 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Transmission for LLM Tiers: Optimizing Cost and Accuracy in Large Language Models
May 29, 2025LLM providers typically offer multiple LLM tiers, varying in performance and price. As NLP tasks become more complex and modularized, selecting the suitable LLM tier for each subtask is a key challenge to balance between cost and performance. To address the problem, we introduce LLM Automatic Transmission (LLM-AT) framework that automatically selects LLM tiers without training. LLM-AT consists of Starter, Generator, and Judge. The starter selects the initial LLM tier expected to solve the given question, the generator produces a response using the LLM of the selected tier, and the judge evaluates the validity of the response. If the response is invalid, LLM-AT iteratively upgrades to a higher-tier model, generates a new response, and re-evaluates until a valid response is obtained. Additionally, we propose accuracy estimator, which enables the suitable initial LLM tier selection without training. Given an input question, accuracy estimator estimates the expected accuracy of each LLM tier by computing the valid response rate across top-k similar queries from past inference records. Experiments demonstrate that LLM-AT achieves superior performance while reducing costs, making it a practical solution for real-world applications.
Hierarchical Retrieval with Evidence Curation for Open-Domain Financial Question Answering on Standardized Documents
May 26, 2025


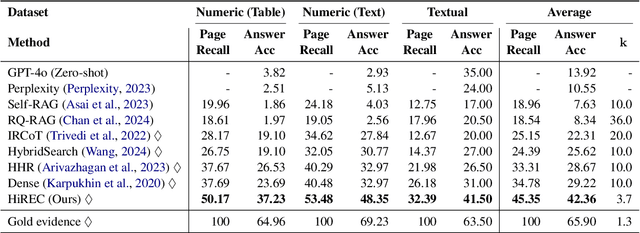
Retrieval-augmented generation (RAG) based large language models (LLMs) are widely used in finance for their excellent performance on knowledge-intensive tasks. However, standardized documents (e.g., SEC filing) share similar formats such as repetitive boilerplate texts, and similar table structures. This similarity forces traditional RAG methods to misidentify near-duplicate text, leading to duplicate retrieval that undermines accuracy and completeness. To address these issues, we propose the Hierarchical Retrieval with Evidence Curation (HiREC) framework. Our approach first performs hierarchical retrieval to reduce confusion among similar texts. It first retrieve related documents and then selects the most relevant passages from the documents. The evidence curation process removes irrelevant passages. When necessary, it automatically generates complementary queries to collect missing information. To evaluate our approach, we construct and release a Large-scale Open-domain Financial (LOFin) question answering benchmark that includes 145,897 SEC documents and 1,595 question-answer pairs. Our code and data are available at https://github.com/deep-over/LOFin-bench-HiREC.
A Single Model Ensemble Framework for Neural Machine Translation using Pivot Translation
Feb 03, 2025Despite the significant advances in neural machine translation, performance remains subpar for low-resource language pairs. Ensembling multiple systems is a widely adopted technique to enhance performance, often accomplished by combining probability distributions. However, the previous approaches face the challenge of high computational costs for training multiple models. Furthermore, for black-box models, averaging token-level probabilities at each decoding step is not feasible. To address the problems of multi-model ensemble methods, we present a pivot-based single model ensemble. The proposed strategy consists of two steps: pivot-based candidate generation and post-hoc aggregation. In the first step, we generate candidates through pivot translation. This can be achieved with only a single model and facilitates knowledge transfer from high-resource pivot languages, resulting in candidates that are not only diverse but also more accurate. Next, in the aggregation step, we select k high-quality candidates from the generated candidates and merge them to generate a final translation that outperforms the existing candidates. Our experimental results show that our method produces translations of superior quality by leveraging candidates from pivot translation to capture the subtle nuances of the source sentence.
