time steps. Experiments on WebArena and Mind2Web show that our world models improve agents' policy selection without training and demonstrate our agents' cost- and time-efficiency compared to recent tree-search-based agents.
CAAP: Context-Aware Action Planning Prompting to Solve Computer Tasks with Front-End UI Only
Jun 11, 2024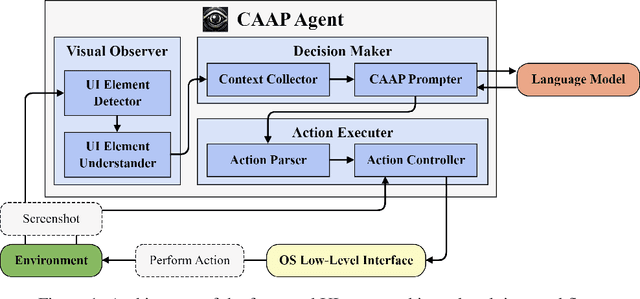



Software robots have long been deployed in Robotic Process Automation (RPA) to automate mundane and repetitive computer tasks. The advent of Large Language Models (LLMs) with advanced reasoning capabilities has set the stage for these agents to now undertake more complex and even previously unseen tasks. However, the LLM-based automation techniques in recent literature frequently rely on HTML source codes for input, limiting their application to web environments. Moreover, the information contained in HTML codes is often inaccurate or incomplete, making the agent less reliable for practical applications. We propose an LLM-based agent that functions solely on the basis of screenshots for recognizing environments, while leveraging in-context learning to eliminate the need for collecting large datasets of human demonstration. Our strategy, named Context-Aware Action Planning (CAAP) prompting encourages the agent to meticulously review the context in various angles. Through our proposed methodology, we achieve a success rate of 94.4% on 67~types of MiniWoB++ problems, utilizing only 1.48~demonstrations per problem type. Our method offers the potential for broader applications, especially for tasks that require inter-application coordination on computers or smartphones, showcasing a significant advancement in the field of automation agents. Codes and models are accessible at https://github.com/caap-agent/caap-agent.
Deep Generative Design for Mass Production
Mar 16, 2024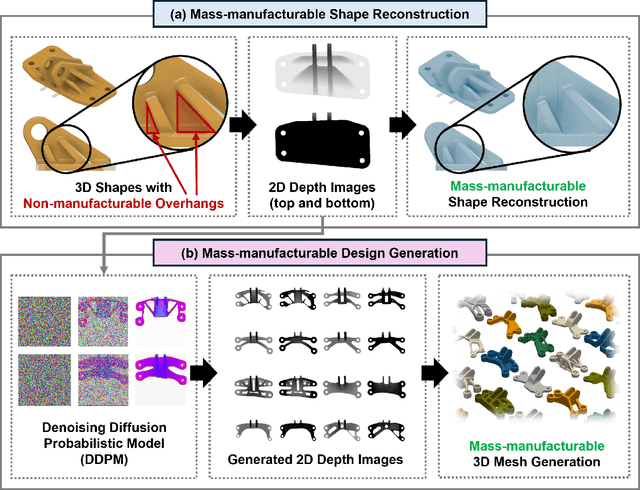
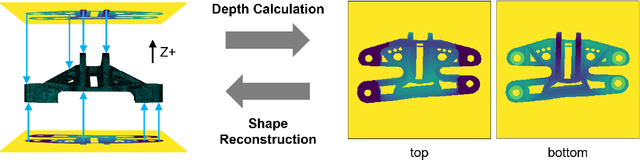
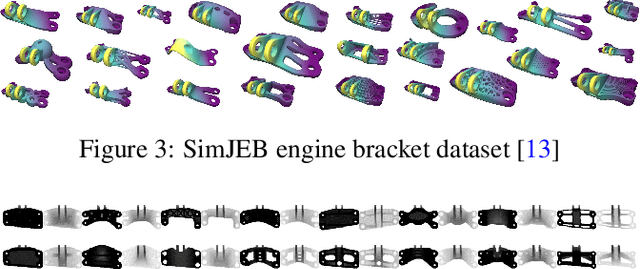
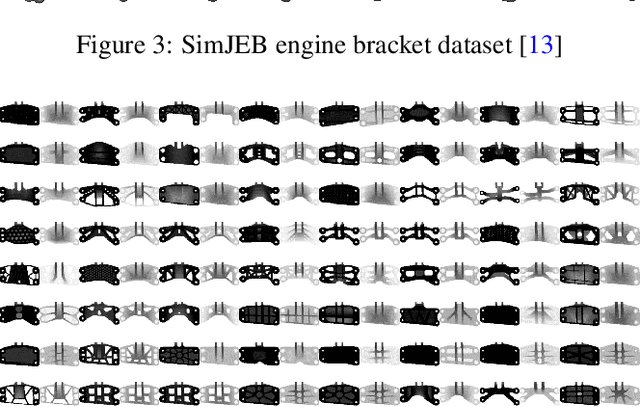
Generative Design (GD) has evolved as a transformative design approach, employing advanced algorithms and AI to create diverse and innovative solutions beyond traditional constraints. Despite its success, GD faces significant challenges regarding the manufacturability of complex designs, often necessitating extensive manual modifications due to limitations in standard manufacturing processes and the reliance on additive manufacturing, which is not ideal for mass production. Our research introduces an innovative framework addressing these manufacturability concerns by integrating constraints pertinent to die casting and injection molding into GD, through the utilization of 2D depth images. This method simplifies intricate 3D geometries into manufacturable profiles, removing unfeasible features such as non-manufacturable overhangs and allowing for the direct consideration of essential manufacturing aspects like thickness and rib design. Consequently, designs previously unsuitable for mass production are transformed into viable solutions. We further enhance this approach by adopting an advanced 2D generative model, which offer a more efficient alternative to traditional 3D shape generation methods. Our results substantiate the efficacy of this framework, demonstrating the production of innovative, and, importantly, manufacturable designs. This shift towards integrating practical manufacturing considerations into GD represents a pivotal advancement, transitioning from purely inspirational concepts to actionable, production-ready solutions. Our findings underscore usefulness and potential of GD for broader industry adoption, marking a significant step forward in aligning GD with the demands of manufacturing challenges.
Deep Generative Model-based Synthesis of Four-bar Linkage Mechanisms with Target Conditions
Feb 22, 2024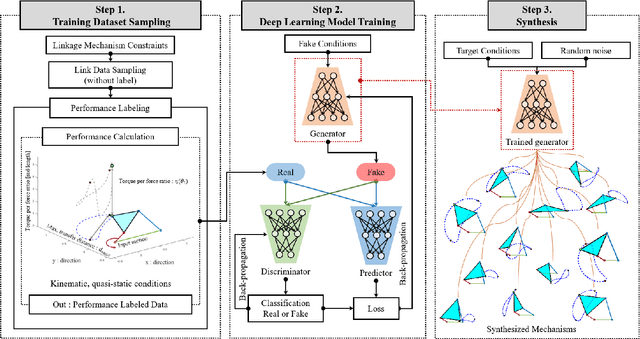

