 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Single Model Ensemble Framework for Neural Machine Translation using Pivot Translation
Feb 03, 2025Despite the significant advances in neural machine translation, performance remains subpar for low-resource language pairs. Ensembling multiple systems is a widely adopted technique to enhance performance, often accomplished by combining probability distributions. However, the previous approaches face the challenge of high computational costs for training multiple models. Furthermore, for black-box models, averaging token-level probabilities at each decoding step is not feasible. To address the problems of multi-model ensemble methods, we present a pivot-based single model ensemble. The proposed strategy consists of two steps: pivot-based candidate generation and post-hoc aggregation. In the first step, we generate candidates through pivot translation. This can be achieved with only a single model and facilitates knowledge transfer from high-resource pivot languages, resulting in candidates that are not only diverse but also more accurate. Next, in the aggregation step, we select k high-quality candidates from the generated candidates and merge them to generate a final translation that outperforms the existing candidates. Our experimental results show that our method produces translations of superior quality by leveraging candidates from pivot translation to capture the subtle nuances of the source sentence.
Enhancing Low-resource Fine-grained Named Entity Recognition by Leveraging Coarse-grained Datasets
Oct 18, 2023



Named Entity Recognition (NER) frequently suffers from the problem of insufficient labeled data, particularly in fine-grained NER scenarios. Although $K$-shot learning techniques can be applied, their performance tends to saturate when the number of annotations exceeds several tens of labels. To overcome this problem, we utilize existing coarse-grained datasets that offer a large number of annotations. A straightforward approach to address this problem is pre-finetuning, which employs coarse-grained data for representation learning. However, it cannot directly utilize the relationships between fine-grained and coarse-grained entities, although a fine-grained entity type is likely to be a subcategory of a coarse-grained entity type. We propose a fine-grained NER model with a Fine-to-Coarse(F2C) mapping matrix to leverage the hierarchical structure explicitly. In addition, we present an inconsistency filtering method to eliminate coarse-grained entities that are inconsistent with fine-grained entity types to avoid performance degradation. Our experimental results show that our method outperforms both $K$-shot learning and supervised learning methods when dealing with a small number of fine-grained annotations.
Data Augmentation for Neural Machine Translation using Generative Language Model
Jul 26, 2023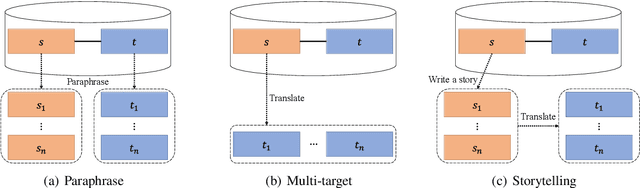



Despite the rapid growth in model architecture, the scarcity of large parallel corpora remains the main bottleneck in Neural Machine Translation. Data augmentation is a technique that enhances the performance of data-hungry models by generating synthetic data instead of collecting new ones. We explore prompt-based data augmentation approaches that leverage large-scale language models such as ChatGPT. To create a synthetic parallel corpus, we compare 3 methods using different prompts. We employ two assessment metrics to measure the diversity of the generated synthetic data. This approach requires no further model training cost, which is mandatory in other augmentation methods like back-translation. The proposed method improves the unaugmented baseline by 0.68 BLEU score.