Improving Detail in Pluralistic Image Inpainting with Feature Dequantization
Dec 02, 2024
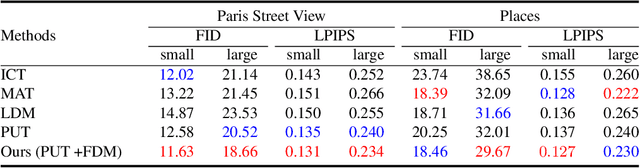
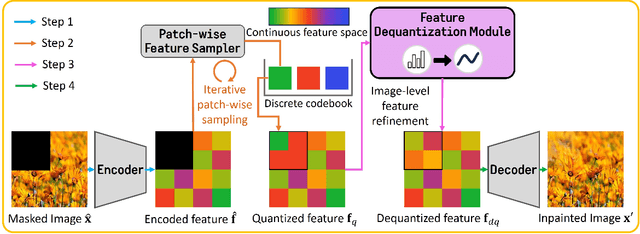
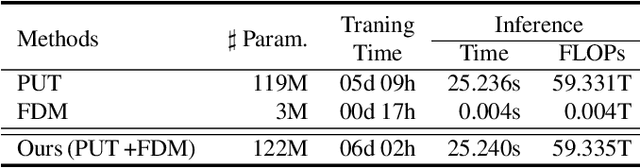
Pluralistic Image Inpainting (PII) offers multiple plausible solutions for restoring missing parts of images and has been successfully applied to various applications including image editing and object removal. Recently, VQGAN-based methods have been proposed and have shown that they significantly improve the structural integrity in the generated images. Nevertheless, the state-of-the-art VQGAN-based model PUT faces a critical challenge: degradation of detail quality in output images due to feature quantization. Feature quantization restricts the latent space and causes information loss, which negatively affects the detail quality essential for image inpainting. To tackle the problem, we propose the FDM (Feature Dequantization Module) specifically designed to restore the detail quality of images by compensating for the information loss. Furthermore, we develop an efficient training method for FDM which drastically reduces training costs. We empirically demonstrate that our method significantly enhances the detail quality of the generated images with negligible training and inference overheads.
Improving Domain-Specific ASR with LLM-Generated Contextual Descriptions
Jul 25, 2024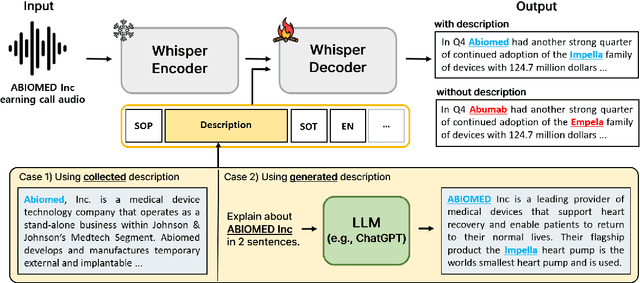
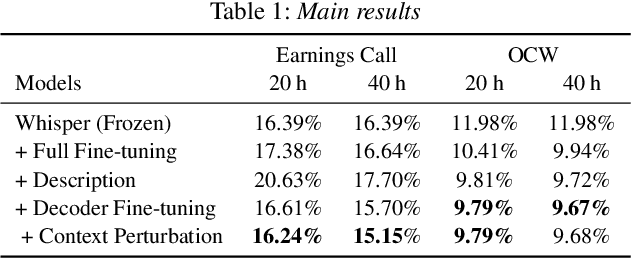


End-to-end automatic speech recognition (E2E ASR) systems have significantly improved speech recognition through training on extensive datasets. Despite these advancements, they still struggle to accurately recognize domain specific words, such as proper nouns and technical terminologies. To address this problem, we propose a method to utilize the state-of-the-art Whisper without modifying its architecture, preserving its generalization performance while enabling it to leverage descriptions effectively. Moreover, we propose two additional training techniques to improve the domain specific ASR: decoder fine-tuning, and context perturbation. We also propose a method to use a Large Language Model (LLM) to generate descriptions with simple metadata, when descriptions are unavailable. Our experiments demonstrate that proposed methods notably enhance domain-specific ASR accuracy on real-life datasets, with LLM-generated descriptions outperforming human-crafted ones in effectiveness.
Exploring the Impact of Corpus Diversity on Financial Pretrained Language Models
Oct 20, 2023Over the past few years, various domain-specific pretrained language models (PLMs) have been proposed and have outperformed general-domain PLMs in specialized areas such as biomedical, scientific, and clinical domains. In addition, financial PLMs have been studied because of the high economic impact of financial data analysis. However, we found that financial PLMs were not pretrained on sufficiently diverse financial data. This lack of diverse training data leads to a subpar generalization performance, resulting in general-purpose PLMs, including BERT, often outperforming financial PLMs on many downstream tasks. To address this issue, we collected a broad range of financial corpus and trained the Financial Language Model (FiLM) on these diverse datasets. Our experimental results confirm that FiLM outperforms not only existing financial PLMs but also general domain PLMs. Furthermore, we provide empirical evidence that this improvement can be achieved even for unseen corpus groups.