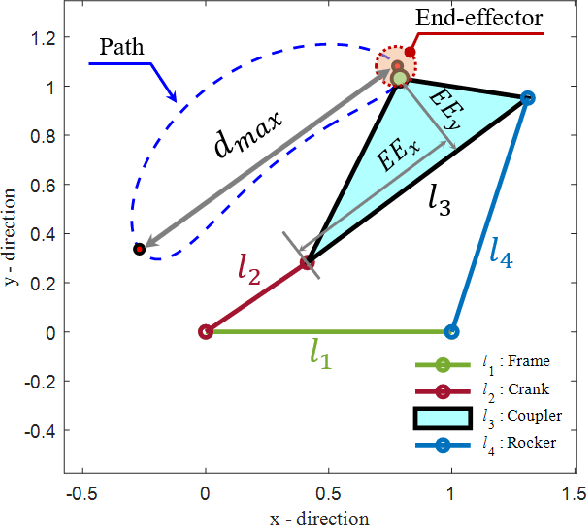

Mechanisms are essential components designed to perform specific tasks in various mechanical systems. However, designing a mechanism that satisfies certain kinematic or quasi-static requirements is a challenging task. The kinematic requirements may include the workspace of a mechanism, while the quasi-static requirements of a mechanism may include its torque transmission, which refers to the ability of the mechanism to transfer power and torque effectively. In this paper, we propose a deep learning-based generative model for generating multiple crank-rocker four-bar linkage mechanisms that satisfy both the kinematic and quasi-static requirements aforementioned. The proposed model is based on a conditional generative adversarial network (cGAN) with modifications for mechanism synthesis, which is trained to learn the relationship between the requirements of a mechanism with respect to linkage lengths. The results demonstrate that the proposed model successfully generates multiple distinct mechanisms that satisfy specific kinematic and quasi-static requirements. To evaluate the novelty of our approach, we provide a comparison of the samples synthesized by the proposed cGAN, traditional cVAE and NSGA-II. Our approach has several advantages over traditional design methods. It enables designers to efficiently generate multiple diverse and feasible design candidates while exploring a large design space. Also, the proposed model considers both the kinematic and quasi-static requirements, which can lead to more efficient and effective mechanisms for real-world use, making it a promising tool for linkage mechanism design.
X-SNS: Cross-Lingual Transfer Prediction through Sub-Network Similarity
Oct 26, 2023



Cross-lingual transfer (XLT) is an emergent ability of multilingual language models that preserves their performance on a task to a significant extent when evaluated in languages that were not included in the fine-tuning process. While English, due to its widespread usage, is typically regarded as the primary language for model adaption in various tasks, recent studies have revealed that the efficacy of XLT can be amplified by selecting the most appropriate source languages based on specific conditions. In this work, we propose the utilization of sub-network similarity between two languages as a proxy for predicting the compatibility of the languages in the context of XLT. Our approach is model-oriented, better reflecting the inner workings of foundation models. In addition, it requires only a moderate amount of raw text from candidate languages, distinguishing it from the majority of previous methods that rely on external resources. In experiments, we demonstrate that our method is more effective than baselines across diverse tasks. Specifically, it shows proficiency in ranking candidates for zero-shot XLT, achieving an improvement of 4.6% on average in terms of NDCG@3. We also provide extensive analyses that confirm the utility of sub-networks for XLT prediction.