Enhancing Low-resource Fine-grained Named Entity Recognition by Leveraging Coarse-grained Datasets
Oct 18, 2023



Named Entity Recognition (NER) frequently suffers from the problem of insufficient labeled data, particularly in fine-grained NER scenarios. Although $K$-shot learning techniques can be applied, their performance tends to saturate when the number of annotations exceeds several tens of labels. To overcome this problem, we utilize existing coarse-grained datasets that offer a large number of annotations. A straightforward approach to address this problem is pre-finetuning, which employs coarse-grained data for representation learning. However, it cannot directly utilize the relationships between fine-grained and coarse-grained entities, although a fine-grained entity type is likely to be a subcategory of a coarse-grained entity type. We propose a fine-grained NER model with a Fine-to-Coarse(F2C) mapping matrix to leverage the hierarchical structure explicitly. In addition, we present an inconsistency filtering method to eliminate coarse-grained entities that are inconsistent with fine-grained entity types to avoid performance degradation. Our experimental results show that our method outperforms both $K$-shot learning and supervised learning methods when dealing with a small number of fine-grained annotations.
Data Augmentation for Neural Machine Translation using Generative Language Model
Jul 26, 2023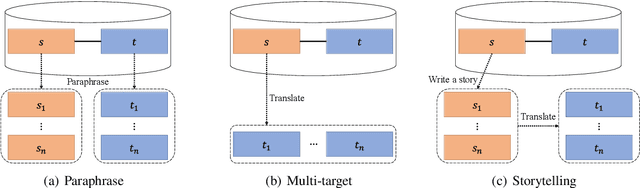



Despite the rapid growth in model architecture, the scarcity of large parallel corpora remains the main bottleneck in Neural Machine Translation. Data augmentation is a technique that enhances the performance of data-hungry models by generating synthetic data instead of collecting new ones. We explore prompt-based data augmentation approaches that leverage large-scale language models such as ChatGPT. To create a synthetic parallel corpus, we compare 3 methods using different prompts. We employ two assessment metrics to measure the diversity of the generated synthetic data. This approach requires no further model training cost, which is mandatory in other augmentation methods like back-translation. The proposed method improves the unaugmented baseline by 0.68 BLEU score.
Dual Supervision Framework for Relation Extraction with Distant Supervision and Human Annotation
Nov 24, 2020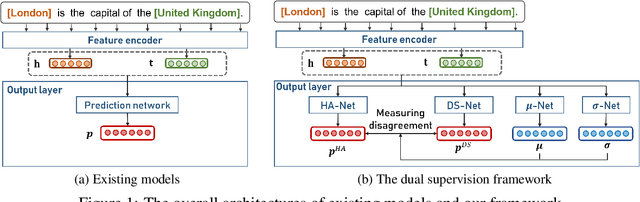
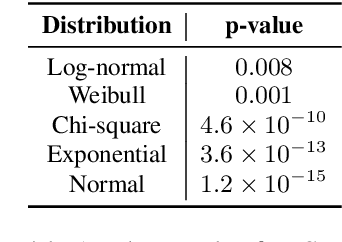
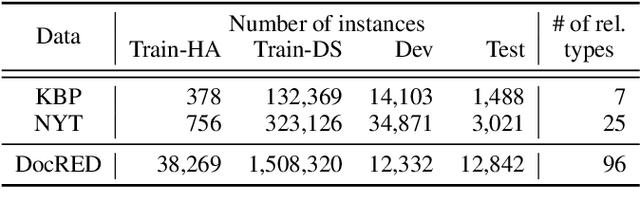
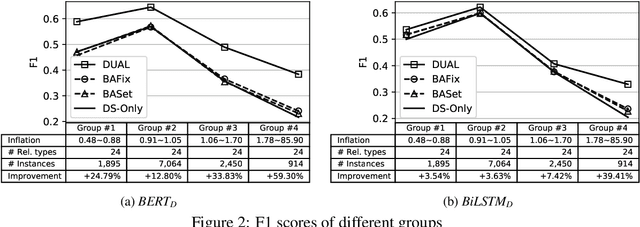
Relation extraction (RE) has been extensively studied due to its importance in real-world applications such as knowledge base construction and question answering. Most of the existing works train the models on either distantly supervised data or human-annotated data. To take advantage of the high accuracy of human annotation and the cheap cost of distant supervision, we propose the dual supervision framework which effectively utilizes both types of data. However, simply combining the two types of data to train a RE model may decrease the prediction accuracy since distant supervision has labeling bias. We employ two separate prediction networks HA-Net and DS-Net to predict the labels by human annotation and distant supervision, respectively, to prevent the degradation of accuracy by the incorrect labeling of distant supervision. Furthermore, we propose an additional loss term called disagreement penalty to enable HA-Net to learn from distantly supervised labels. In addition, we exploit additional networks to adaptively assess the labeling bias by considering contextual information. Our performance study on sentence-level and document-level REs confirms the effectiveness of the dual supervision framework.